 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Mixture Models with Learnable Deep Priors for Perceptual Grouping
Paper and Code
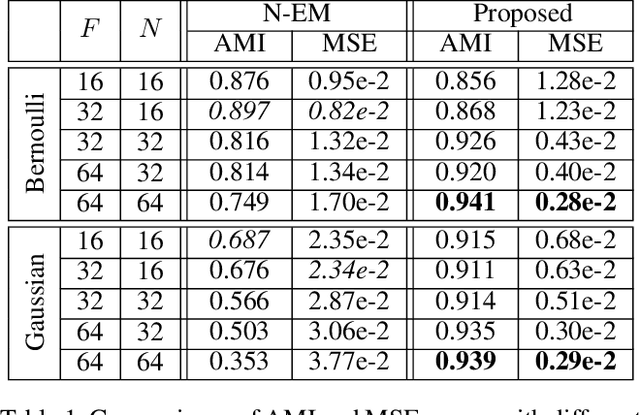
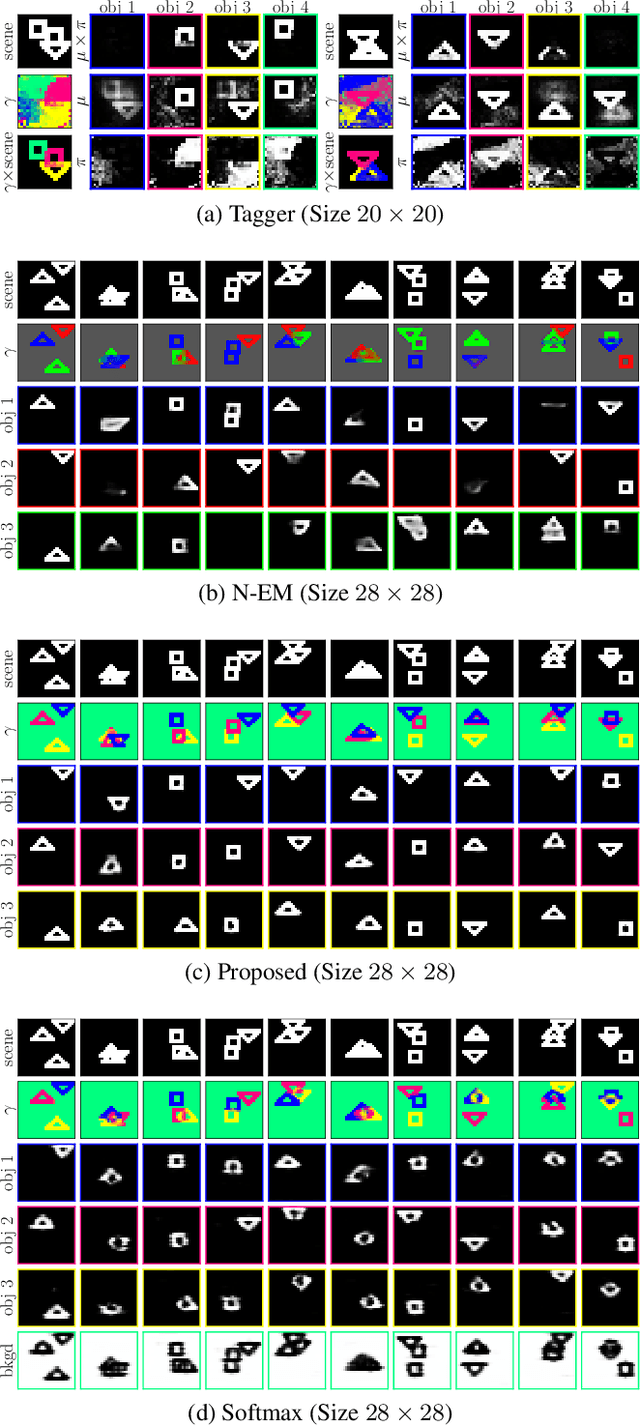
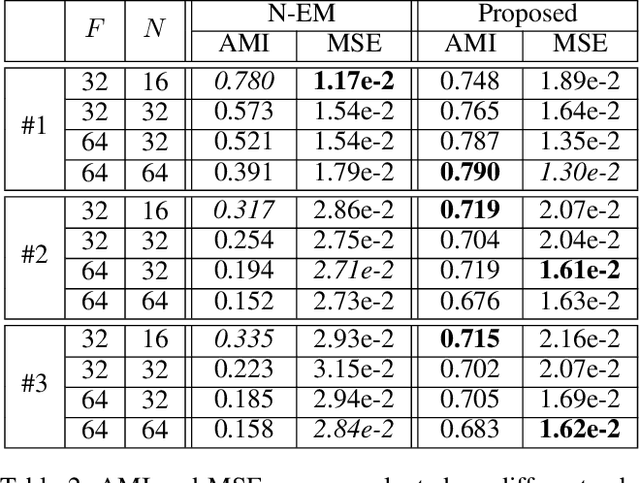
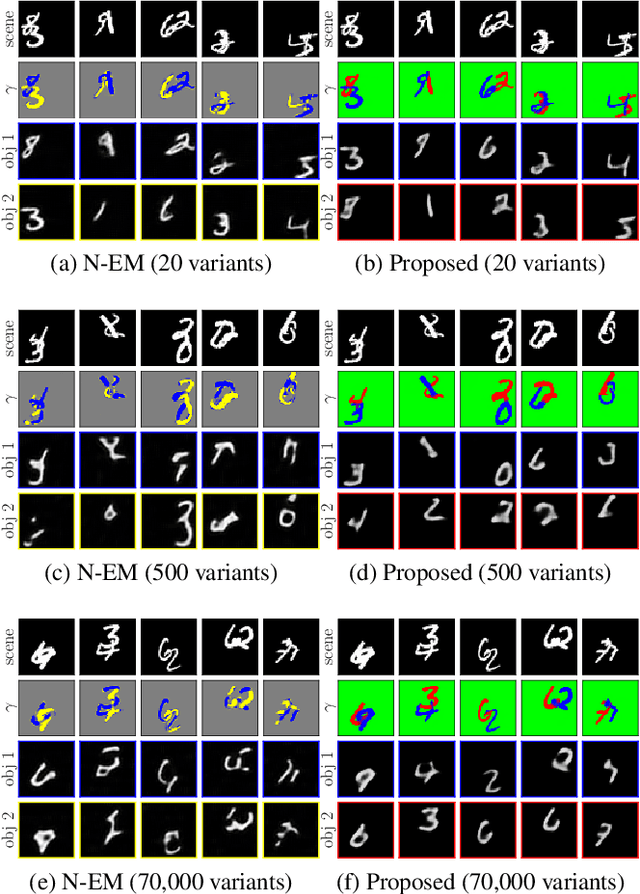
Humans perceive the seemingly chaotic world in a structured and compositional way with the prerequisite of being able to segregate conceptual entities from the complex visual scenes. The mechanism of grouping basic visual elements of scenes into conceptual entities is termed as perceptual grouping. In this work, we propose a new type of spatial mixture models with learnable priors for perceptual grouping. Different from existing methods, the proposed method disentangles the representation of an object into `shape' and `appearance' which are modeled separately by the mixture weights and the conditional probability distributions. More specifically, each object in the visual scene is modeled by one mixture component, whose mixture weights and the parameter of the conditional probability distribution are generated by two neural networks, respectively. The mixture weights focus on modeling spatial dependencies (i.e., shape) and the conditional probability distributions deal with intra-object variations (i.e., appearance). In addition, the background is separately modeled as a special component complementary to the foreground objects. Our extensive empirical tests on two perceptual grouping datasets demonstrate that the proposed method outperforms the state-of-the-art methods under most experimental configurations. The learned conceptual entities are generalizable to novel visual scenes and insensitive to the diversity of objects.