 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Integrated Transformer for Arbitrary-Scale Super-Resolution
Apr 26, 2025Methods based on implicit neural representation have demonstrated remarkable capabilities in arbitrary-scale super-resolution (ASSR) tasks, but they neglect the potential value of the frequency domain, leading to sub-optimal performance. We proposes a novel network called Frequency-Integrated Transformer (FIT) to incorporate and utilize frequency information to enhance ASSR performance. FIT employs Frequency Incorporation Module (FIM) to introduce frequency information in a lossless manner and Frequency Utilization Self-Attention module (FUSAM) to efficiently leverage frequency information by exploiting spatial-frequency interrelationship and global nature of frequency. FIM enriches detail characterization by incorporating frequency information through a combination of Fast Fourier Transform (FFT) with real-imaginary mapping. In FUSAM, Interaction Implicit Self-Attention (IISA) achieves cross-domain information synergy by interacting spatial and frequency information in subspace, while Frequency Correlation Self-attention (FCSA) captures the global context by computing correlation in frequency. Experimental results demonstrate FIT yields superior performance compared to existing methods across multiple benchmark datasets. Visual feature map proves the superiority of FIM in enriching detail characterization. Frequency error map validates IISA productively improve the frequency fidelity. Local attribution map validates FCSA effectively captures global context.
Multi-Scale Implicit Transformer with Re-parameterize for Arbitrary-Scale Super-Resolution
Mar 11, 2024



Recently, the methods based on implicit neural representations have shown excellent capabilities for arbitrary-scale super-resolution (ASSR). Although these methods represent the features of an image by generating latent codes, these latent codes are difficult to adapt for different magnification factors of super-resolution, which seriously affects their performance. Addressing this, we design Multi-Scale Implicit Transformer (MSIT), consisting of an Multi-scale Neural Operator (MSNO) and Multi-Scale Self-Attention (MSSA). Among them, MSNO obtains multi-scale latent codes through feature enhancement, multi-scale characteristics extraction, and multi-scale characteristics merging. MSSA further enhances the multi-scale characteristics of latent codes, resulting in better performance. Furthermore, to improve the performance of network, we propose the Re-Interaction Module (RIM) combined with the cumulative training strategy to improve the diversity of learned information for the network. We have systematically introduced multi-scale characteristics for the first time in ASSR, extensive experiments are performed to validate the effectiveness of MSIT, and our method achieves state-of-the-art performance in arbitrary super-resolution tasks.
Efficient Mixed Transformer for Single Image Super-Resolution
May 22, 2023
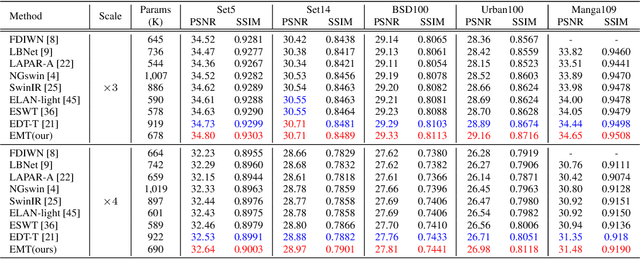
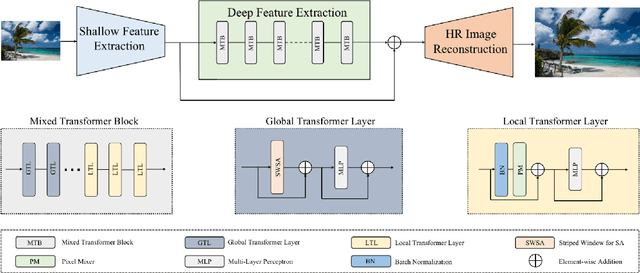

Recently, Transformer-based methods have achieved impressive results in single image super-resolution (SISR). However, the lack of locality mechanism and high complexity limit their application in the field of super-resolution (SR). To solve these problems, we propose a new method, Efficient Mixed Transformer (EMT) in this study. Specifically, we propose the Mixed Transformer Block (MTB), consisting of multiple consecutive transformer layers, in some of which the Pixel Mixer (PM) is used to replace the Self-Attention (SA). PM can enhance the local knowledge aggregation with pixel shifting operations. At the same time, no additional complexity is introduced as PM has no parameters and floating-point operations. Moreover, we employ striped window for SA (SWSA) to gain an efficient global dependency modelling by utilizing image anisotropy. Experimental results show that EMT outperforms the existing methods on benchmark dataset and achieved state-of-the-art performance. The Code is available at https://github. com/Fried-Rice-Lab/EMT.git.
Image Super-Resolution using Efficient Striped Window Transformer
Jan 24, 2023



Recently, transformer-based methods have made impressive progress in single-image super-resolu-tion (SR). However, these methods are difficult to apply to lightweight SR (LSR) due to the challenge of balancing model performance and complexity. In this paper, we propose an efficient striped window transformer (ESWT). ESWT consists of efficient transformation layers (ETLs), allowing a clean structure and avoiding redundant operations. Moreover, we designed a striped window mechanism to obtain a more efficient ESWT in modeling long-term dependencies. To further exploit the potential of the transformer, we propose a novel flexible window training strategy. Without any additional cost, this strategy can further improve the performance of ESWT. Extensive experiments show that the proposed method outperforms state-of-the-art transformer-based LSR methods with fewer parameters, faster inference, smaller FLOPs, and less memory consumption, achieving a better trade-off between model performance and complexity.