 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealCamo: Boosting Real Camouflage Synthesis with Layout Controls and Textual-Visual Guidance
Dec 28, 2025Camouflaged image generation (CIG) has recently emerged as an efficient alternative for acquiring high-quality training data for camouflaged object detection (COD). However, existing CIG methods still suffer from a substantial gap to real camouflaged imagery: generated images either lack sufficient camouflage due to weak visual similarity, or exhibit cluttered backgrounds that are semantically inconsistent with foreground targets. To address these limitations, we propose ReamCamo, a unified out-painting based framework for realistic camouflaged image generation. ReamCamo explicitly introduces additional layout controls to regulate global image structure, thereby improving semantic coherence between foreground objects and generated backgrounds. Moreover, we construct a multi-modal textual-visual condition by combining a unified fine-grained textual task description with texture-oriented background retrieval, which jointly guides the generation process to enhance visual fidelity and realism. To quantitatively assess camouflage quality, we further introduce a background-foreground distribution divergence metric that measures the effectiveness of camouflage in generated images. Extensive experiments and visualizations demonstrate the effectiveness of our proposed framework.
Efficient Algorithms for Empirical Group Distributional Robust Optimization and Beyond
Mar 06, 2024

We investigate the empirical counterpart of group distributionally robust optimization (GDRO), which aims to minimize the maximal empirical risk across $m$ distinct groups. We formulate empirical GDRO as a $\textit{two-level}$ finite-sum convex-concave minimax optimization problem and develop a stochastic variance reduced mirror prox algorithm. Unlike existing methods, we construct the stochastic gradient by per-group sampling technique and perform variance reduction for all groups, which fully exploits the $\textit{two-level}$ finite-sum structure of empirical GDRO. Furthermore, we compute the snapshot and mirror snapshot point by a one-index-shifted weighted average, which distinguishes us from the naive ergodic average. Our algorithm also supports non-constant learning rates, which is different from existing literature. We establish convergence guarantees both in expectation and with high probability, demonstrating a complexity of $\mathcal{O}\left(\frac{m\sqrt{\bar{n}\ln{m}}}{\varepsilon}\right)$, where $\bar n$ is the average number of samples among $m$ groups. Remarkably, our approach outperforms the state-of-the-art method by a factor of $\sqrt{m}$. Furthermore, we extend our methodology to deal with the empirical minimax excess risk optimization (MERO) problem and manage to give the expectation bound and the high probability bound, accordingly. The complexity of our empirical MERO algorithm matches that of empirical GDRO at $\mathcal{O}\left(\frac{m\sqrt{\bar{n}\ln{m}}}{\varepsilon}\right)$, significantly surpassing the bounds of existing methods.
A Unified Prompt-Guided In-Context Inpainting Framework for Reference-based Image Manipulations
May 19, 2023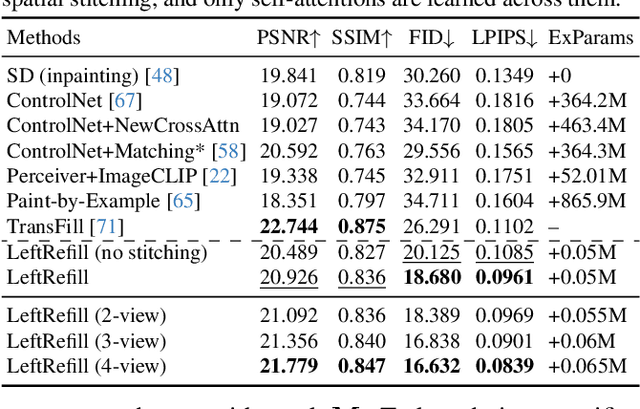
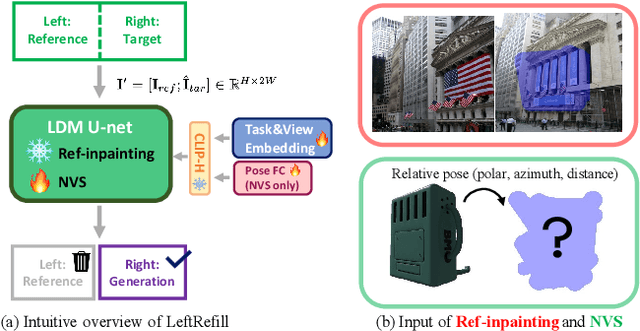

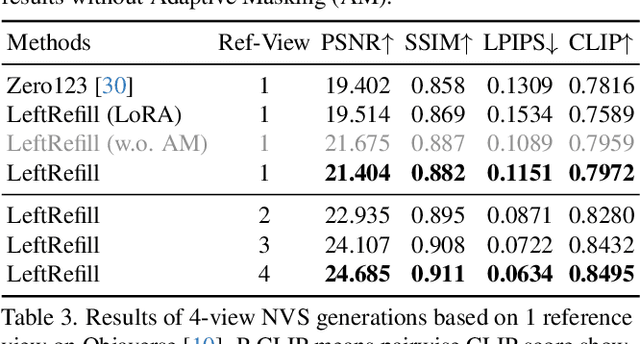
Recent advancements in Text-to-Image (T2I) generative models have yielded impressive results in generating high-fidelity images based on consistent text prompts. However, there is a growing interest in exploring the potential of these models for more diverse reference-based image manipulation tasks that require spatial understanding and visual context. Previous approaches have achieved this by incorporating additional control modules or fine-tuning the generative models specifically for each task until convergence. In this paper, we propose a different perspective. We conjecture that current large-scale T2I generative models already possess the capability to perform these tasks but are not fully activated within the standard generation process. To unlock these capabilities, we introduce a unified Prompt-Guided In-Context inpainting (PGIC) framework, which leverages large-scale T2I models to re-formulate and solve reference-guided image manipulations. In the PGIC framework, the reference and masked target are stitched together as a new input for the generative models, enabling the filling of masked regions as producing final results. Furthermore, we demonstrate that the self-attention modules in T2I models are well-suited for establishing spatial correlations and efficiently addressing challenging reference-guided manipulations. These large T2I models can be effectively driven by task-specific prompts with minimal training cost or even with frozen backbones. We synthetically evaluate the effectiveness of the proposed PGIC framework across various tasks, including reference-guided image inpainting, faithful inpainting, outpainting, local super-resolution, and novel view synthesis. Our results show that PGIC achieves significantly better performance while requiring less computation compared to other fine-tuning based approaches.