 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Object-Centric Learning from Multiple Unspecified Viewpoints
Jan 03, 2024



Visual scenes are extremely diverse, not only because there are infinite possible combinations of objects and backgrounds but also because the observations of the same scene may vary greatly with the change of viewpoints. When observing a multi-object visual scene from multiple viewpoints, humans can perceive the scene compositionally from each viewpoint while achieving the so-called ``object constancy'' across different viewpoints, even though the exact viewpoints are untold. This ability is essential for humans to identify the same object while moving and to learn from vision efficiently. It is intriguing to design models that have a similar ability. In this paper, we consider a novel problem of learning compositional scene representations from multiple unspecified (i.e., unknown and unrelated) viewpoints without using any supervision and propose a deep generative model which separates latent representations into a viewpoint-independent part and a viewpoint-dependent part to solve this problem. During the inference, latent representations are randomly initialized and iteratively updated by integrating the information in different viewpoints with neural networks. Experiments on several specifically designed synthetic datasets have shown that the proposed method can effectively learn from multiple unspecified viewpoints.
Compositional Scene Representation Learning via Reconstruction: A Survey
Feb 15, 2022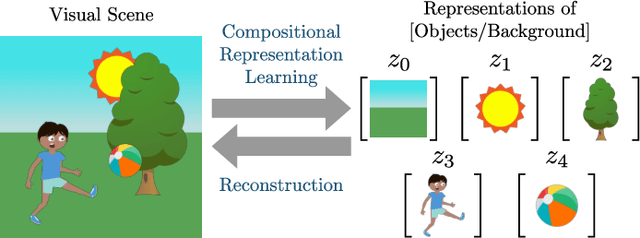



Visual scene representation learning is an important research problem in the field of computer vision. The performance on vision tasks could be improved if more suitable representations are learned for visual scenes. Complex visual scenes are the composition of relatively simple visual concepts, and have the property of combinatorial explosion. Compared with directly representing the entire visual scene, extracting compositional scene representations can better cope with the diverse combination of background and objects. Because compositional scene representations abstract the concept of objects, performing visual scene analysis and understanding based on these representations could be easier and more interpretable. Moreover, learning compositional scene representations via reconstruction can greatly reduce the need for training data annotations. Therefore, compositional scene representation learning via reconstruction has important research significance. In this survey, we first discuss representative methods that either learn from a single viewpoint or multiple viewpoints without object-level supervision, then the applications of compositional scene representations, and finally the future directions on this topic.
