 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Planning Considering Time-Varying and Uncertain Movement Speed in Multi-Robot Automatic Warehouses: Problem Formulation and Algorithm
Dec 01, 2022



Path planning in the multi-robot system refers to calculating a set of actions for each robot, which will move each robot to its goal without conflicting with other robots. Lately, the research topic has received significant attention for its extensive applications, such as airport ground, drone swarms, and automatic warehouses. Despite these available research results, most of the existing investigations are concerned with the cases of robots with a fixed movement speed without considering uncertainty. Therefore, in this work, we study the problem of path-planning in the multi-robot automatic warehouse context, which considers the time-varying and uncertain robots' movement speed. Specifically, the path-planning module searches a path with as few conflicts as possible for a single agent by calculating traffic cost based on customarily distributed conflict probability and combining it with the classic A* algorithm. However, this probability-based method cannot eliminate all conflicts, and speed's uncertainty will constantly cause new conflicts. As a supplement, we propose the other two modules. The conflict detection and re-planning module chooses objects requiring re-planning paths from the agents involved in different types of conflicts periodically by our designed rules. Also, at each step, the scheduling module fills up the agent's preserved queue and decides who has a higher priority when the same element is assigned to two agents simultaneously. Finally, we compare the proposed algorithm with other algorithms from academia and industry, and the results show that the proposed method is validated as the best performance.
Adaptive Task Planning for Large-Scale Robotized Warehouses
Apr 24, 2022
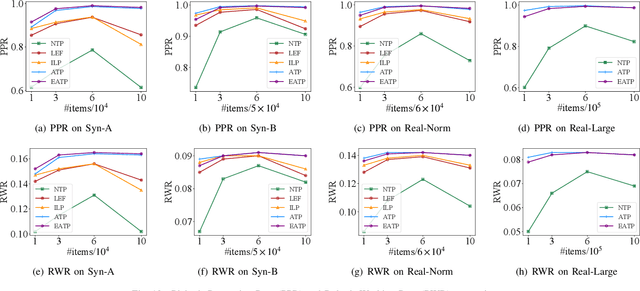
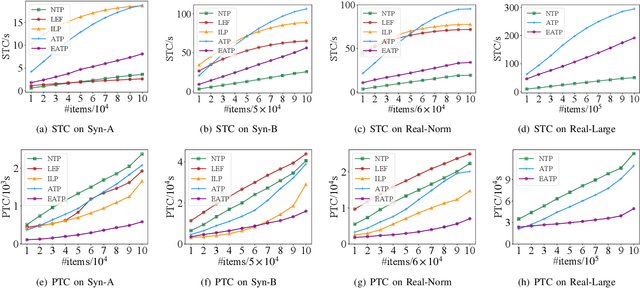
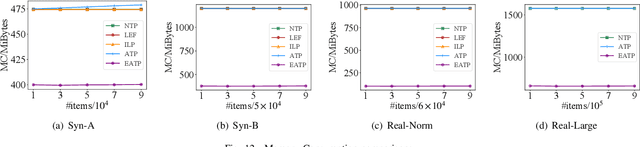
Robotized warehouses are deployed to automatically distribute millions of items brought by the massive logistic orders from e-commerce. A key to automated item distribution is to plan paths for robots, also known as task planning, where each task is to deliver racks with items to pickers for processing and then return the rack back. Prior solutions are unfit for large-scale robotized warehouses due to the inflexibility to time-varying item arrivals and the low efficiency for high throughput. In this paper, we propose a new task planning problem called TPRW, which aims to minimize the end-to-end makespan that incorporates the entire item distribution pipeline, known as a fulfilment cycle. Direct extensions from state-of-the-art path finding methods are ineffective to solve the TPRW problem because they fail to adapt to the bottleneck variations of fulfillment cycles. In response, we propose Efficient Adaptive Task Planning, a framework for large-scale robotized warehouses with time-varying item arrivals. It adaptively selects racks to fulfill at each timestamp via reinforcement learning, accounting for the time-varying bottleneck of the fulfillment cycles. Then it finds paths for robots to transport the selected racks. The framework adopts a series of efficient optimizations on both time and memory to handle large-scale item throughput. Evaluations on both synthesized and real data show an improvement of $37.1\%$ in effectiveness and $75.5\%$ in efficiency over the state-of-the-arts.
Multi-Agent Path Finding with Prioritized Communication Learning
Feb 10, 2022Multi-agent pathfinding (MAPF) has been widely used to solve large-scale real-world problems, e.g., automation warehouses. The learning-based, fully decentralized framework has been introduced to alleviate real-time problems and simultaneously pursue optimal planning policy. However, existing methods might generate significantly more vertex conflicts (or collisions), which lead to a low success rate or more makespan. In this paper, we propose a PrIoritized COmmunication learning method (PICO), which incorporates the \textit{implicit} planning priorities into the communication topology within the decentralized multi-agent reinforcement learning framework. Assembling with the classic coupled planners, the implicit priority learning module can be utilized to form the dynamic communication topology, which also builds an effective collision-avoiding mechanism. PICO performs significantly better in large-scale MAPF tasks in success rates and collision rates than state-of-the-art learning-based planners.