 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Scene Modeling with Global Object-Centric Representations
Paper and Code
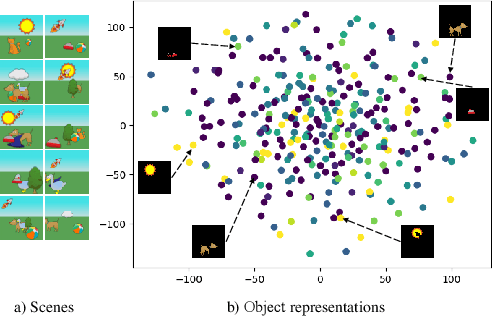
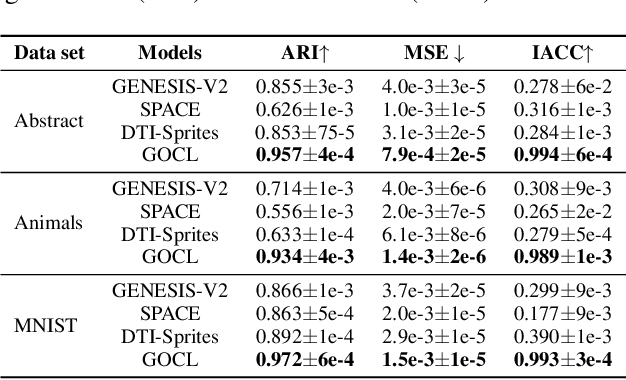
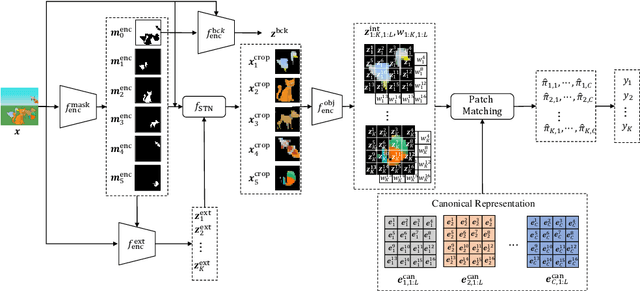
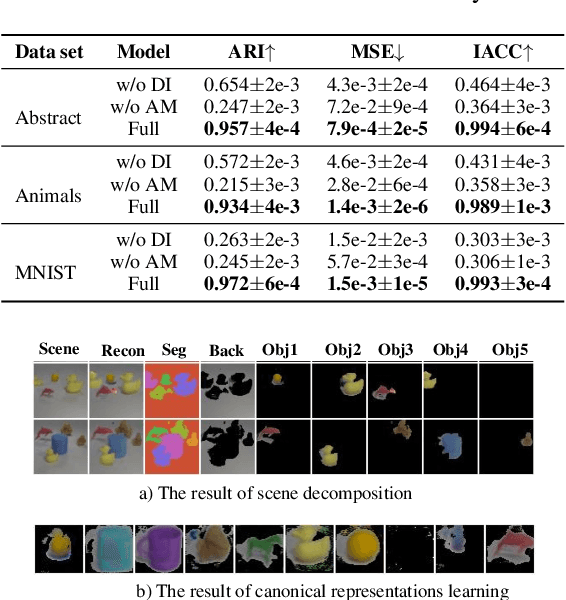
The appearance of the same object may vary in different scene images due to perspectives and occlusions between objects. Humans can easily identify the same object, even if occlusions exist, by completing the occluded parts based on its canonical image in the memory. Achieving this ability is still a challenge for machine learning, especially under the unsupervised learning setting. Inspired by such an ability of humans, this paper proposes a compositional scene modeling method to infer global representations of canonical images of objects without any supervision. The representation of each object is divided into an intrinsic part, which characterizes globally invariant information (i.e. canonical representation of an object), and an extrinsic part, which characterizes scene-dependent information (e.g., position and size). To infer the intrinsic representation of each object, we employ a patch-matching strategy to align the representation of a potentially occluded object with the canonical representations of objects, and sample the most probable canonical representation based on the category of object determined by amortized variational inference. Extensive experiments are conducted on four object-centric learning benchmarks, and experimental results demonstrate that the proposed method not only outperforms state-of-the-arts in terms of segmentation and reconstruction, but also achieves good global object identification performance.