 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Global Object-Centric Representations via Disentangled Slot Attention
Oct 24, 2024Humans can discern scene-independent features of objects across various environments, allowing them to swiftly identify objects amidst changing factors such as lighting, perspective, size, and position and imagine the complete images of the same object in diverse settings. Existing object-centric learning methods only extract scene-dependent object-centric representations, lacking the ability to identify the same object across scenes as humans. Moreover, some existing methods discard the individual object generation capabilities to handle complex scenes. This paper introduces a novel object-centric learning method to empower AI systems with human-like capabilities to identify objects across scenes and generate diverse scenes containing specific objects by learning a set of global object-centric representations. To learn the global object-centric representations that encapsulate globally invariant attributes of objects (i.e., the complete appearance and shape), this paper designs a Disentangled Slot Attention module to convert the scene features into scene-dependent attributes (such as scale, position and orientation) and scene-independent representations (i.e., appearance and shape). Experimental results substantiate the efficacy of the proposed method, demonstrating remarkable proficiency in global object-centric representation learning, object identification, scene generation with specific objects and scene decomposition.
Unsupervised Object-Centric Learning from Multiple Unspecified Viewpoints
Jan 03, 2024



Visual scenes are extremely diverse, not only because there are infinite possible combinations of objects and backgrounds but also because the observations of the same scene may vary greatly with the change of viewpoints. When observing a multi-object visual scene from multiple viewpoints, humans can perceive the scene compositionally from each viewpoint while achieving the so-called ``object constancy'' across different viewpoints, even though the exact viewpoints are untold. This ability is essential for humans to identify the same object while moving and to learn from vision efficiently. It is intriguing to design models that have a similar ability. In this paper, we consider a novel problem of learning compositional scene representations from multiple unspecified (i.e., unknown and unrelated) viewpoints without using any supervision and propose a deep generative model which separates latent representations into a viewpoint-independent part and a viewpoint-dependent part to solve this problem. During the inference, latent representations are randomly initialized and iteratively updated by integrating the information in different viewpoints with neural networks. Experiments on several specifically designed synthetic datasets have shown that the proposed method can effectively learn from multiple unspecified viewpoints.
OCTScenes: A Versatile Real-World Dataset of Tabletop Scenes for Object-Centric Learning
Jun 20, 2023
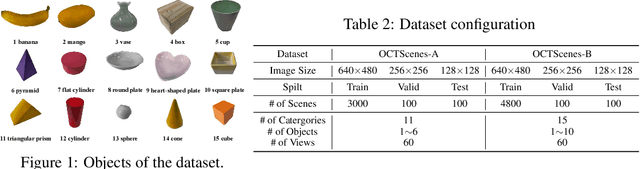


