 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Scene Representation Learning via Reconstruction: A Survey
Paper and Code
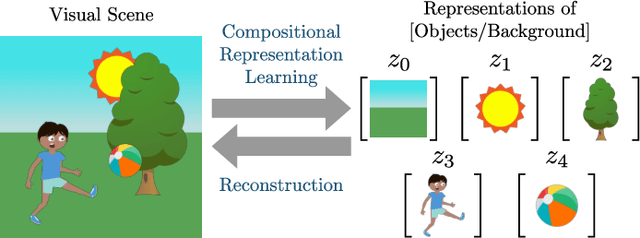



Visual scene representation learning is an important research problem in the field of computer vision. The performance on vision tasks could be improved if more suitable representations are learned for visual scenes. Complex visual scenes are the composition of relatively simple visual concepts, and have the property of combinatorial explosion. Compared with directly representing the entire visual scene, extracting compositional scene representations can better cope with the diverse combination of background and objects. Because compositional scene representations abstract the concept of objects, performing visual scene analysis and understanding based on these representations could be easier and more interpretable. Moreover, learning compositional scene representations via reconstruction can greatly reduce the need for training data annotations. Therefore, compositional scene representation learning via reconstruction has important research significance. In this survey, we first discuss representative methods that either learn from a single viewpoint or multiple viewpoints without object-level supervision, then the applications of compositional scene representations, and finally the future directions on this topic.