 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoSound: Benchmarking Sound Understanding in Egocentric Videos
Feb 15, 2026Multimodal Large Language Models (MLLMs) have recently achieved remarkable progress in vision-language understanding. Yet, human perception is inherently multisensory, integrating sight, sound, and motion to reason about the world. Among these modalities, sound provides indispensable cues about spatial layout, off-screen events, and causal interactions, particularly in egocentric settings where auditory and visual signals are tightly coupled. To this end, we introduce EgoSound, the first benchmark designed to systematically evaluate egocentric sound understanding in MLLMs. EgoSound unifies data from Ego4D and EgoBlind, encompassing both sighted and sound-dependent experiences. It defines a seven-task taxonomy spanning intrinsic sound perception, spatial localization, causal inference, and cross-modal reasoning. Constructed through a multi-stage auto-generative pipeline, EgoSound contains 7315 validated QA pairs across 900 videos. Comprehensive experiments on nine state-of-the-art MLLMs reveal that current models exhibit emerging auditory reasoning abilities but remain limited in fine-grained spatial and causal understanding. EgoSound establishes a challenging foundation for advancing multisensory egocentric intelligence, bridging the gap between seeing and truly hearing the world.
VidSplice: Towards Coherent Video Inpainting via Explicit Spaced Frame Guidance
Oct 24, 2025Recent video inpainting methods often employ image-to-video (I2V) priors to model temporal consistency across masked frames. While effective in moderate cases, these methods struggle under severe content degradation and tend to overlook spatiotemporal stability, resulting in insufficient control over the latter parts of the video. To address these limitations, we decouple video inpainting into two sub-tasks: multi-frame consistent image inpainting and masked area motion propagation. We propose VidSplice, a novel framework that introduces spaced-frame priors to guide the inpainting process with spatiotemporal cues. To enhance spatial coherence, we design a CoSpliced Module to perform first-frame propagation strategy that diffuses the initial frame content into subsequent reference frames through a splicing mechanism. Additionally, we introduce a delicate context controller module that encodes coherent priors after frame duplication and injects the spliced video into the I2V generative backbone, effectively constraining content distortion during generation. Extensive evaluations demonstrate that VidSplice achieves competitive performance across diverse video inpainting scenarios. Moreover, its design significantly improves both foreground alignment and motion stability, outperforming existing approaches.
Online Dense Point Tracking with Streaming Memory
Mar 09, 2025
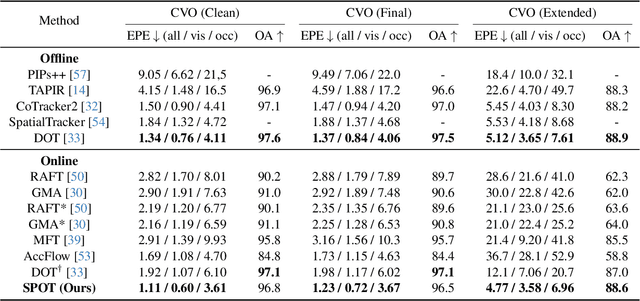
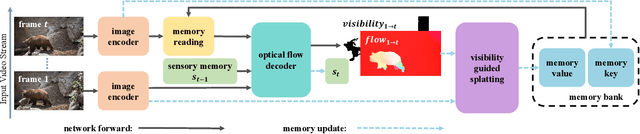
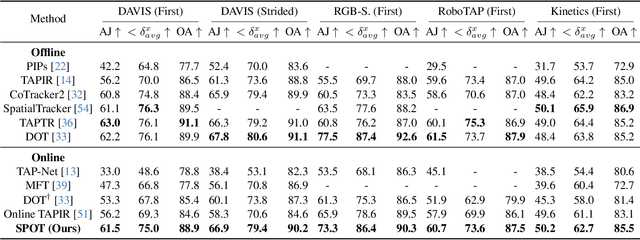
Dense point tracking is a challenging task requiring the continuous tracking of every point in the initial frame throughout a substantial portion of a video, even in the presence of occlusions. Traditional methods use optical flow models to directly estimate long-range motion, but they often suffer from appearance drifting without considering temporal consistency. Recent point tracking algorithms usually depend on sliding windows for indirect information propagation from the first frame to the current one, which is slow and less effective for long-range tracking. To account for temporal consistency and enable efficient information propagation, we present a lightweight and fast model with \textbf{S}treaming memory for dense \textbf{PO}int \textbf{T}racking and online video processing. The \textbf{SPOT} framework features three core components: a customized memory reading module for feature enhancement, a sensory memory for short-term motion dynamics modeling, and a visibility-guided splatting module for accurate information propagation. This combination enables SPOT to perform dense point tracking with state-of-the-art accuracy on the CVO benchmark, as well as comparable or superior performance to offline models on sparse tracking benchmarks such as TAP-Vid and RoboTAP. Notably, SPOT with 10$\times$ smaller parameter numbers operates at least 2$\times$ faster than previous state-of-the-art models while maintaining the best performance on CVO. We will release the models and codes at: https://github.com/DQiaole/SPOT.
MemFlow: Optical Flow Estimation and Prediction with Memory
Apr 07, 2024



