 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Adversarial Robustness Against On-manifold Adversarial Examples
Paper and Code
Oct 02, 2022
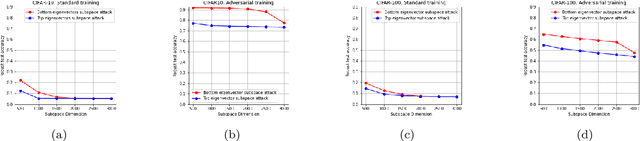
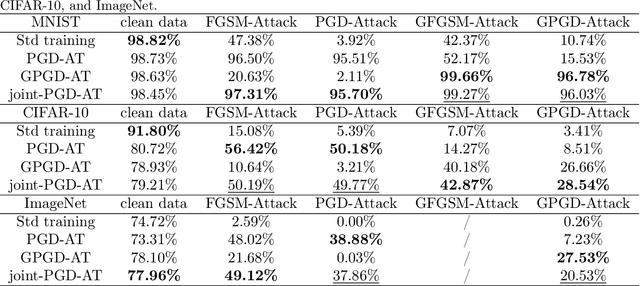
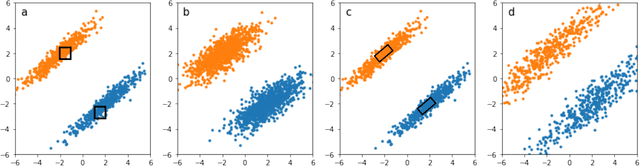
Deep neural networks (DNNs) are shown to be vulnerable to adversarial examples. A well-trained model can be easily attacked by adding small perturbations to the original data. One of the hypotheses of the existence of the adversarial examples is the off-manifold assumption: adversarial examples lie off the data manifold. However, recent research showed that on-manifold adversarial examples also exist. In this paper, we revisit the off-manifold assumption and want to study a question: at what level is the poor performance of neural networks against adversarial attacks due to on-manifold adversarial examples? Since the true data manifold is unknown in practice, we consider two approximated on-manifold adversarial examples on both real and synthesis datasets. On real datasets, we show that on-manifold adversarial examples have greater attack rates than off-manifold adversarial examples on both standard-trained and adversarially-trained models. On synthetic datasets, theoretically, We prove that on-manifold adversarial examples are powerful, yet adversarial training focuses on off-manifold directions and ignores the on-manifold adversarial examples. Furthermore, we provide analysis to show that the properties derived theoretically can also be observed in practice. Our analysis suggests that on-manifold adversarial examples are important, and we should pay more attention to on-manifold adversarial examples for training robust models.