 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman mobility is well described by closed-form gravity-like models learned automatically from data
Dec 18, 2023Modeling of human mobility is critical to address questions in urban planning and transportation, as well as global challenges in sustainability, public health, and economic development. However, our understanding and ability to model mobility flows within and between urban areas are still incomplete. At one end of the modeling spectrum we have simple so-called gravity models, which are easy to interpret and provide modestly accurate predictions of mobility flows. At the other end, we have complex machine learning and deep learning models, with tens of features and thousands of parameters, which predict mobility more accurately than gravity models at the cost of not being interpretable and not providing insight on human behavior. Here, we show that simple machine-learned, closed-form models of mobility are able to predict mobility flows more accurately, overall, than either gravity or complex machine and deep learning models. At the same time, these models are simple and gravity-like, and can be interpreted in terms similar to standard gravity models. Furthermore, these models work for different datasets and at different scales, suggesting that they may capture the fundamental universal features of human mobility.
Identifying latent activity behaviors and lifestyles using mobility data to describe urban dynamics
Sep 24, 2022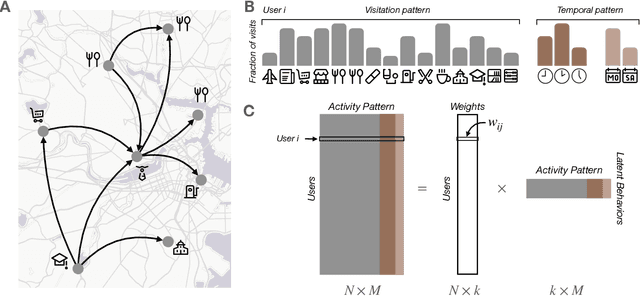
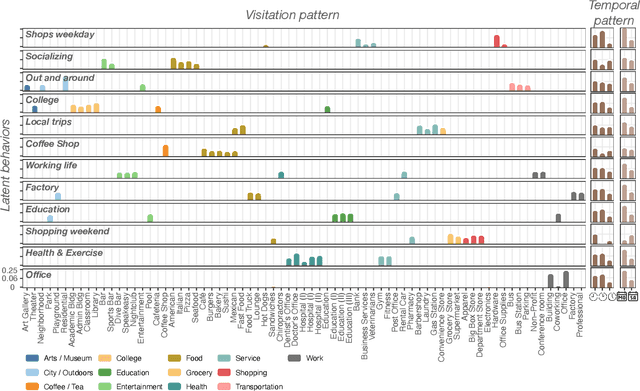
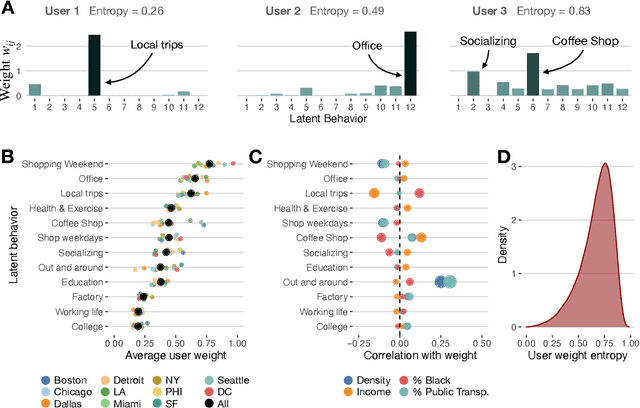
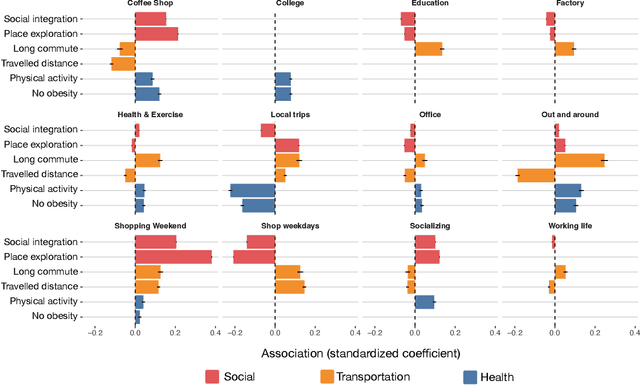
Urbanization and its problems require an in-depth and comprehensive understanding of urban dynamics, especially the complex and diversified lifestyles in modern cities. Digitally acquired data can accurately capture complex human activity, but it lacks the interpretability of demographic data. In this paper, we study a privacy-enhanced dataset of the mobility visitation patterns of 1.2 million people to 1.1 million places in 11 metro areas in the U.S. to detect the latent mobility behaviors and lifestyles in the largest American cities. Despite the considerable complexity of mobility visitations, we found that lifestyles can be automatically decomposed into only 12 latent interpretable activity behaviors on how people combine shopping, eating, working, or using their