 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Few-sample BERT Fine-tuning
Paper and Code
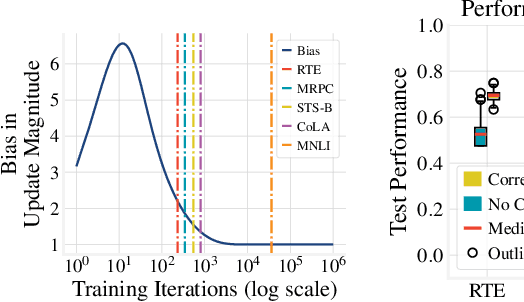
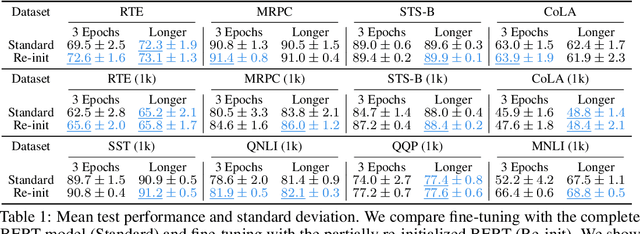

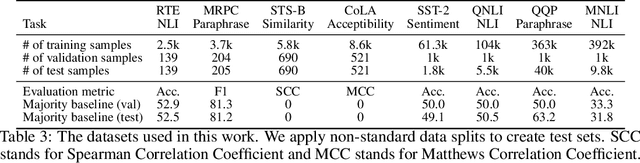
We study the problem of few-sample fine-tuning of BERT contextual representations, and identify three sub-optimal choices in current, broadly adopted practices. First, we observe that the omission of the gradient bias correction in the BERTAdam optimizer results in fine-tuning instability. We also find that parts of the BERT network provide a detrimental starting point for fine-tuning, and simply re-initializing these layers speeds up learning and improves performance. Finally, we study the effect of training time, and observe that commonly used recipes often do not allocate sufficient time for training. In light of these findings, we re-visit recently proposed methods to improve few-sample fine-tuning with BERT and re-evaluate their effectiveness. Generally, we observe a decrease in their relative impact when modifying the fine-tuning process based on our findings.