Unsupervised Learning of Compositional Scene Representations from Multiple Unspecified Viewpoints
Dec 12, 2021

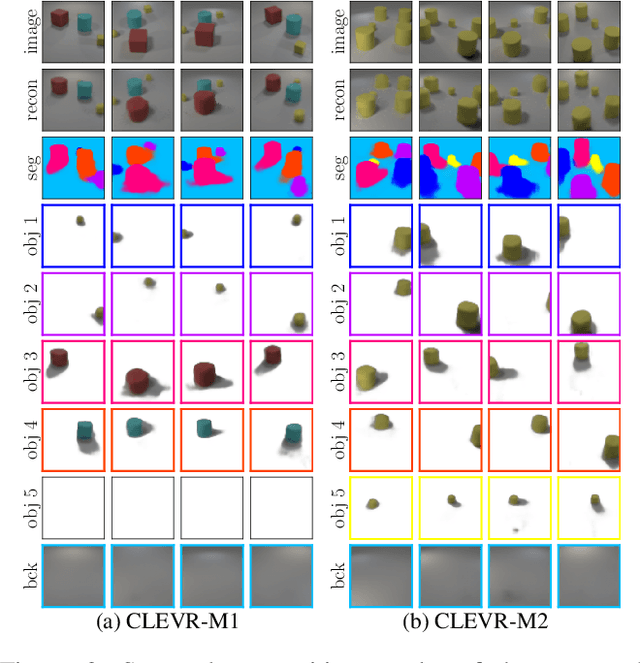
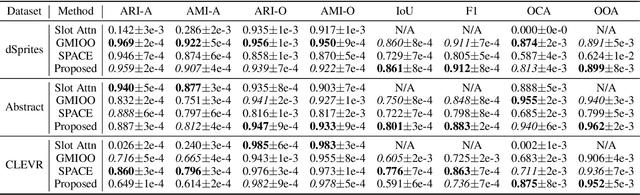
Visual scenes are extremely rich in diversity, not only because there are infinite combinations of objects and background, but also because the observations of the same scene may vary greatly with the change of viewpoints. When observing a visual scene that contains multiple objects from multiple viewpoints, humans are able to perceive the scene in a compositional way from each viewpoint, while achieving the so-called "object constancy" across different viewpoints, even though the exact viewpoints are untold. This ability is essential for humans to identify the same object while moving and to learn from vision efficiently. It is intriguing to design models that have the similar ability. In this paper, we consider a novel problem of learning compositional scene representations from multiple unspecified viewpoints without using any supervision, and propose a deep generative model which separates latent representations into a viewpoint-independent part and a viewpoint-dependent part to solve this problem. To infer latent representations, the information contained in different viewpoints is iteratively integrated by neural networks. Experiments on several specifically designed synthetic datasets have shown that the proposed method is able to effectively learn from multiple unspecified viewpoints.
Knowledge-Guided Object Discovery with Acquired Deep Impressions
Mar 19, 2021
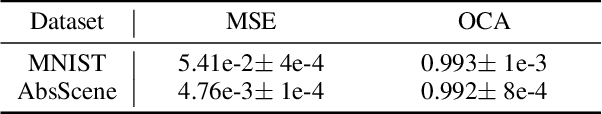
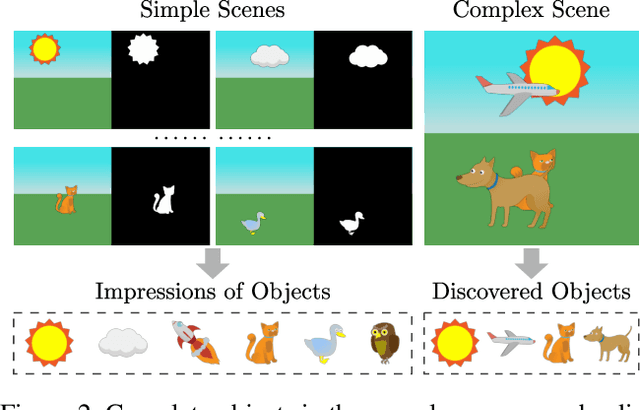
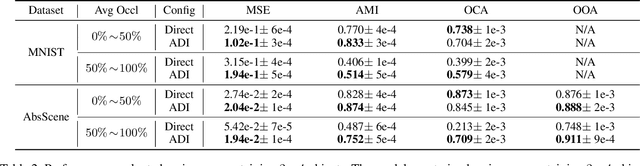
We present a framework called Acquired Deep Impressions (ADI) which continuously learns knowledge of objects as "impressions" for compositional scene understanding. In this framework, the model first acquires knowledge from scene images containing a single object in a supervised manner, and then continues to learn from novel multi-object scene images which may contain objects that have not been seen before without any further supervision, under the guidance of the learned knowledge as humans do. By memorizing impressions of objects into parameters of neural networks and applying the generative replay strategy, the learned knowledge can be reused to generate images with pseudo-annotations and in turn assist the learning of novel scenes. The proposed ADI framework focuses on the acquisition and utilization of knowledge, and is complementary to existing deep generative models proposed for compositional scene representation. We adapt a base model to make it fall within the ADI framework and conduct experiments on two types of datasets. Empirical results suggest that the proposed framework is able to effectively utilize the acquired impressions and improve the scene decomposition performance.