free time. Rather than describing individuals with a single lifestyle, we find that city dwellers' behavior is a mixture of those behaviors. Those detected latent activity behaviors are equally present across cities and cannot be fully explained by main demographic features. Finally, we find those latent behaviors are associated with dynamics like experienced income segregation, transportation, or healthy behaviors in cities, even after controlling for demographic features. Our results signal the importance of complementing traditional census data with activity behaviors to understand urban dynamics.
Generating synthetic mobility data for a realistic population with RNNs to improve utility and privacy
Jan 04, 2022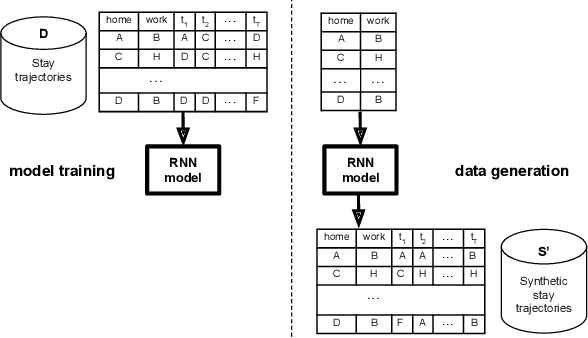
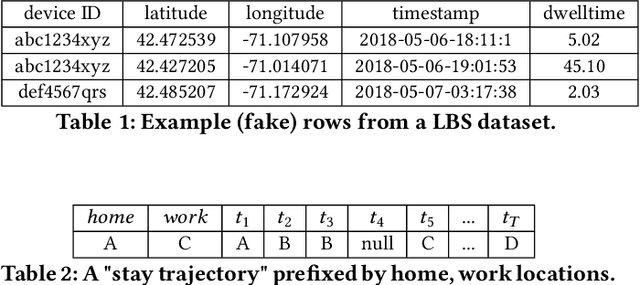
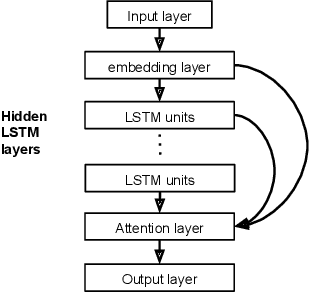
Location data collected from mobile devices represent mobility behaviors at individual and societal levels. These data have important applications ranging from transportation planning to epidemic modeling. However, issues must be overcome to best serve these use cases: The data often represent a limited sample of the population and use of the data jeopardizes privacy. To address these issues, we present and evaluate a system for generating synthetic mobility data using a deep recurrent neural network (RNN) which is trained on real location data. The system takes a population distribution as input and generates mobility traces for a corresponding synthetic population. Related generative approaches have not solved the challenges of capturing both the patterns and variability in individuals' mobility behaviors over longer time periods, while also balancing the generation of realistic data with privacy. Our system leverages RNNs' ability to generate complex and novel sequences while retaining patterns from training data. Also, the model introduces randomness used to calibrate the variation between the synthetic and real data at the individual level. This is to both capture variability in human mobility, and protect user privacy. Location based services (LBS) data from more than 22,700 mobile devices were used in an experimental evaluation across utility and privacy metrics. We show the generated mobility data retain the characteristics of the real data, while varying from the real data at the individual level, and where this amount of variation matches the variation within the real data.
