 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Viewpoint-Independent Object-Centric Representations through Active Viewpoint Selection
Nov 01, 2024
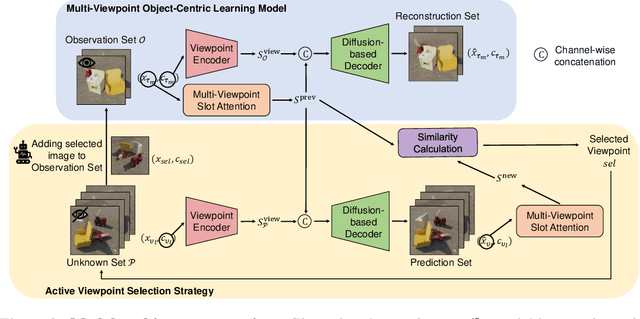

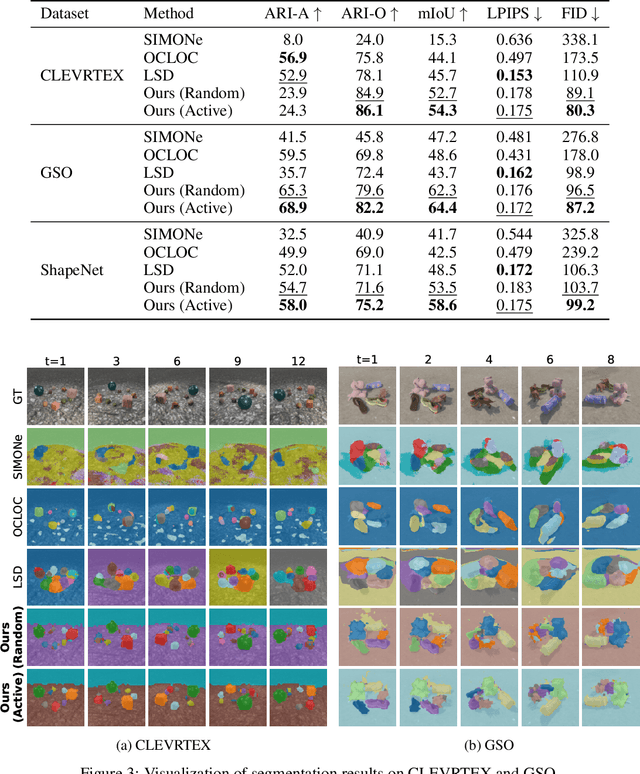
Given the complexities inherent in visual scenes, such as object occlusion, a comprehensive understanding often requires observation from multiple viewpoints. Existing multi-viewpoint object-centric learning methods typically employ random or sequential viewpoint selection strategies. While applicable across various scenes, these strategies may not always be ideal, as certain scenes could benefit more from specific viewpoints. To address this limitation, we propose a novel active viewpoint selection strategy. This strategy predicts images from unknown viewpoints based on information from observation images for each scene. It then compares the object-centric representations extracted from both viewpoints and selects the unknown viewpoint with the largest disparity, indicating the greatest gain in information, as the next observation viewpoint. Through experiments on various datasets, we demonstrate the effectiveness of our active viewpoint selection strategy, significantly enhancing segmentation and reconstruction performance compared to random viewpoint selection. Moreover, our method can accurately predict images from unknown viewpoints.
Time-Conditioned Generative Modeling of Object-Centric Representations for Video Decomposition and Prediction
Jan 21, 2023When perceiving the world from multiple viewpoints, humans have the ability to reason about the complete objects in a compositional manner even when the object is completely occluded from partial viewpoints. Meanwhile, humans can imagine the novel views after observing multiple viewpoints. The remarkable recent advance in multi-view object-centric learning leaves some problems: 1) the partially or completely occluded shape of objects can not be well reconstructed. 2) the novel viewpoint prediction depends on expensive viewpoint annotations rather than implicit view rules. This makes the agent fail to perform like humans. In this paper, we introduce a time-conditioned generative model for videos. To reconstruct the complete shape of the object accurately, we enhance the disentanglement between different latent representations: view latent representations are jointly inferred based on the Transformer and then cooperate with the sequential extension of Slot Attention to learn object-centric representations. The model also achieves the new ability: Gaussian processes are employed as priors of view latent variables for generation and novel-view prediction without viewpoint annotations. Experiments on multiple specifically designed synthetic datasets have shown that the proposed model can 1) make the video decomposition, 2) reconstruct the complete shapes of objects, and 3) make the novel viewpoint prediction without viewpoint annotations.