 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Mixed Transformer for Single Image Super-Resolution
May 22, 2023
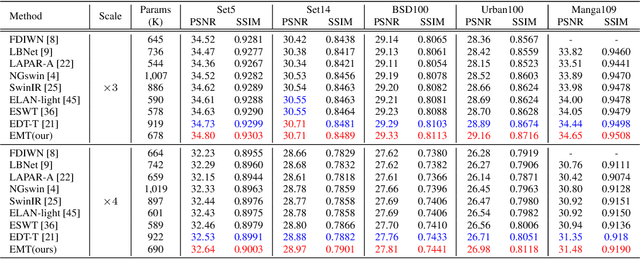
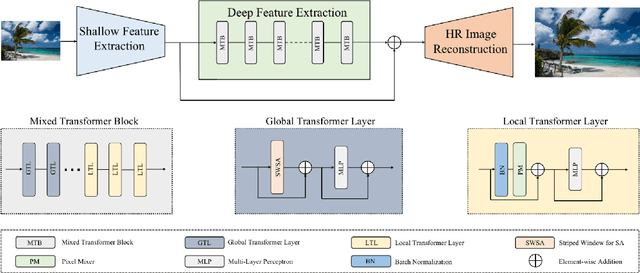

Recently, Transformer-based methods have achieved impressive results in single image super-resolution (SISR). However, the lack of locality mechanism and high complexity limit their application in the field of super-resolution (SR). To solve these problems, we propose a new method, Efficient Mixed Transformer (EMT) in this study. Specifically, we propose the Mixed Transformer Block (MTB), consisting of multiple consecutive transformer layers, in some of which the Pixel Mixer (PM) is used to replace the Self-Attention (SA). PM can enhance the local knowledge aggregation with pixel shifting operations. At the same time, no additional complexity is introduced as PM has no parameters and floating-point operations. Moreover, we employ striped window for SA (SWSA) to gain an efficient global dependency modelling by utilizing image anisotropy. Experimental results show that EMT outperforms the existing methods on benchmark dataset and achieved state-of-the-art performance. The Code is available at https://github. com/Fried-Rice-Lab/EMT.git.
Image Super-Resolution using Efficient Striped Window Transformer
Jan 24, 2023



Recently, transformer-based methods have made impressive progress in single-image super-resolu-tion (SR). However, these methods are difficult to apply to lightweight SR (LSR) due to the challenge of balancing model performance and complexity. In this paper, we propose an efficient striped window transformer (ESWT). ESWT consists of efficient transformation layers (ETLs), allowing a clean structure and avoiding redundant operations. Moreover, we designed a striped window mechanism to obtain a more efficient ESWT in modeling long-term dependencies. To further exploit the potential of the transformer, we propose a novel flexible window training strategy. Without any additional cost, this strategy can further improve the performance of ESWT. Extensive experiments show that the proposed method outperforms state-of-the-art transformer-based LSR methods with fewer parameters, faster inference, smaller FLOPs, and less memory consumption, achieving a better trade-off between model performance and complexity.