 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Guided Object Discovery with Acquired Deep Impressions
Paper and Code
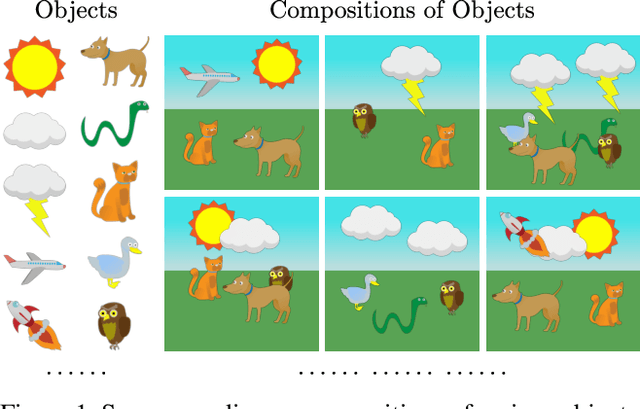
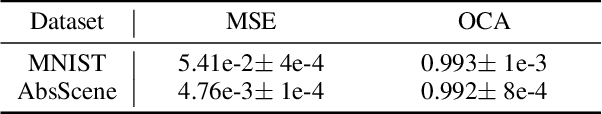
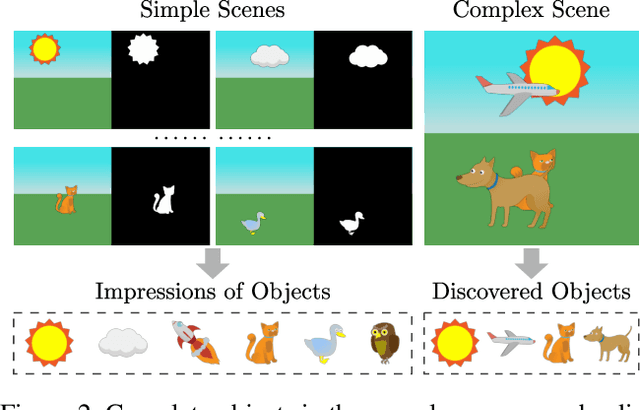
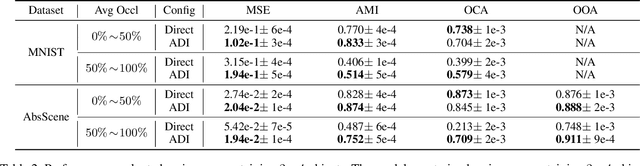
We present a framework called Acquired Deep Impressions (ADI) which continuously learns knowledge of objects as "impressions" for compositional scene understanding. In this framework, the model first acquires knowledge from scene images containing a single object in a supervised manner, and then continues to learn from novel multi-object scene images which may contain objects that have not been seen before without any further supervision, under the guidance of the learned knowledge as humans do. By memorizing impressions of objects into parameters of neural networks and applying the generative replay strategy, the learned knowledge can be reused to generate images with pseudo-annotations and in turn assist the learning of novel scenes. The proposed ADI framework focuses on the acquisition and utilization of knowledge, and is complementary to existing deep generative models proposed for compositional scene representation. We adapt a base model to make it fall within the ADI framework and conduct experiments on two types of datasets. Empirical results suggest that the proposed framework is able to effectively utilize the acquired impressions and improve the scene decomposition performance.