Humans possess the cognitive ability to comprehend scenes in a compositional manner. To empower AI systems with similar abilities, object-centric representation learning aims to acquire representations of individual objects from visual scenes without any supervision. Although recent advancements in object-centric representation learning have achieved remarkable progress on complex synthesis datasets, there is a huge challenge for application in complex real-world scenes. One of the essential reasons is the scarcity of real-world datasets specifically tailored to object-centric representation learning methods. To solve this problem, we propose a versatile real-world dataset of tabletop scenes for object-centric learning called OCTScenes, which is meticulously designed to serve as a benchmark for comparing, evaluating and analyzing object-centric representation learning methods. OCTScenes contains 5000 tabletop scenes with a total of 15 everyday objects. Each scene is captured in 60 frames covering a 360-degree perspective. Consequently, OCTScenes is a versatile benchmark dataset that can simultaneously satisfy the evaluation of object-centric representation learning methods across static scenes, dynamic scenes, and multi-view scenes tasks. Extensive experiments of object-centric representation learning methods for static, dynamic and multi-view scenes are conducted on OCTScenes. The results demonstrate the shortcomings of state-of-the-art methods for learning meaningful representations from real-world data, despite their impressive performance on complex synthesis datasets. Furthermore, OCTScenes can serves as a catalyst for advancing existing state-of-the-art methods, inspiring them to adapt to real-world scenes. Dataset and code are available at https://huggingface.co/datasets/Yinxuan/OCTScenes.
Compositional Scene Modeling with Global Object-Centric Representations
Nov 24, 2022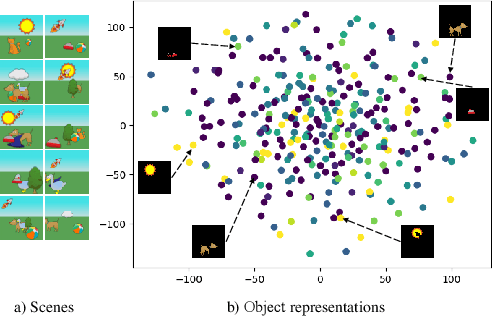
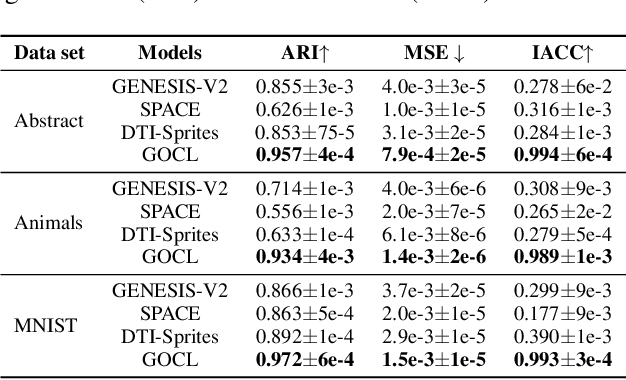
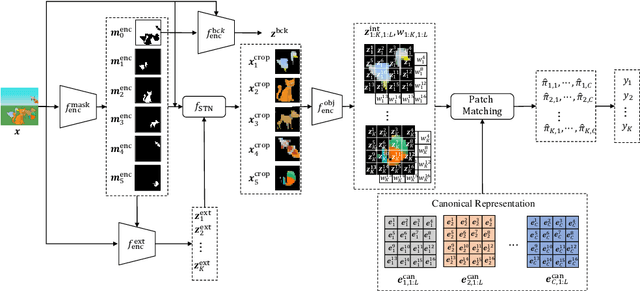
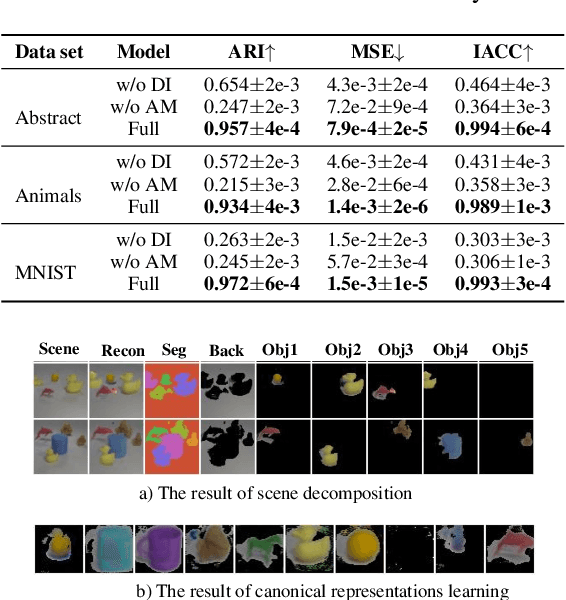
The appearance of the same object may vary in different scene images due to perspectives and occlusions between objects. Humans can easily identify the same object, even if occlusions exist, by completing the occluded parts based on its canonical image in the memory. Achieving this ability is still a challenge for machine learning, especially under the unsupervised learning setting. Inspired by such an ability of humans, this paper proposes a compositional scene modeling method to infer global representations of canonical images of objects without any supervision. The representation of each object is divided into an intrinsic part, which characterizes globally invariant information (i.e. canonical representation of an object), and an extrinsic part, which characterizes scene-dependent information (e.g., position and size). To infer the intrinsic representation of each object, we employ a patch-matching strategy to align the representation of a potentially occluded object with the canonical representations of objects, and sample the most probable canonical representation based on the category of object determined by amortized variational inference. Extensive experiments are conducted on four object-centric learning benchmarks, and experimental results demonstrate that the proposed method not only outperforms state-of-the-arts in terms of segmentation and reconstruction, but also achieves good global object identification performance.
Compositional Scene Representation Learning via Reconstruction: A Survey
Feb 15, 2022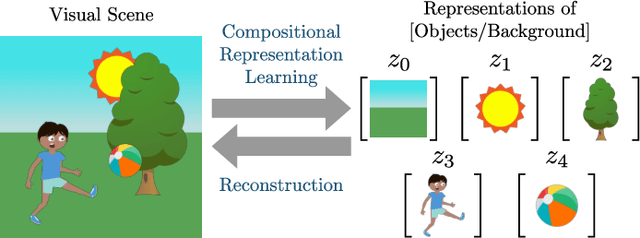



Visual scene representation learning is an important research problem in the field of computer vision. The performance on vision tasks could be improved if more suitable representations are learned for visual scenes. Complex visual scenes are the composition of relatively simple visual concepts, and have the property of combinatorial explosion. Compared with directly representing the entire visual scene, extracting compositional scene representations can better cope with the diverse combination of background and objects. Because compositional scene representations abstract the concept of objects, performing visual scene analysis and understanding based on these representations could be easier and more interpretable. Moreover, learning compositional scene representations via reconstruction can greatly reduce the need for training data annotations. Therefore, compositional scene representation learning via reconstruction has important research significance. In this survey, we first discuss representative methods that either learn from a single viewpoint or multiple viewpoints without object-level supervision, then the applications of compositional scene representations, and finally the future directions on this topic.