Optical flow is a classical task that is important to the vision community. Classical optical flow estimation uses two frames as input, whilst some recent methods consider multiple frames to explicitly model long-range information. The former ones limit their ability to fully leverage temporal coherence along the video sequence; and the latter ones incur heavy computational overhead, typically not possible for real-time flow estimation. Some multi-frame-based approaches even necessitate unseen future frames for current estimation, compromising real-time applicability in safety-critical scenarios. To this end, we present MemFlow, a real-time method for optical flow estimation and prediction with memory. Our method enables memory read-out and update modules for aggregating historical motion information in real-time. Furthermore, we integrate resolution-adaptive re-scaling to accommodate diverse video resolutions. Besides, our approach seamlessly extends to the future prediction of optical flow based on past observations. Leveraging effective historical motion aggregation, our method outperforms VideoFlow with fewer parameters and faster inference speed on Sintel and KITTI-15 datasets in terms of generalization performance. At the time of submission, MemFlow also leads in performance on the 1080p Spring dataset. Codes and models will be available at: https://dqiaole.github.io/MemFlow/.
Repositioning the Subject within Image
Jan 30, 2024



Current image manipulation primarily centers on static manipulation, such as replacing specific regions within an image or altering its overall style. In this paper, we introduce an innovative dynamic manipulation task, subject repositioning. This task involves relocating a user-specified subject to a desired position while preserving the image's fidelity. Our research reveals that the fundamental sub-tasks of subject repositioning, which include filling the void left by the repositioned subject, reconstructing obscured portions of the subject and blending the subject to be consistent with surrounding areas, can be effectively reformulated as a unified, prompt-guided inpainting task. Consequently, we can employ a single diffusion generative model to address these sub-tasks using various task prompts learned through our proposed task inversion technique. Additionally, we integrate pre-processing and post-processing techniques to further enhance the quality of subject repositioning. These elements together form our SEgment-gEnerate-and-bLEnd (SEELE) framework. To assess SEELE's effectiveness in subject repositioning, we assemble a real-world subject repositioning dataset called ReS. Our results on ReS demonstrate the quality of repositioned image generation.
Open-DDVM: A Reproduction and Extension of Diffusion Model for Optical Flow Estimation
Dec 04, 2023Recently, Google proposes DDVM which for the first time demonstrates that a general diffusion model for image-to-image translation task works impressively well on optical flow estimation task without any specific designs like RAFT. However, DDVM is still a closed-source model with the expensive and private Palette-style pretraining. In this technical report, we present the first open-source DDVM by reproducing it. We study several design choices and find those important ones. By training on 40k public data with 4 GPUs, our reproduction achieves comparable performance to the closed-source DDVM. The code and model have been released in https://github.com/DQiaole/FlowDiffusion_pytorch.
A Unified Prompt-Guided In-Context Inpainting Framework for Reference-based Image Manipulations
May 19, 2023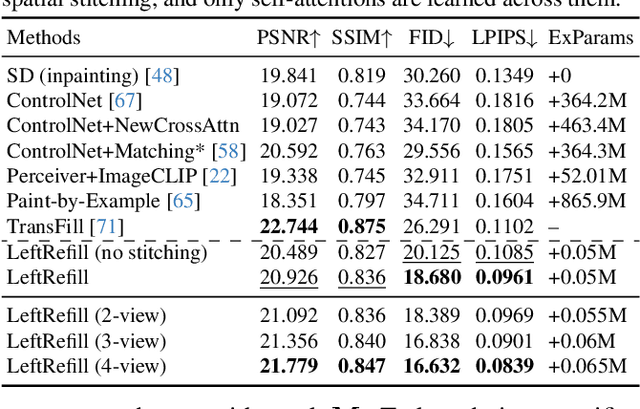
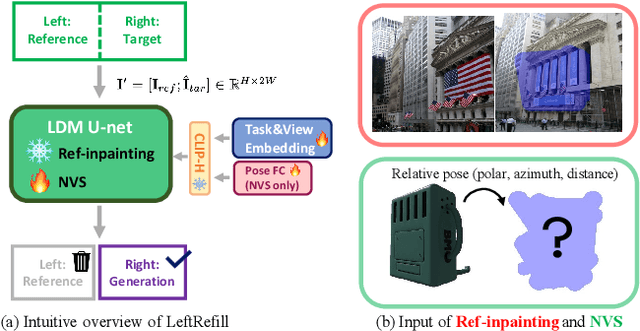

