 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Nonlinear Shrinkage of Covariance Matrices for Minimum Variance Portfolio Optimization
Jan 22, 2026This paper introduces a neural network-based nonlinear shrinkage estimator of covariance matrices for the purpose of minimum variance portfolio optimization. It is a hybrid approach that integrates statistical estimation with machine learning. Starting from the Ledoit-Wolf (LW) shrinkage estimator, we decompose the LW covariance matrix into its eigenvalues and eigenvectors, and apply a lightweight transformer-based neural network to learn a nonlinear eigenvalue shrinkage function. Trained with portfolio risk as the loss function, the resulting precision matrix (the inverse covariance matrix) estimator directly targets portfolio risk minimization. By conditioning on the sample-to-dimension ratio, the approach remains scalable across different sample sizes and asset universes. Empirical results on stock daily returns from Standard & Poor's 500 Index (S&P500) demonstrate that the proposed method consistently achieves lower out-of-sample realized risk than benchmark approaches. This highlights the promise of integrating structural statistical models with data-driven learning.
A Data Quality Assessment Framework for AI-enabled Wireless Communication
Dec 13, 2022



Using artificial intelligent (AI) to re-design and enhance the current wireless communication system is a promising pathway for the future sixth-generation (6G) wireless network. The performance of AI-enabled wireless communication depends heavily on the quality of wireless air-interface data. Although there are various approaches to data quality assessment (DQA) for different applications, none has been designed for wireless air-interface data. In this paper, we propose a DQA framework to measure the quality of wireless air-interface data from three aspects: similarity, diversity, and completeness. The similarity measures how close the considered datasets are in terms of their statistical distributions; the diversity measures how well-rounded a dataset is, while the completeness measures to what degree the considered dataset satisfies the required performance metrics in an application scenario. The proposed framework can be applied to various types of wireless air-interface data, such as channel state information (CSI), signal-to-interference-plus-noise ratio (SINR), reference signal received power (RSRP), etc. For simplicity, the validity of our proposed DQA framework is corroborated by applying it to CSI data and using similarity and diversity metrics to improve CSI compression and recovery in Massive MIMO systems.
Hypothesis Test Procedures for Detecting Leakage Signals in Water Pipeline Channels
Oct 24, 2022



We design statistical hypothesis tests for performing leak detection in water pipeline channels. By applying an appropriate model for signal propagation, we show that the detection problem becomes one of distinguishing signal from noise, with the noise being described by a multivariate Gaussian distribution with unknown covariance matrix. We first design a test procedure based on the generalized likelihood ratio test, which we show through simulations to offer appreciable leak detection performance gain over conventional approaches designed in an analogous context (for radar detection). Our proposed method requires estimation of the noise covariance matrix, which can become inaccurate under high-dimensional settings, and when the measurement data is scarce. To deal with this, we present a second leak detection method, which employs a regularized covariance matrix estimate. The regularization parameter is optimized for the leak detection application by applying results from large dimensional random matrix theory. This second proposed approach is shown to yield improved performance in leak detection compared with the first approach, at the expense of requiring higher computational complexity.
Understanding Adversarial Robustness Against On-manifold Adversarial Examples
Oct 02, 2022
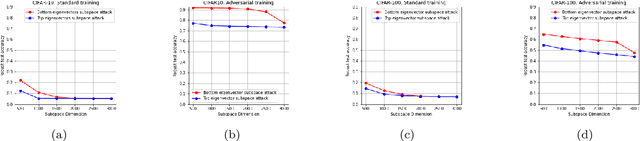
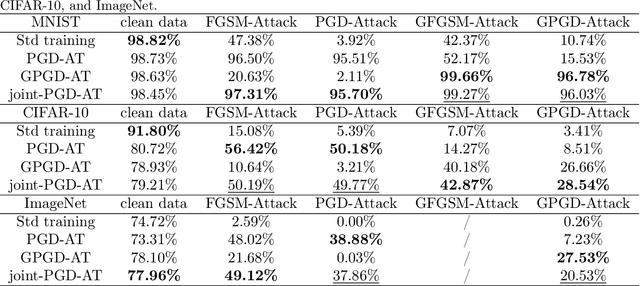
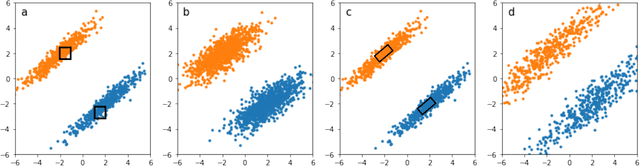
Deep neural networks (DNNs) are shown to be vulnerable to adversarial examples. A well-trained model can be easily attacked by adding small perturbations to the original data. One of the hypotheses of the existence of the adversarial examples is the off-manifold assumption: adversarial examples lie off the data manifold. However, recent research showed that on-manifold adversarial examples also exist. In this paper, we revisit the off-manifold assumption and want to study a question: at what level is the poor performance of neural networks against adversarial attacks due to on-manifold adversarial examples? Since the true data manifold is unknown in practice, we consider two approximated on-manifold adversarial examples on both real and synthesis datasets. On real datasets, we show that on-manifold adversarial examples have greater attack rates than off-manifold adversarial examples on both standard-trained and adversarially-trained models. On synthetic datasets, theoretically, We prove that on-manifold adversarial examples are powerful, yet adversarial training focuses on off-manifold directions and ignores the on-manifold adversarial examples. Furthermore, we provide analysis to show that the properties derived theoretically can also be observed in practice. Our analysis suggests that on-manifold adversarial examples are important, and we should pay more attention to on-manifold adversarial examples for training robust models.
Optimally Combining Classifiers for Semi-Supervised Learning
Jun 07, 2020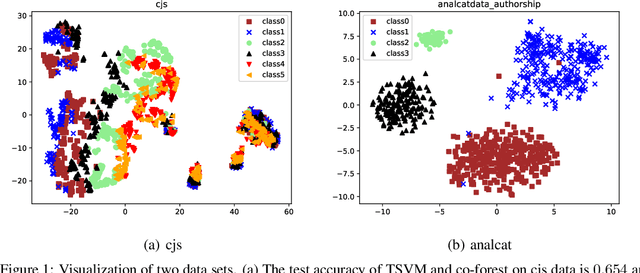

