 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaVieID: Local Autoregressive Diffusion Transformers for Identity-Preserving Video Creation
Aug 11, 2025

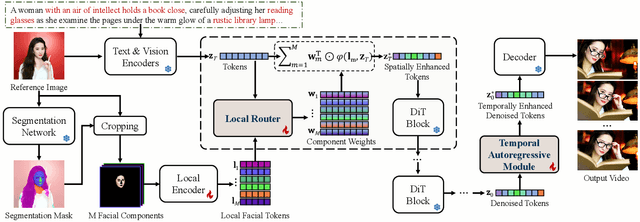

In this paper, we present LaVieID, a novel \underline{l}ocal \underline{a}utoregressive \underline{vi}d\underline{e}o diffusion framework designed to tackle the challenging \underline{id}entity-preserving text-to-video task. The key idea of LaVieID is to mitigate the loss of identity information inherent in the stochastic global generation process of diffusion transformers (DiTs) from both spatial and temporal perspectives. Specifically, unlike the global and unstructured modeling of facial latent states in existing DiTs, LaVieID introduces a local router to explicitly represent latent states by weighted combinations of fine-grained local facial structures. This alleviates undesirable feature interference and encourages DiTs to capture distinctive facial characteristics. Furthermore, a temporal autoregressive module is integrated into LaVieID to refine denoised latent tokens before video decoding. This module divides latent tokens temporally into chunks, exploiting their long-range temporal dependencies to predict biases for rectifying tokens, thereby significantly enhancing inter-frame identity consistency. Consequently, LaVieID can generate high-fidelity personalized videos and achieve state-of-the-art performance. Our code and models are available at https://github.com/ssugarwh/LaVieID.
Wearable intelligent throat enables natural speech in stroke patients with dysarthria
Nov 28, 2024



Wearable silent speech systems hold significant potential for restoring communication in patients with speech impairments. However, seamless, coherent speech remains elusive, and clinical efficacy is still unproven. Here, we present an AI-driven intelligent throat (IT) system that integrates throat muscle vibrations and carotid pulse signal sensors with large language model (LLM) processing to enable fluent, emotionally expressive communication. The system utilizes ultrasensitive textile strain sensors to capture high-quality signals from the neck area and supports token-level processing for real-time, continuous speech decoding, enabling seamless, delay-free communication. In tests with five stroke patients with dysarthria, IT's LLM agents intelligently corrected token errors and enriched sentence-level emotional and logical coherence, achieving low error rates (4.2% word error rate, 2.9% sentence error rate) and a 55% increase in user satisfaction. This work establishes a portable, intuitive communication platform for patients with dysarthria with the potential to be applied broadly across different neurological conditions and in multi-language support systems.
ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving
Apr 25, 2024



Diffusion-based technologies have made significant strides, particularly in personalized and customized facialgeneration. However, existing methods face challenges in achieving high-fidelity and detailed identity (ID)consistency, primarily due to insufficient fine-grained control over facial areas and the lack of a comprehensive strategy for ID preservation by fully considering intricate facial details and the overall face. To address these limitations, we introduce ConsistentID, an innovative method crafted for diverseidentity-preserving portrait generation under fine-grained multimodal facial prompts, utilizing only a single reference image. ConsistentID comprises two key components: a multimodal facial prompt generator that combines facial features, corresponding facial descriptions and the overall facial context to enhance precision in facial details, and an ID-preservation network optimized through the facial attention localization strategy, aimed at preserving ID consistency in facial regions. Together, these components significantly enhance the accuracy of ID preservation by introducing fine-grained multimodal ID information from facial regions. To facilitate training of ConsistentID, we present a fine-grained portrait dataset, FGID, with over 500,000 facial images, offering greater diversity and comprehensiveness than existing public facial datasets. % such as LAION-Face, CelebA, FFHQ, and SFHQ. Experimental results substantiate that our ConsistentID achieves exceptional precision and diversity in personalized facial generation, surpassing existing methods in the MyStyle dataset. Furthermore, while ConsistentID introduces more multimodal ID information, it maintains a fast inference speed during generation.