 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Object Detection and Pose Estimation with Hybrid Task Cascade and High-Resolution Networks
Feb 06, 2025In the field of computer vision, 6D object detection and pose estimation are critical for applications such as robotics, augmented reality, and autonomous driving. Traditional methods often struggle with achieving high accuracy in both object detection and precise pose estimation simultaneously. This study proposes an improved 6D object detection and pose estimation pipeline based on the existing 6D-VNet framework, enhanced by integrating a Hybrid Task Cascade (HTC) and a High-Resolution Network (HRNet) backbone. By leveraging the strengths of HTC's multi-stage refinement process and HRNet's ability to maintain high-resolution representations, our approach significantly improves detection accuracy and pose estimation precision. Furthermore, we introduce advanced post-processing techniques and a novel model integration strategy that collectively contribute to superior performance on public and private benchmarks. Our method demonstrates substantial improvements over state-of-the-art models, making it a valuable contribution to the domain of 6D object detection and pose estimation.
Research on vehicle detection based on improved YOLOv8 network
Dec 31, 2024
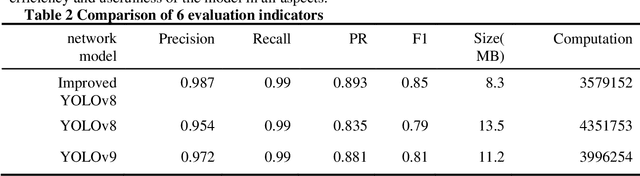
The key to ensuring the safe obstacle avoidance function of autonomous driving systems lies in the use of extremely accurate vehicle recognition techniques. However, the variability of the actual road environment and the diverse characteristics of vehicles and pedestrians together constitute a huge obstacle to improving detection accuracy, posing a serious challenge to the realization of this goal. To address the above issues, this paper proposes an improved YOLOv8 vehicle detection method. Specifically, taking the YOLOv8n-seg model as the base model, firstly, the FasterNet network is used to replace the backbone network to achieve the purpose of reducing the computational complexity and memory while improving the detection accuracy and speed; secondly, the feature enhancement is achieved by adding the attention mechanism CBAM to the Neck; and lastly, the loss function CIoU is modified to WIoU, which optimizes the detection box localization while improving the segmentation accuracy. The results show that the improved model achieves 98.3%, 89.1% and 88.4% detection accuracy for car, Person and Motorcycle. Compared with the pre-improvement and YOLOv9 models in six metrics such as Precision.