 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONTaiNER: Few-Shot Named Entity Recognition via Contrastive Learning
Sep 15, 2021
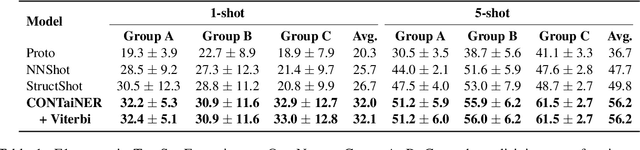
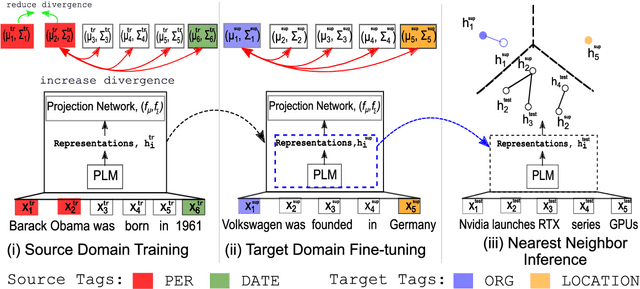
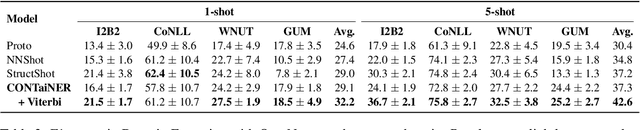
Named Entity Recognition (NER) in Few-Shot setting is imperative for entity tagging in low resource domains. Existing approaches only learn class-specific semantic features and intermediate representations from source domains. This affects generalizability to unseen target domains, resulting in suboptimal performances. To this end, we present CONTaiNER, a novel contrastive learning technique that optimizes the inter-token distribution distance for Few-Shot NER. Instead of optimizing class-specific attributes, CONTaiNER optimizes a generalized objective of differentiating between token categories based on their Gaussian-distributed embeddings. This effectively alleviates overfitting issues originating from training domains. Our experiments in several traditional test domains (OntoNotes, CoNLL'03, WNUT '17, GUM) and a new large scale Few-Shot NER dataset (Few-NERD) demonstrate that on average, CONTaiNER outperforms previous methods by 3%-13% absolute F1 points while showing consistent performance trends, even in challenging scenarios where previous approaches could not achieve appreciable performance.
NePTuNe: Neural Powered Tucker Network for Knowledge Graph Completion
Apr 15, 2021
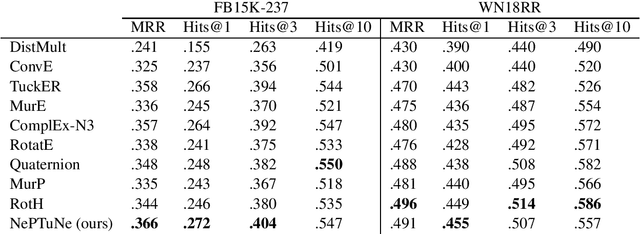
Knowledge graphs link entities through relations to provide a structured representation of real world facts. However, they are often incomplete, because they are based on only a small fraction of all plausible facts. The task of knowledge graph completion via link prediction aims to overcome this challenge by inferring missing facts represented as links between entities. Current approaches to link prediction leverage tensor factorization and/or deep learning. Factorization methods train and deploy rapidly thanks to their small number of parameters but have limited expressiveness due to their underlying linear methodology. Deep learning methods are more expressive but also computationally expensive and prone to overfitting due to their large number of trainable parameters. We propose Neural Powered Tucker Network (NePTuNe), a new hybrid link prediction model that couples the expressiveness of deep models with the speed and size of linear models. We demonstrate that NePTuNe provides state-of-the-art performance on the FB15K-237 dataset and near state-of-the-art performance on the WN18RR dataset.
Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning
Oct 06, 2020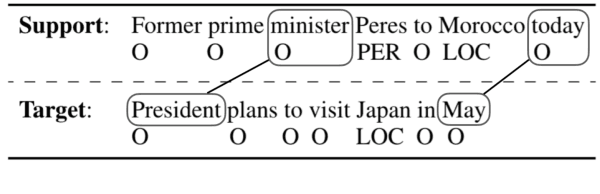

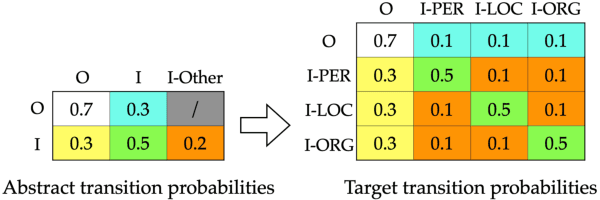
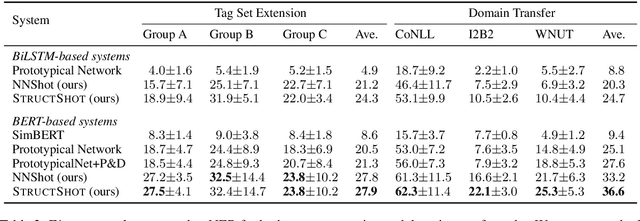
We present a simple few-shot named entity recognition (NER) system based on nearest neighbor learning and structured inference. Our system uses a supervised NER model trained on the source domain, as a feature extractor. Across several test domains, we show that a nearest neighbor classifier in this feature-space is far more effective than the standard meta-learning approaches. We further propose a cheap but effective method to capture the label dependencies between entity tags without expensive CRF training. We show that our method of combining structured decoding with nearest neighbor learning achieves state-of-the-art performance on standard few-shot NER evaluation tasks, improving F1 scores by $6\%$ to $16\%$ absolute points over prior meta-learning based systems.
Revisiting Few-sample BERT Fine-tuning
Jul 02, 2020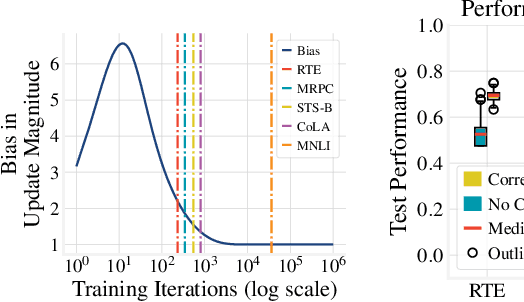
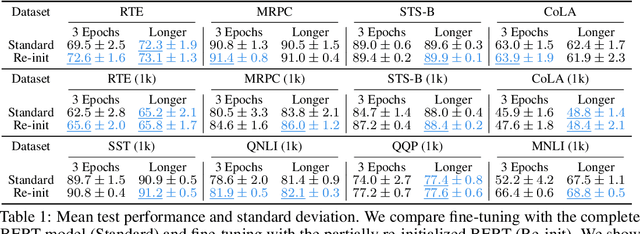

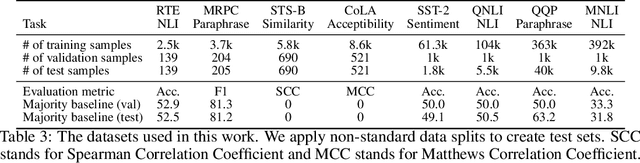
We study the problem of few-sample fine-tuning of BERT contextual representations, and identify three sub-optimal choices in current, broadly adopted practices. First, we observe that the omission of the gradient bias correction in the BERTAdam optimizer results in fine-tuning instability. We also find that parts of the BERT network provide a detrimental starting point for fine-tuning, and simply re-initializing these layers speeds up learning and improves performance. Finally, we study the effect of training time, and observe that commonly used recipes often do not allocate sufficient time for training. In light of these findings, we re-visit recently proposed methods to improve few-sample fine-tuning with BERT and re-evaluate their effectiveness. Generally, we observe a decrease in their relative impact when modifying the fine-tuning process based on our findings.