Communication Topologies Between Learning Agents in Deep Reinforcement Learning
Feb 16, 2019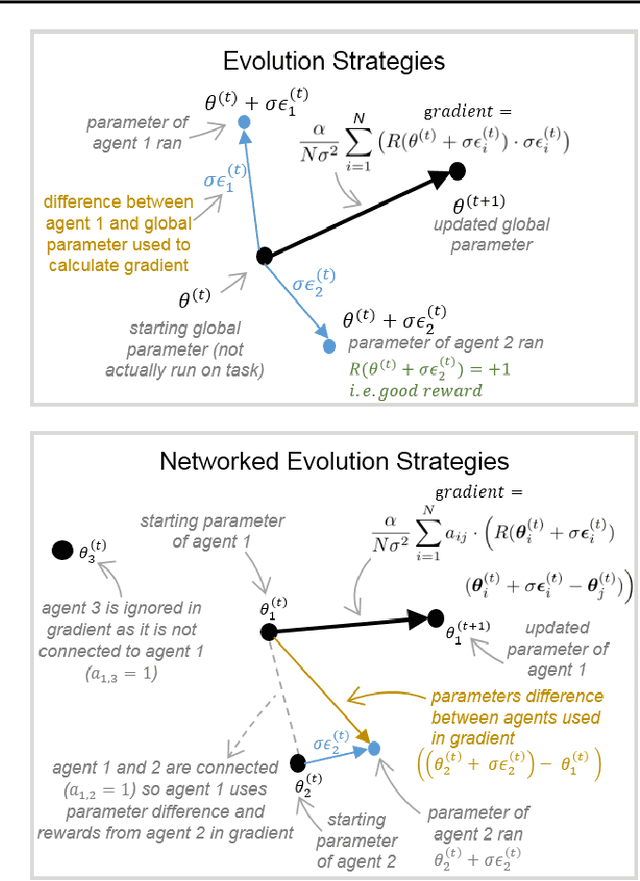

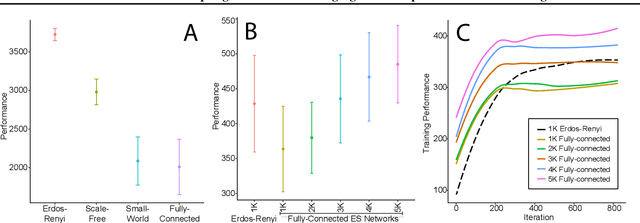
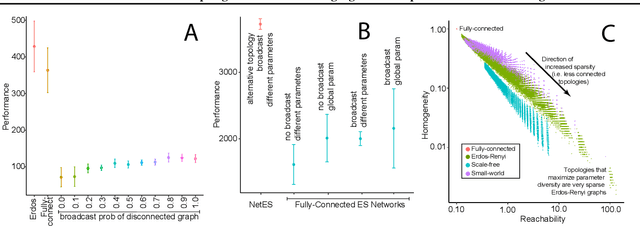
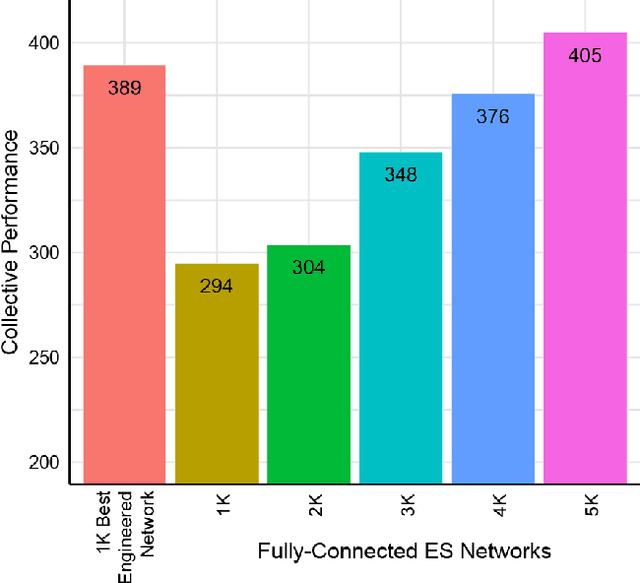
A common technique to improve speed and robustness of learning in deep reinforcement learning (DRL) and many other machine learning algorithms is to run multiple learning agents in parallel. A neglected component in the development of these algorithms has been how best to arrange the learning agents involved to better facilitate distributed search. Here we draw upon results from the networked optimization and collective intelligence literatures suggesting that arranging learning agents in less than fully connected topologies (the implicit way agents are commonly arranged in) can improve learning. We explore the relative performance of four popular families of graphs and observe that one such family (Erdos-Renyi random graphs) empirically outperforms the standard fully-connected communication topology across several DRL benchmark tasks. We observe that 1000 learning agents arranged in an Erdos-Renyi graph can perform as well as 3000 agents arranged in the standard fully-connected topology, showing the large learning improvement possible when carefully designing the topology over which agents communicate. We complement these empirical results with a preliminary theoretical investigation of why less than fully connected topologies can perform better. Overall, our work suggests that distributed machine learning algorithms could be made more efficient if the communication topology between learning agents was optimized.
