 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Viewpoint-Independent Object-Centric Representations through Active Viewpoint Selection
Nov 01, 2024
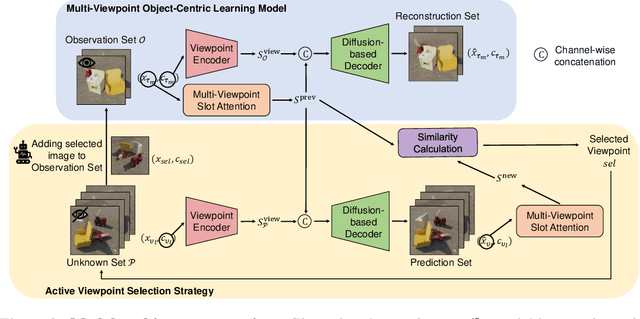

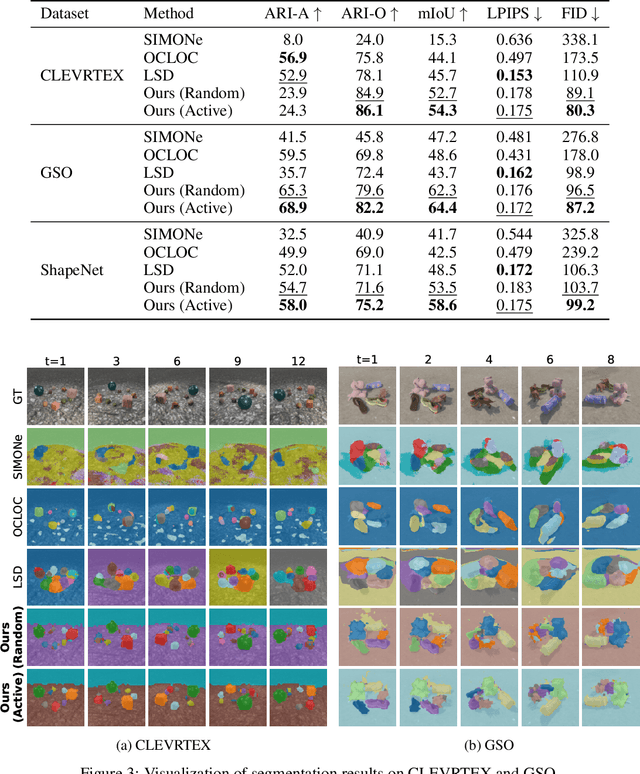
Given the complexities inherent in visual scenes, such as object occlusion, a comprehensive understanding often requires observation from multiple viewpoints. Existing multi-viewpoint object-centric learning methods typically employ random or sequential viewpoint selection strategies. While applicable across various scenes, these strategies may not always be ideal, as certain scenes could benefit more from specific viewpoints. To address this limitation, we propose a novel active viewpoint selection strategy. This strategy predicts images from unknown viewpoints based on information from observation images for each scene. It then compares the object-centric representations extracted from both viewpoints and selects the unknown viewpoint with the largest disparity, indicating the greatest gain in information, as the next observation viewpoint. Through experiments on various datasets, we demonstrate the effectiveness of our active viewpoint selection strategy, significantly enhancing segmentation and reconstruction performance compared to random viewpoint selection. Moreover, our method can accurately predict images from unknown viewpoints.
Learning Global Object-Centric Representations via Disentangled Slot Attention
Oct 24, 2024Humans can discern scene-independent features of objects across various environments, allowing them to swiftly identify objects amidst changing factors such as lighting, perspective, size, and position and imagine the complete images of the same object in diverse settings. Existing object-centric learning methods only extract scene-dependent object-centric representations, lacking the ability to identify the same object across scenes as humans. Moreover, some existing methods discard the individual object generation capabilities to handle complex scenes. This paper introduces a novel object-centric learning method to empower AI systems with human-like capabilities to identify objects across scenes and generate diverse scenes containing specific objects by learning a set of global object-centric representations. To learn the global object-centric representations that encapsulate globally invariant attributes of objects (i.e., the complete appearance and shape), this paper designs a Disentangled Slot Attention module to convert the scene features into scene-dependent attributes (such as scale, position and orientation) and scene-independent representations (i.e., appearance and shape). Experimental results substantiate the efficacy of the proposed method, demonstrating remarkable proficiency in global object-centric representation learning, object identification, scene generation with specific objects and scene decomposition.
OCTScenes: A Versatile Real-World Dataset of Tabletop Scenes for Object-Centric Learning
Jun 20, 2023Humans possess the cognitive ability to comprehend scenes in a compositional manner. To empower AI systems with similar abilities, object-centric representation learning aims to acquire representations of individual objects from visual scenes without any supervision. Although recent advancements in object-centric representation learning have achieved remarkable progress on complex synthesis datasets, there is a huge challenge for application in complex real-world scenes. One of the essential reasons is the scarcity of real-world datasets specifically tailored to object-centric representation learning methods. To solve this problem, we propose a versatile real-world dataset of tabletop scenes for object-centric learning called OCTScenes, which is meticulously designed to serve as a benchmark for comparing, evaluating and analyzing object-centric representation learning methods. OCTScenes contains 5000 tabletop scenes with a total of 15 everyday objects. Each scene is captured in 60 frames covering a 360-degree perspective. Consequently, OCTScenes is a versatile benchmark dataset that can simultaneously satisfy the evaluation of object-centric representation learning methods across static scenes, dynamic scenes, and multi-view scenes tasks. Extensive experiments of object-centric representation learning methods for static, dynamic and multi-view scenes are conducted on OCTScenes. The results demonstrate the shortcomings of state-of-the-art methods for learning meaningful representations from real-world data, despite their impressive performance on complex synthesis datasets. Furthermore, OCTScenes can serves as a catalyst for advancing existing state-of-the-art methods, inspiring them to adapt to real-world scenes. Dataset and code are available at https://huggingface.co/datasets/Yinxuan/OCTScenes.