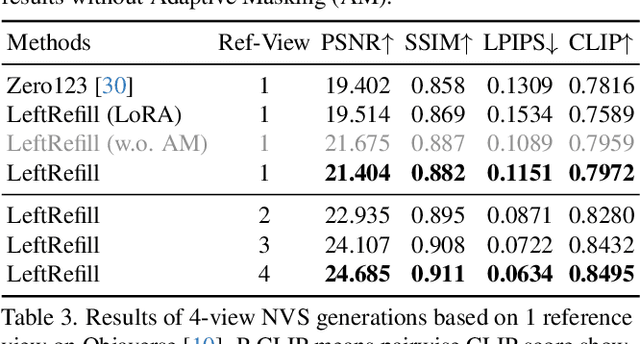
Recent advancements in Text-to-Image (T2I) generative models have yielded impressive results in generating high-fidelity images based on consistent text prompts. However, there is a growing interest in exploring the potential of these models for more diverse reference-based image manipulation tasks that require spatial understanding and visual context. Previous approaches have achieved this by incorporating additional control modules or fine-tuning the generative models specifically for each task until convergence. In this paper, we propose a different perspective. We conjecture that current large-scale T2I generative models already possess the capability to perform these tasks but are not fully activated within the standard generation process. To unlock these capabilities, we introduce a unified Prompt-Guided In-Context inpainting (PGIC) framework, which leverages large-scale T2I models to re-formulate and solve reference-guided image manipulations. In the PGIC framework, the reference and masked target are stitched together as a new input for the generative models, enabling the filling of masked regions as producing final results. Furthermore, we demonstrate that the self-attention modules in T2I models are well-suited for establishing spatial correlations and efficiently addressing challenging reference-guided manipulations. These large T2I models can be effectively driven by task-specific prompts with minimal training cost or even with frozen backbones. We synthetically evaluate the effectiveness of the proposed PGIC framework across various tasks, including reference-guided image inpainting, faithful inpainting, outpainting, local super-resolution, and novel view synthesis. Our results show that PGIC achieves significantly better performance while requiring less computation compared to other fine-tuning based approaches.
Rethinking Optical Flow from Geometric Matching Consistent Perspective
Mar 15, 2023



Optical flow estimation is a challenging problem remaining unsolved. Recent deep learning based optical flow models have achieved considerable success. However, these models often train networks from the scratch on standard optical flow data, which restricts their ability to robustly and geometrically match image features. In this paper, we propose a rethinking to previous optical flow estimation. We particularly leverage Geometric Image Matching (GIM) as a pre-training task for the optical flow estimation (MatchFlow) with better feature representations, as GIM shares some common challenges as optical flow estimation, and with massive labeled real-world data. Thus, matching static scenes helps to learn more fundamental feature correlations of objects and scenes with consistent displacements. Specifically, the proposed MatchFlow model employs a QuadTree attention-based network pre-trained on MegaDepth to extract coarse features for further flow regression. Extensive experiments show that our model has great cross-dataset generalization. Our method achieves 11.5% and 10.1% error reduction from GMA on Sintel clean pass and KITTI test set. At the time of anonymous submission, our MatchFlow(G) enjoys state-of-the-art performance on Sintel clean and final pass compared to published approaches with comparable computation and memory footprint. Codes and models will be released in https://github.com/DQiaole/MatchFlow.
ZITS++: Image Inpainting by Improving the Incremental Transformer on Structural Priors
Oct 12, 2022
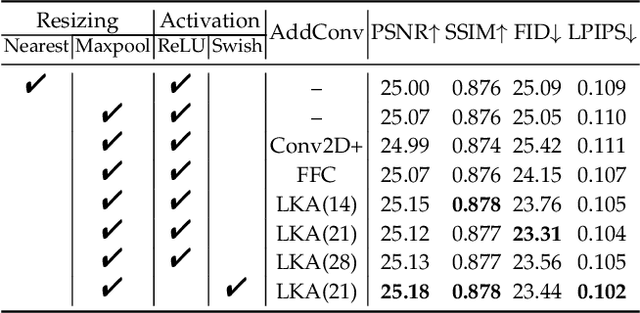