How to Organize your Deep Reinforcement Learning Agents: The Importance of Communication Topology
Nov 30, 2018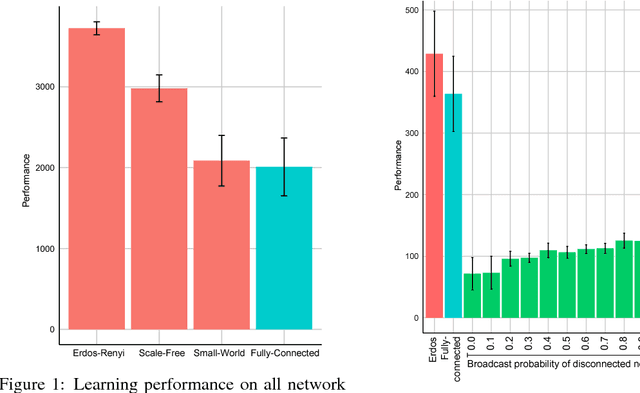

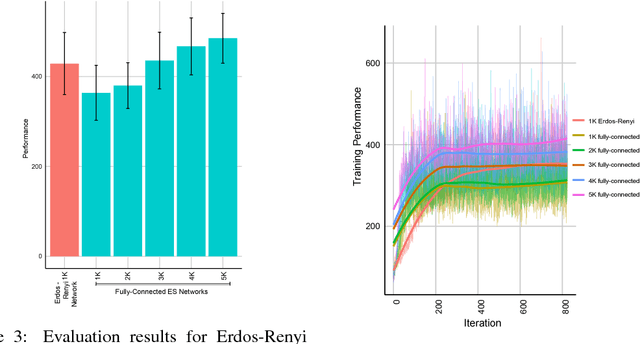
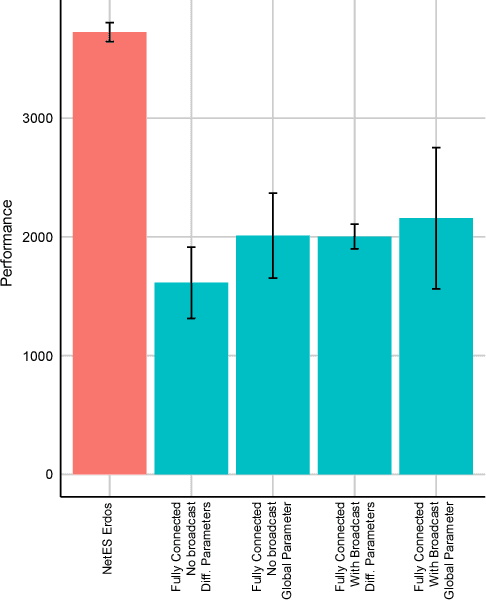
In this empirical paper, we investigate how learning agents can be arranged in more efficient communication topologies for improved learning. This is an important problem because a common technique to improve speed and robustness of learning in deep reinforcement learning and many other machine learning algorithms is to run multiple learning agents in parallel. The standard communication architecture typically involves all agents intermittently communicating with each other (fully connected topology) or with a centralized server (star topology). Unfortunately, optimizing the topology of communication over the space of all possible graphs is a hard problem, so we borrow results from the networked optimization and collective intelligence literatures which suggest that certain families of network topologies can lead to strong improvements over fully-connected networks. We start by introducing alternative network topologies to DRL benchmark tasks under the Evolution Strategies paradigm which we call Network Evolution Strategies. We explore the relative performance of the four main graph families and observe that one such family (Erdos-Renyi random graphs) empirically outperforms all other families, including the de facto fully-connected communication topologies. Additionally, the use of alternative network topologies has a multiplicative performance effect: we observe that when 1000 learning agents are arranged in a carefully designed communication topology, they can compete with 3000 agents arranged in the de facto fully-connected topology. Overall, our work suggests that distributed machine learning algorithms would learn more efficiently if the communication topology between learning agents was optimized.
