 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Governing Knowledge Commons and Contextual Integrity (GKC-CI) Privacy Policy Annotations with Large Language Models
Nov 03, 2023Identifying contextual integrity (CI) and governing knowledge commons (GKC) parameters in privacy policy texts can facilitate normative privacy analysis. However, GKC-CI annotation has heretofore required manual or crowdsourced effort. This paper demonstrates that high-accuracy GKC-CI parameter annotation of privacy policies can be performed automatically using large language models. We fine-tune 18 open-source and proprietary models on 21,588 GKC-CI annotations from 16 ground truth privacy policies. Our best-performing model (fine-tuned GPT-3.5 Turbo with prompt engineering) has an accuracy of 86%, exceeding the performance of prior crowdsourcing approaches despite the complexity of privacy policy texts and the nuance of the GKC-CI annotation task. We apply our best-performing model to privacy policies from 164 popular online services, demonstrating the effectiveness of scaling GKC-CI annotation for data exploration. We make all annotated policies as well as the training data and scripts needed to fine-tune our best-performing model publicly available for future research.
Automating Internet of Things Network Traffic Collection with Robotic Arm Interactions
Sep 30, 2021

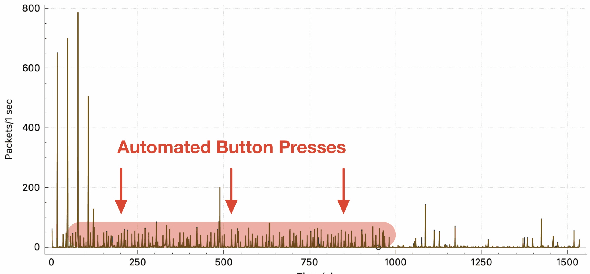
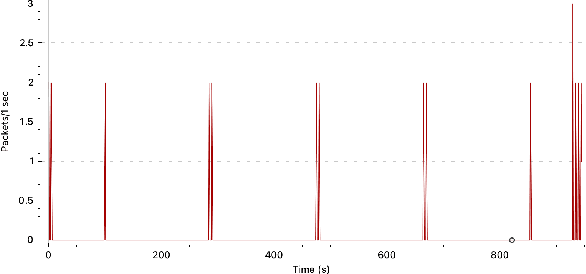
Consumer Internet of things research often involves collecting network traffic sent or received by IoT devices. These data are typically collected via crowdsourcing or while researchers manually interact with IoT devices in a laboratory setting. However, manual interactions and crowdsourcing are often tedious, expensive, inaccurate, or do not provide comprehensive coverage of possible IoT device behaviors. We present a new method for generating IoT network traffic using a robotic arm to automate user interactions with devices. This eliminates manual button pressing and enables permutation-based interaction sequences that rigorously explore the range of possible device behaviors. We test this approach with an Arduino-controlled robotic arm, a smart speaker and a smart thermostat, using machine learning to demonstrate that collected network traffic contains information about device interactions that could be useful for network, security, or privacy analyses. We also provide source code and documentation allowing researchers to easily automate IoT device interactions and network traffic collection in future studies.
SkillBot: Identifying Risky Content for Children in Alexa Skills
Feb 05, 2021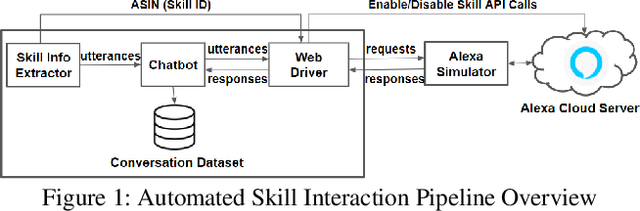
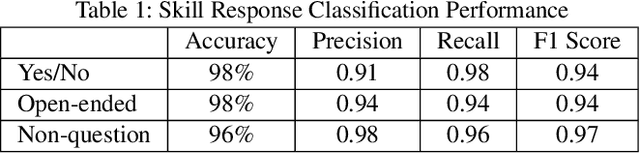


