 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Training for Selective Prediction
Paper and Code
Oct 31, 2024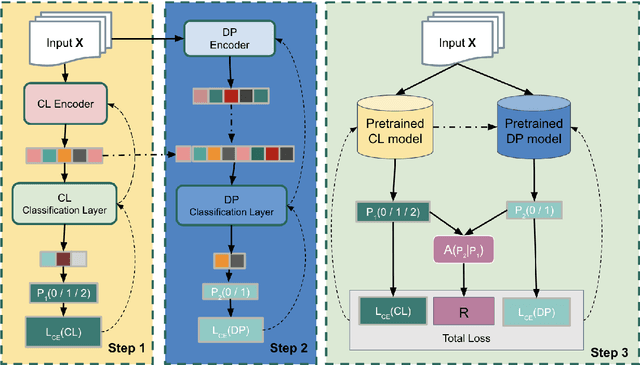
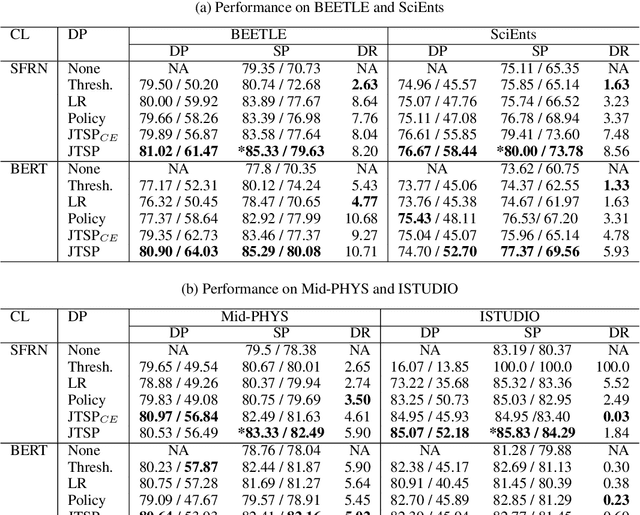

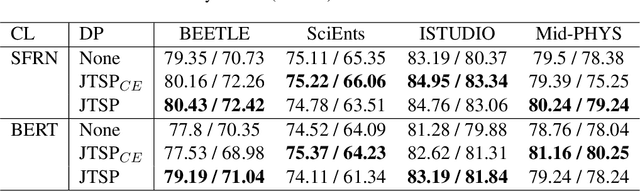
Classifier models are prevalent in natural language processing (NLP), often with high accuracy. Yet in real world settings, human-in-the-loop systems can foster trust in model outputs and even higher performance. Selective Prediction (SP) methods determine when to adopt a classifier's output versus defer to a human. Previous SP approaches have addressed how to improve softmax as a measure of model confidence, or have developed separate confidence estimators. One previous method involves learning a deferral model based on engineered features. We introduce a novel joint-training approach that simultaneously optimizes learned representations used by the classifier module and a learned deferral policy. Our results on four classification tasks demonstrate that joint training not only leads to better SP outcomes over two strong baselines, but also improves the performance of both modules.