MemeSequencer: Sparse Matching for Embedding Image Macros
Feb 14, 2018
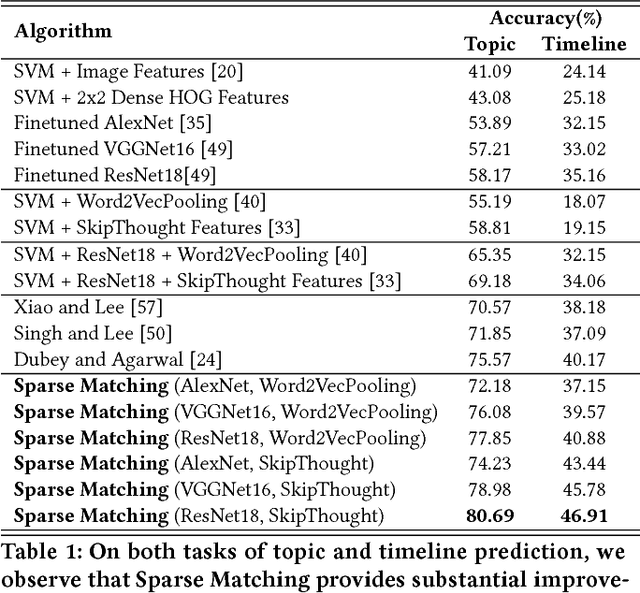

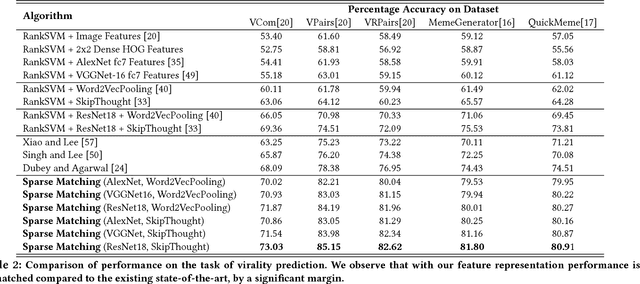
The analysis of the creation, mutation, and propagation of social media content on the Internet is an essential problem in computational social science, affecting areas ranging from marketing to political mobilization. A first step towards understanding the evolution of images online is the analysis of rapidly modifying and propagating memetic imagery or `memes'. However, a pitfall in proceeding with such an investigation is the current incapability to produce a robust semantic space for such imagery, capable of understanding differences in Image Macros. In this study, we provide a first step in the systematic study of image evolution on the Internet, by proposing an algorithm based on sparse representations and deep learning to decouple various types of content in such images and produce a rich semantic embedding. We demonstrate the benefits of our approach on a variety of tasks pertaining to memes and Image Macros, such as image clustering, image retrieval, topic prediction and virality prediction, surpassing the existing methods on each. In addition to its utility on quantitative tasks, our method opens up the possibility of obtaining the first large-scale understanding of the evolution and propagation of memetic imagery.
