 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Modeling of the Denoising Process for Speech Enhancement Based on Deep Learning
Paper and Code
Sep 17, 2023

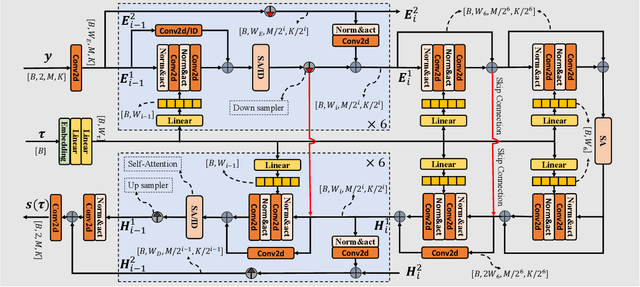

In this paper, we explore a continuous modeling approach for deep-learning-based speech enhancement, focusing on the denoising process. We use a state variable to indicate the denoising process. The starting state is noisy speech and the ending state is clean speech. The noise component in the state variable decreases with the change of the state index until the noise component is 0. During training, a UNet-like neural network learns to estimate every state variable sampled from the continuous denoising process. In testing, we introduce a controlling factor as an embedding, ranging from zero to one, to the neural network, allowing us to control the level of noise reduction. This approach enables controllable speech enhancement and is adaptable to various application scenarios. Experimental results indicate that preserving a small amount of noise in the clean target benefits speech enhancement, as evidenced by improvements in both objective speech measures and automatic speech recognition performance.