Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClient-Driven Content Extraction Associated with Table
Paper and Code
Apr 06, 2013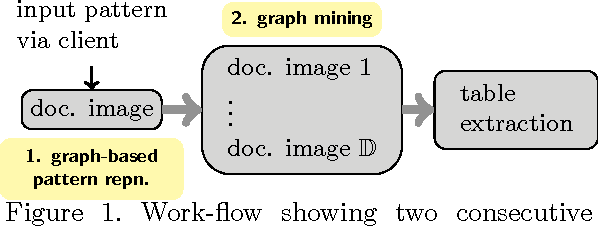
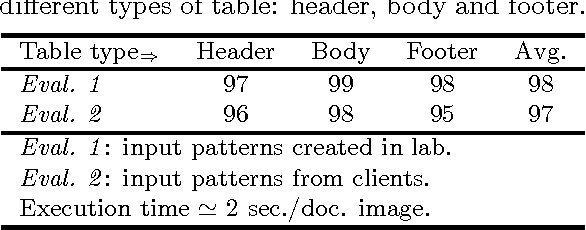
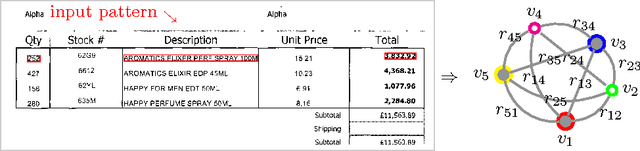

The goal of the project is to extract content within table in document images based on learnt patterns. Real-world users i.e., clients first provide a set of key fields within the table which they think are important. These are first used to represent the graph where nodes are labelled with semantics including other features and edges are attributed with relations. Attributed relational graph (ARG) is then employed to mine similar graphs from a document image. Each mined graph will represent an item within the table, and hence a set of such graphs will compose a table. We have validated the concept by using a real-world industrial problem.
* Machine Vision Applications (2013)
View paper on