Improved Learning in Evolution Strategies via Sparser Inter-Agent Network Topologies
Nov 30, 2017

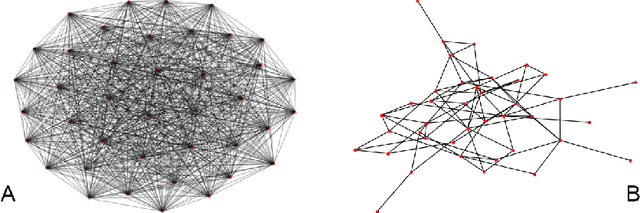
We draw upon a previously largely untapped literature on human collective intelligence as a source of inspiration for improving deep learning. Implicit in many algorithms that attempt to solve Deep Reinforcement Learning (DRL) tasks is the network of processors along which parameter values are shared. So far, existing approaches have implicitly utilized fully-connected networks, in which all processors are connected. However, the scientific literature on human collective intelligence suggests that complete networks may not always be the most effective information network structures for distributed search through complex spaces. Here we show that alternative topologies can improve deep neural network training: we find that sparser networks learn higher rewards faster, leading to learning improvements at lower communication costs.
Predicting human preferences using the block structure of complex social networks
Oct 03, 2012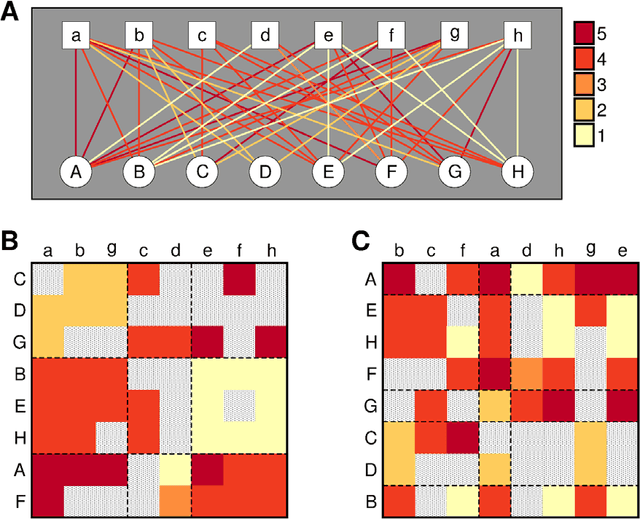
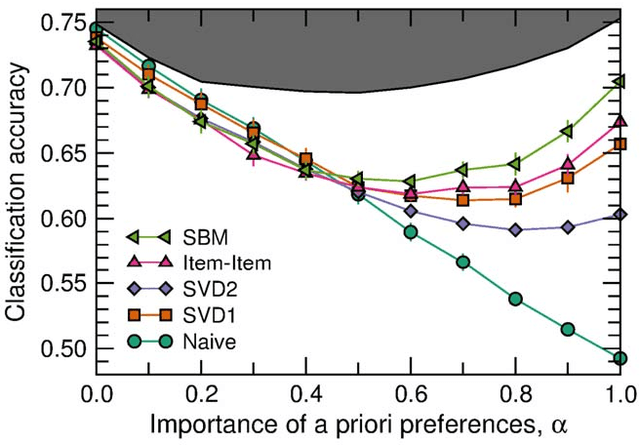