Spatial Mixture Models with Learnable Deep Priors for Perceptual Grouping
Feb 07, 2019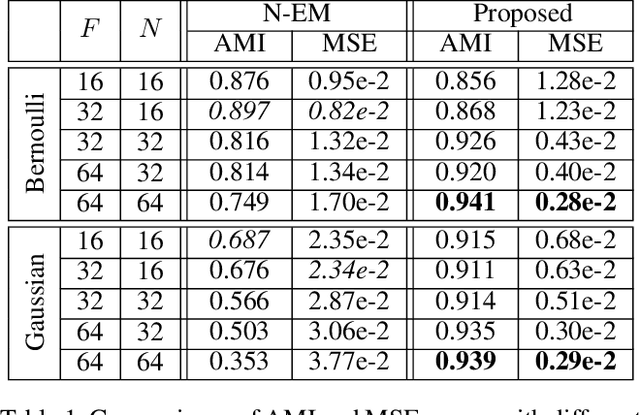
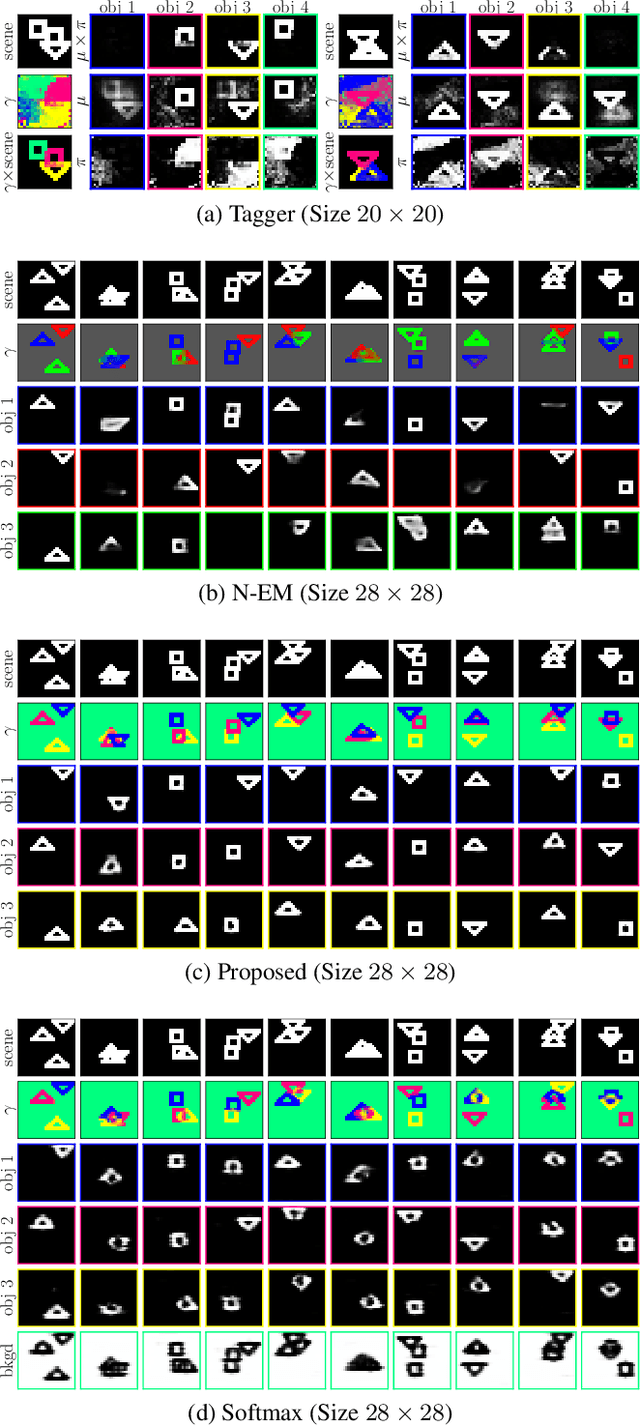
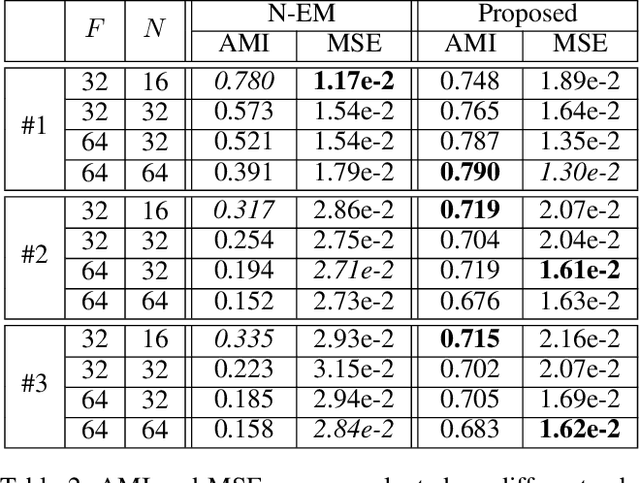
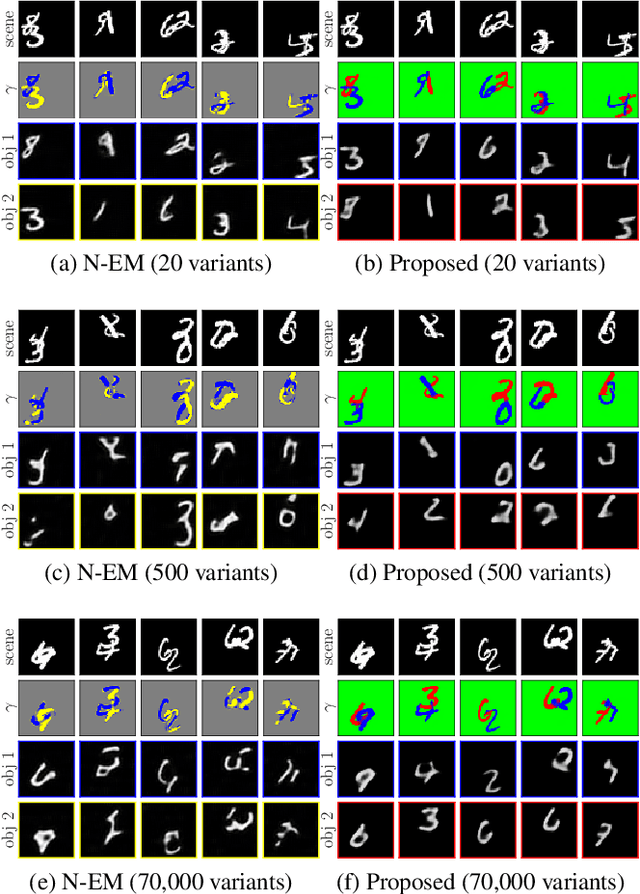
Humans perceive the seemingly chaotic world in a structured and compositional way with the prerequisite of being able to segregate conceptual entities from the complex visual scenes. The mechanism of grouping basic visual elements of scenes into conceptual entities is termed as perceptual grouping. In this work, we propose a new type of spatial mixture models with learnable priors for perceptual grouping. Different from existing methods, the proposed method disentangles the representation of an object into `shape' and `appearance' which are modeled separately by the mixture weights and the conditional probability distributions. More specifically, each object in the visual scene is modeled by one mixture component, whose mixture weights and the parameter of the conditional probability distribution are generated by two neural networks, respectively. The mixture weights focus on modeling spatial dependencies (i.e., shape) and the conditional probability distributions deal with intra-object variations (i.e., appearance). In addition, the background is separately modeled as a special component complementary to the foreground objects. Our extensive empirical tests on two perceptual grouping datasets demonstrate that the proposed method outperforms the state-of-the-art methods under most experimental configurations. The learned conceptual entities are generalizable to novel visual scenes and insensitive to the diversity of objects.