 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally Combining Classifiers for Semi-Supervised Learning
Paper and Code
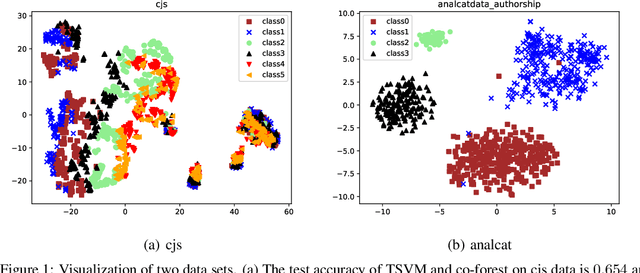

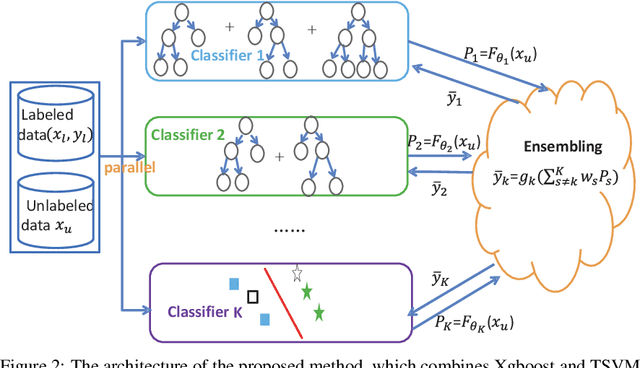
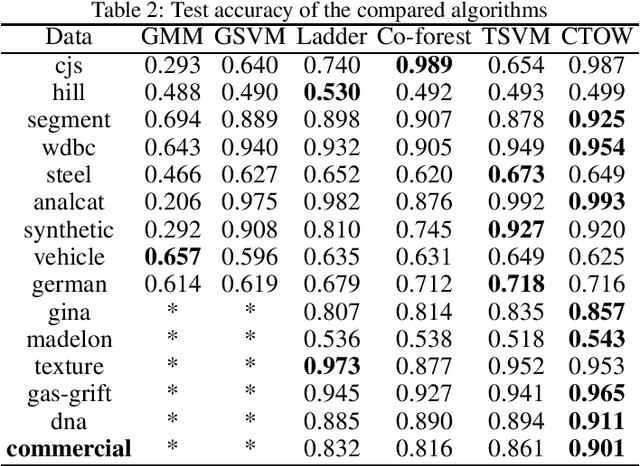
This paper considers semi-supervised learning for tabular data. It is widely known that Xgboost based on tree model works well on the heterogeneous features while transductive support vector machine can exploit the low density separation assumption. However, little work has been done to combine them together for the end-to-end semi-supervised learning. In this paper, we find these two methods have complementary properties and larger diversity, which motivates us to propose a new semi-supervised learning method that is able to adaptively combine the strengths of Xgboost and transductive support vector machine. Instead of the majority vote rule, an optimization problem in terms of ensemble weight is established, which helps to obtain more accurate pseudo labels for unlabeled data. The experimental results on the UCI data sets and real commercial data set demonstrate the superior classification performance of our method over the five state-of-the-art algorithms improving test accuracy by about $3\%-4\%$. The partial code can be found at https://github.com/hav-cam-mit/CTO.