 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything Can Be Described in Words: A Simple Unified Multi-Modal Framework with Semantic and Temporal Alignment
Mar 12, 2025Long Video Question Answering (LVQA) is challenging due to the need for temporal reasoning and large-scale multimodal data processing. Existing methods struggle with retrieving cross-modal information from long videos, especially when relevant details are sparsely distributed. We introduce UMaT (Unified Multi-modal as Text), a retrieval-augmented generation (RAG) framework that efficiently processes extremely long videos while maintaining cross-modal coherence. UMaT converts visual and auditory data into a unified textual representation, ensuring semantic and temporal alignment. Short video clips are analyzed using a vision-language model, while automatic speech recognition (ASR) transcribes dialogue. These text-based representations are structured into temporally aligned segments, with adaptive filtering to remove redundancy and retain salient details. The processed data is embedded into a vector database, enabling precise retrieval of dispersed yet relevant content. Experiments on a benchmark LVQA dataset show that UMaT outperforms existing methods in multimodal integration, long-form video understanding, and sparse information retrieval. Its scalability and interpretability allow it to process videos over an hour long while maintaining semantic and temporal coherence. These findings underscore the importance of structured retrieval and multimodal synchronization for advancing LVQA and long-form AI systems.
Investigating the Effectiveness of a Socratic Chain-of-Thoughts Reasoning Method for Task Planning in Robotics, A Case Study
Mar 11, 2025Large language models (LLMs) have demonstrated unprecedented capability in reasoning with natural language. Coupled with this development is the emergence of embodied AI in robotics. Despite showing promise for verbal and written reasoning tasks, it remains unknown whether LLMs are capable of navigating complex spatial tasks with physical actions in the real world. To this end, it is of interest to investigate applying LLMs to robotics in zero-shot learning scenarios, and in the absence of fine-tuning - a feat which could significantly improve human-robot interaction, alleviate compute cost, and eliminate low-level programming tasks associated with robot tasks. To explore this question, we apply GPT-4(Omni) with a simulated Tiago robot in Webots engine for an object search task. We evaluate the effectiveness of three reasoning strategies based on Chain-of-Thought (CoT) sub-task list generation with the Socratic method (SocraCoT) (in order of increasing rigor): (1) Non-CoT/Non-SocraCoT, (2) CoT only, and (3) SocraCoT. Performance was measured in terms of the proportion of tasks successfully completed and execution time (N = 20). Our preliminary results show that when combined with chain-of-thought reasoning, the Socratic method can be used for code generation for robotic tasks that require spatial awareness. In extension of this finding, we propose EVINCE-LoC; a modified EVINCE method that could further enhance performance in highly complex and or dynamic testing scenarios.
Advanced Object Detection and Pose Estimation with Hybrid Task Cascade and High-Resolution Networks
Feb 06, 2025In the field of computer vision, 6D object detection and pose estimation are critical for applications such as robotics, augmented reality, and autonomous driving. Traditional methods often struggle with achieving high accuracy in both object detection and precise pose estimation simultaneously. This study proposes an improved 6D object detection and pose estimation pipeline based on the existing 6D-VNet framework, enhanced by integrating a Hybrid Task Cascade (HTC) and a High-Resolution Network (HRNet) backbone. By leveraging the strengths of HTC's multi-stage refinement process and HRNet's ability to maintain high-resolution representations, our approach significantly improves detection accuracy and pose estimation precision. Furthermore, we introduce advanced post-processing techniques and a novel model integration strategy that collectively contribute to superior performance on public and private benchmarks. Our method demonstrates substantial improvements over state-of-the-art models, making it a valuable contribution to the domain of 6D object detection and pose estimation.
Key Safety Design Overview in AI-driven Autonomous Vehicles
Dec 12, 2024

With the increasing presence of autonomous SAE level 3 and level 4, which incorporate artificial intelligence software, along with the complex technical challenges they present, it is essential to maintain a high level of functional safety and robust software design. This paper explores the necessary safety architecture and systematic approach for automotive software and hardware, including fail soft handling of automotive safety integrity level (ASIL) D (highest level of safety integrity), integration of artificial intelligence (AI), and machine learning (ML) in automotive safety architecture. By addressing the unique challenges presented by increasing AI-based automotive software, we proposed various techniques, such as mitigation strategies and safety failure analysis, to ensure the safety and reliability of automotive software, as well as the role of AI in software reliability throughout the data lifecycle. Index Terms Safety Design, Automotive Software, Performance Evaluation, Advanced Driver Assistance Systems (ADAS) Applications, Automotive Software Systems, Electronic Control Units.
Deformable spatial propagation network for depth completion
Jul 08, 2020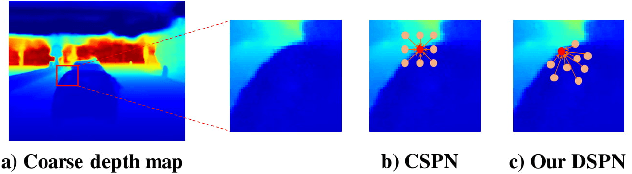

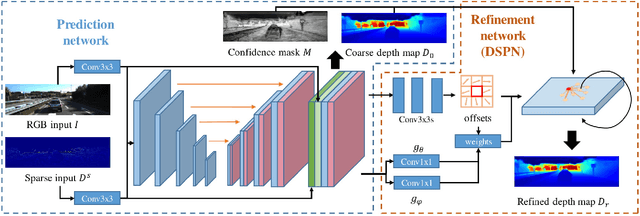
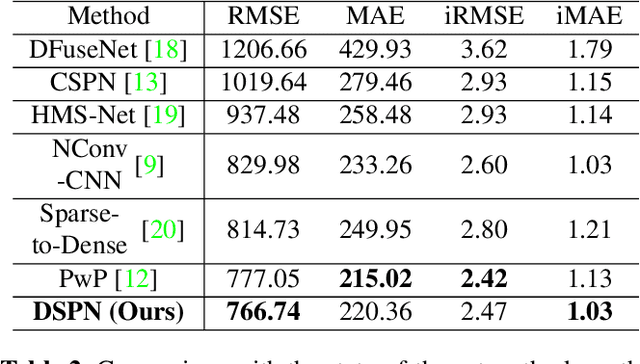
Depth completion has attracted extensive attention recently due to the development of autonomous driving, which aims to recover dense depth map from sparse depth measurements. Convolutional spatial propagation network (CSPN) is one of the state-of-the-art methods in this task, which adopt a linear propagation model to refine coarse depth maps with local context. However, the propagation of each pixel occurs in a fixed receptive field. This may not be the optimal for refinement since different pixel needs different local context. To tackle this issue, in this paper, we propose a deformable spatial propagation network (DSPN) to adaptively generates different receptive field and affinity matrix for each pixel. It allows the network obtain information with much fewer but more relevant pixels for propagation. Experimental results on KITTI depth completion benchmark demonstrate that our proposed method achieves the state-of-the-art performance.