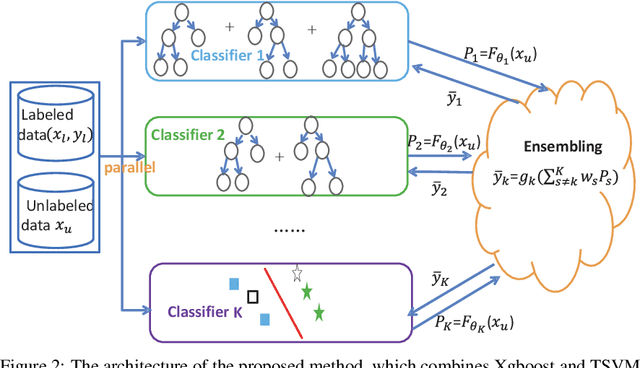
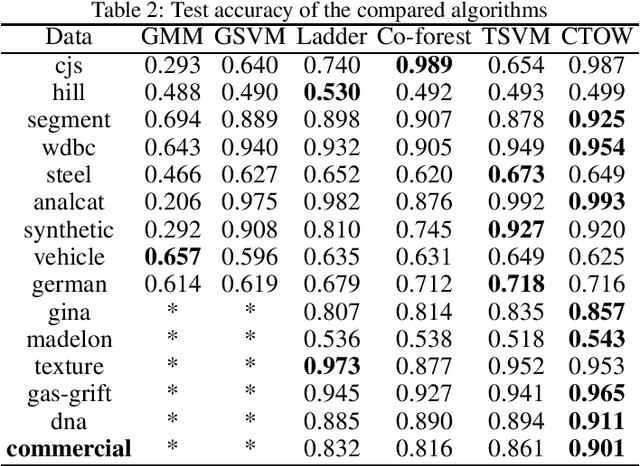
This paper considers semi-supervised learning for tabular data. It is widely known that Xgboost based on tree model works well on the heterogeneous features while transductive support vector machine can exploit the low density separation assumption. However, little work has been done to combine them together for the end-to-end semi-supervised learning. In this paper, we find these two methods have complementary properties and larger diversity, which motivates us to propose a new semi-supervised learning method that is able to adaptively combine the strengths of Xgboost and transductive support vector machine. Instead of the majority vote rule, an optimization problem in terms of ensemble weight is established, which helps to obtain more accurate pseudo labels for unlabeled data. The experimental results on the UCI data sets and real commercial data set demonstrate the superior classification performance of our method over the five state-of-the-art algorithms improving test accuracy by about $3\%-4\%$. The partial code can be found at https://github.com/hav-cam-mit/CTO.