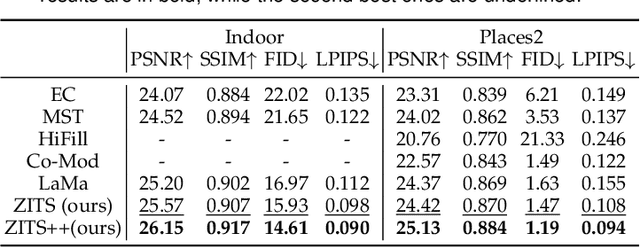
The image inpainting task fills missing areas of a corrupted image. Despite impressive results have been achieved recently, it is still challenging to restore corrupted images with both vivid textures and reasonable structures. Some previous methods only tackle regular textures while losing holistic structures limited by receptive fields of Convolution Neural Networks (CNNs). To this end, we study learning a Zero-initialized residual addition based Incremental Transformer on Structural priors (ZITS++), an improved model over our conference ZITS model. Specifically, given one corrupt image, we present the Transformer Structure Restorer (TSR) module to restore holistic structural priors at low image resolution, which are further upsampled by Simple Structure Upsampler (SSU) module to higher image resolution. Further, to well recover image texture details, we take the Fourier CNN Texture Restoration (FTR) module, which has both the Fourier and large-kernel attention convolutions. Typically, FTR can be independently pre-trained without image structural priors. Furthermore, to enhance the FTR, the upsampled structural priors from TSR are further processed by Structure Feature Encoder (SFE), and updating the FTR by a novel incremental training strategy of Zero-initialized Residual Addition (ZeroRA). Essentially, a new masking positional encoding is proposed to encode the large irregular masks. Extensive experiments on various datasets validate the efficacy of our model compared with other competitors. We also conduct extensive ablation to compare and verify various priors for image inpainting tasks.
Learning Prior Feature and Attention Enhanced Image Inpainting
Aug 03, 2022

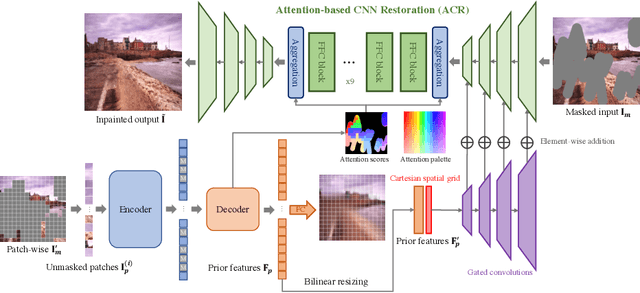

Many recent inpainting works have achieved impressive results by leveraging Deep Neural Networks (DNNs) to model various prior information for image restoration. Unfortunately, the performance of these methods is largely limited by the representation ability of vanilla Convolutional Neural Networks (CNNs) backbones.On the other hand, Vision Transformers (ViT) with self-supervised pre-training have shown great potential for many visual recognition and object detection tasks. A natural question is whether the inpainting task can be greatly benefited from the ViT backbone? However, it is nontrivial to directly replace the new backbones in inpainting networks, as the inpainting is an inverse problem fundamentally different from the recognition tasks. To this end, this paper incorporates the pre-training based Masked AutoEncoder (MAE) into the inpainting model, which enjoys richer informative priors to enhance the inpainting process. Moreover, we propose to use attention priors from MAE to make the inpainting model learn more long-distance dependencies between masked and unmasked regions. Sufficient ablations have been discussed about the inpainting and the self-supervised pre-training models in this paper. Besides, experiments on both Places2 and FFHQ demonstrate the effectiveness of our proposed model. Codes and pre-trained models are released in https://github.com/ewrfcas/MAE-FAR.