Many households include children who use voice personal assistants (VPA) such as Amazon Alexa. Children benefit from the rich functionalities of VPAs and third-party apps but are also exposed to new risks in the VPA ecosystem (e.g., inappropriate content or information collection). To study the risks VPAs pose to children, we build a Natural Language Processing (NLP)-based system to automatically interact with VPA apps and analyze the resulting conversations to identify contents risky to children. We identify 28 child-directed apps with risky contents and maintain a growing dataset of 31,966 non-overlapping app behaviors collected from 3,434 Alexa apps. Our findings suggest that although voice apps designed for children are subject to more policy requirements and intensive vetting, children are still vulnerable to risky content. We then conduct a user study showing that parents are more concerned about VPA apps with inappropriate content than those that ask for personal information, but many parents are not aware that risky apps of either type exist. Finally, we identify a new threat to users of VPA apps: confounding utterances, or voice commands shared by multiple apps that may cause a user to invoke or interact with a different app than intended. We identify 4,487 confounding utterances, including 581 shared by child-directed and non-child-directed apps.
Detecting Compressed Cleartext Traffic from Consumer Internet of Things Devices
May 07, 2018
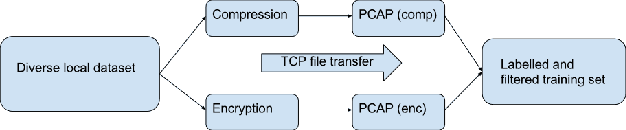


Data encryption is the primary method of protecting the privacy of consumer device Internet communications from network observers. The ability to automatically detect unencrypted data in network traffic is therefore an essential tool for auditing Internet-connected devices. Existing methods identify network packets containing cleartext but cannot differentiate packets containing encrypted data from packets containing compressed unencrypted data, which can be easily recovered by reversing the compression algorithm. This makes it difficult for consumer protection advocates to identify devices that risk user privacy by sending sensitive data in a compressed unencrypted format. Here, we present the first technique to automatically distinguish encrypted from compressed unencrypted network transmissions on a per-packet basis. We apply three machine learning models and achieve a maximum 66.9% accuracy with a convolutional neural network trained on raw packet data. This result is a baseline for this previously unstudied machine learning problem, which we hope will motivate further attention and accuracy improvements. To facilitate continuing research on this topic, we have made our training and test datasets available to the public.
Machine Learning DDoS Detection for Consumer Internet of Things Devices
Apr 11, 2018

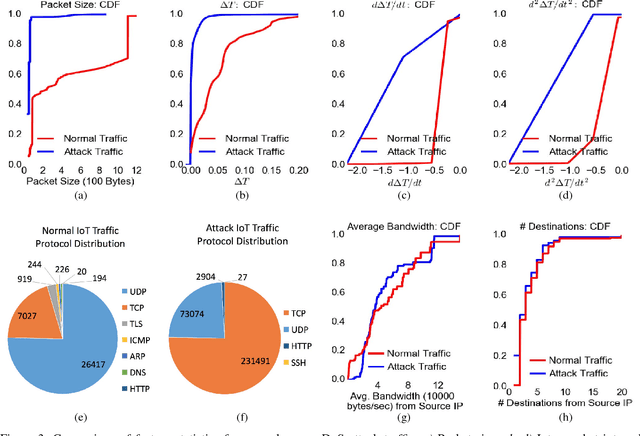
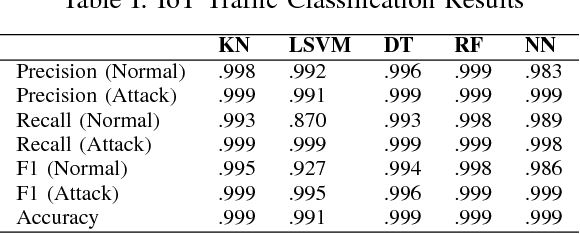
An increasing number of Internet of Things (IoT) devices are connecting to the Internet, yet many of these devices are fundamentally insecure, exposing the Internet to a variety of attacks. Botnets such as Mirai have used insecure consumer IoT devices to conduct distributed denial of service (DDoS) attacks on critical Internet infrastructure. This motivates the development of new techniques to automatically detect consumer IoT attack traffic. In this paper, we demonstrate that using IoT-specific network behaviors (e.g. limited number of endpoints and regular time intervals between packets) to inform feature selection can result in high accuracy DDoS detection in IoT network traffic with a variety of machine learning algorithms, including neural networks. These results indicate that home gateway routers or other network middleboxes could automatically detect local IoT device sources of DDoS attacks using low-cost machine learning algorithms and traffic data that is flow-based and protocol-agnostic.