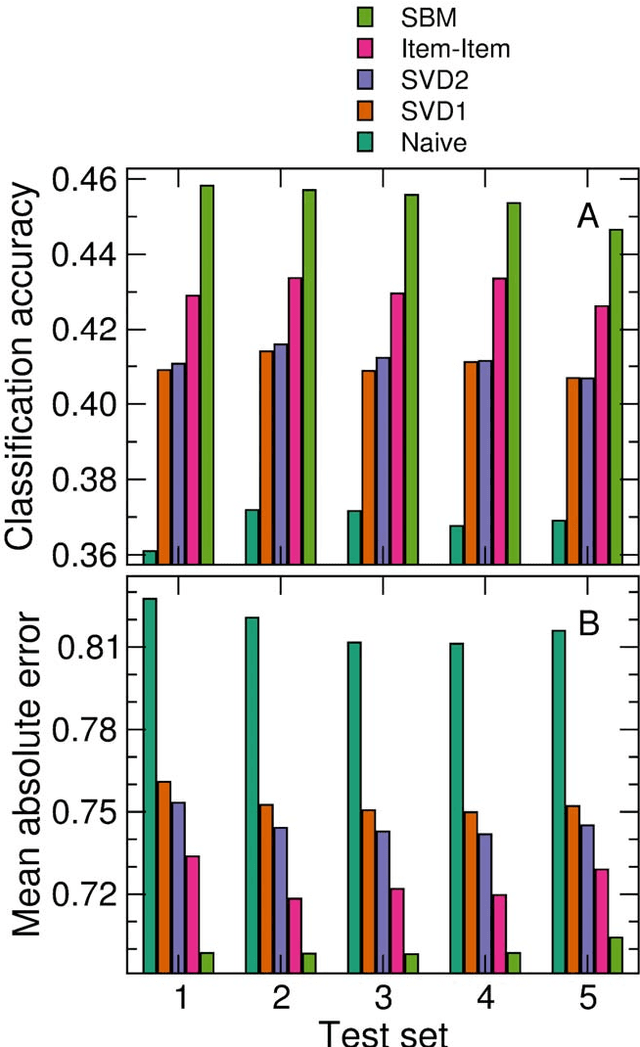
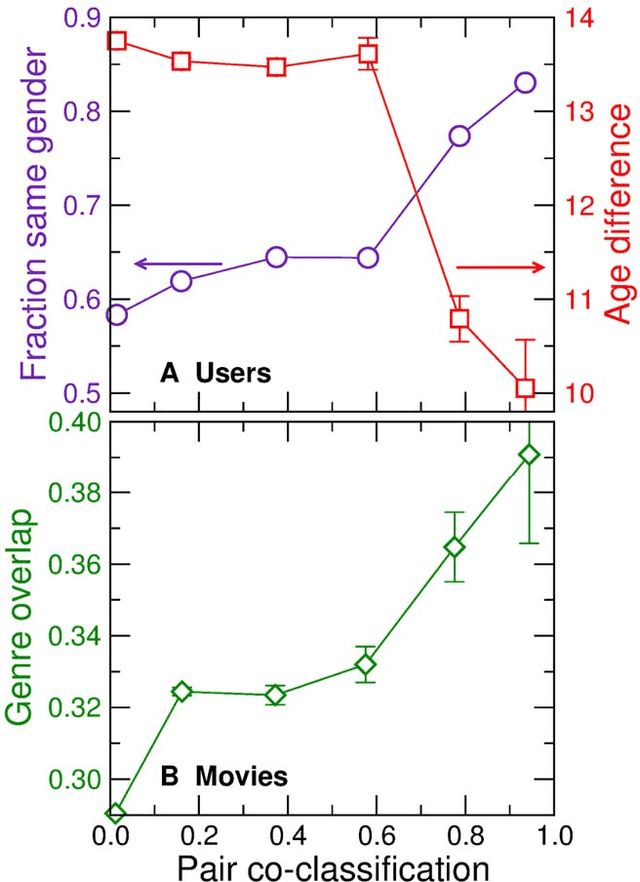
With ever-increasing available data, predicting individuals' preferences and helping them locate the most relevant information has become a pressing need. Understanding and predicting preferences is also important from a fundamental point of view, as part of what has been called a "new" computational social science. Here, we propose a novel approach based on stochastic block models, which have been developed by sociologists as plausible models of complex networks of social interactions. Our model is in the spirit of predicting individuals' preferences based on the preferences of others but, rather than fitting a particular model, we rely on a Bayesian approach that samples over the ensemble of all possible models. We show that our approach is considerably more accurate than leading recommender algorithms, with major relative improvements between 38% and 99% over industry-level algorithms. Besides, our approach sheds light on decision-making processes by identifying groups of individuals that have consistently similar preferences, and enabling the analysis of the characteristics of those groups.