 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA collaborative constrained graph diffusion model for the generation of realistic synthetic molecules
May 22, 2025



Developing new molecular compounds is crucial to address pressing challenges, from health to environmental sustainability. However, exploring the molecular space to discover new molecules is difficult due to the vastness of the space. Here we introduce CoCoGraph, a collaborative and constrained graph diffusion model capable of generating molecules that are guaranteed to be chemically valid. Thanks to the constraints built into the model and to the collaborative mechanism, CoCoGraph outperforms state-of-the-art approaches on standard benchmarks while requiring up to an order of magnitude fewer parameters. Analysis of 36 chemical properties also demonstrates that CoCoGraph generates molecules with distributions more closely matching real molecules than current models. Leveraging the model's efficiency, we created a database of 8.2M million synthetically generated molecules and conducted a Turing-like test with organic chemistry experts to further assess the plausibility of the generated molecules, and potential biases and limitations of CoCoGraph.
Human mobility is well described by closed-form gravity-like models learned automatically from data
Dec 18, 2023Modeling of human mobility is critical to address questions in urban planning and transportation, as well as global challenges in sustainability, public health, and economic development. However, our understanding and ability to model mobility flows within and between urban areas are still incomplete. At one end of the modeling spectrum we have simple so-called gravity models, which are easy to interpret and provide modestly accurate predictions of mobility flows. At the other end, we have complex machine learning and deep learning models, with tens of features and thousands of parameters, which predict mobility more accurately than gravity models at the cost of not being interpretable and not providing insight on human behavior. Here, we show that simple machine-learned, closed-form models of mobility are able to predict mobility flows more accurately, overall, than either gravity or complex machine and deep learning models. At the same time, these models are simple and gravity-like, and can be interpreted in terms similar to standard gravity models. Furthermore, these models work for different datasets and at different scales, suggesting that they may capture the fundamental universal features of human mobility.
Fundamental limits to learning closed-form mathematical models from data
Apr 06, 2022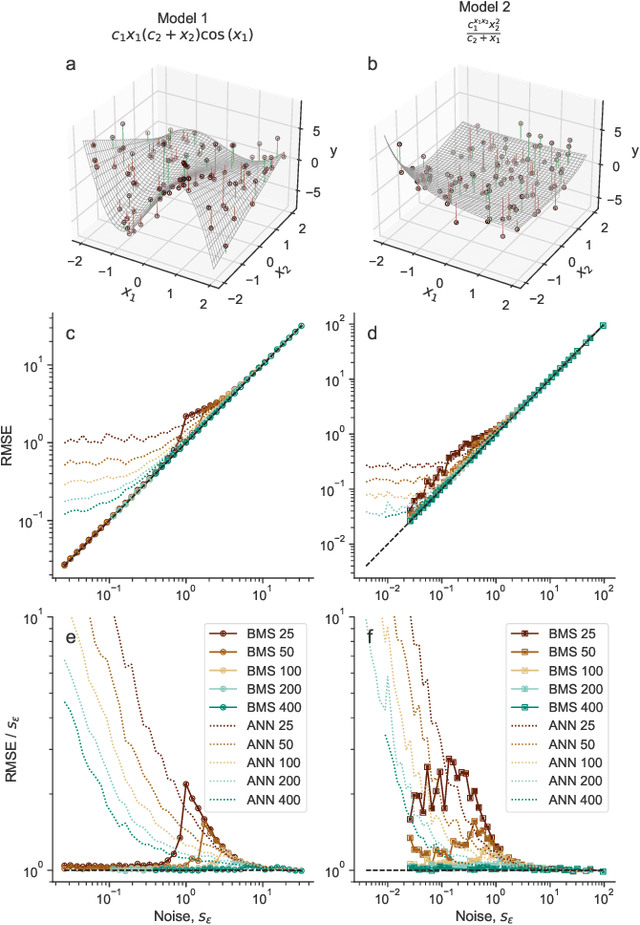
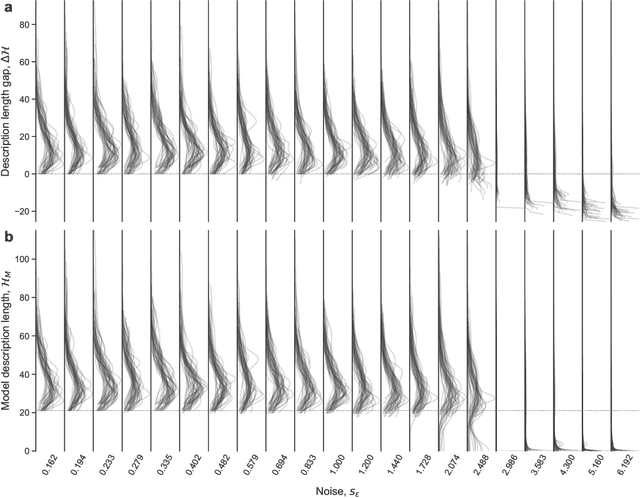
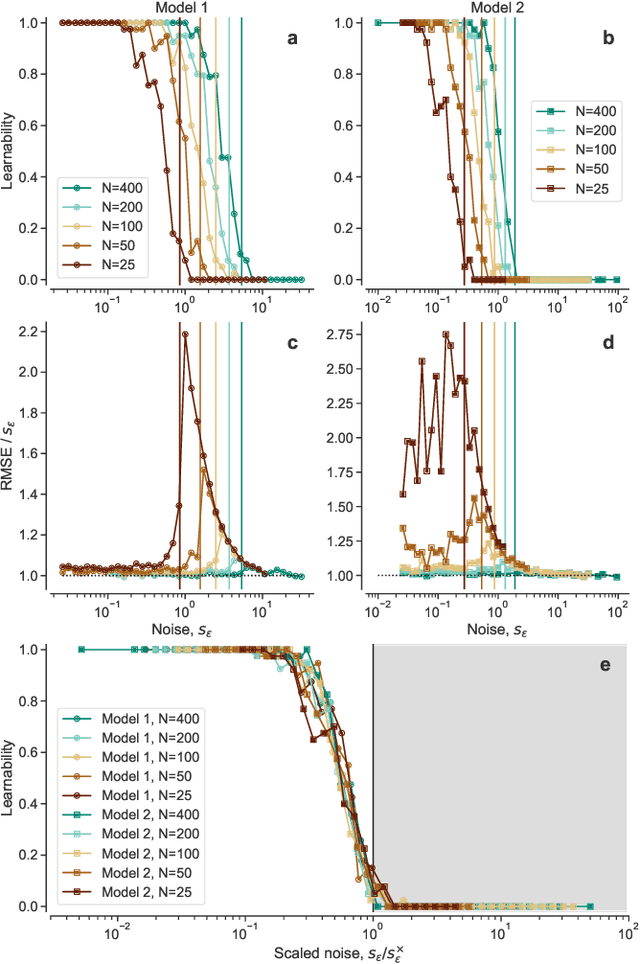
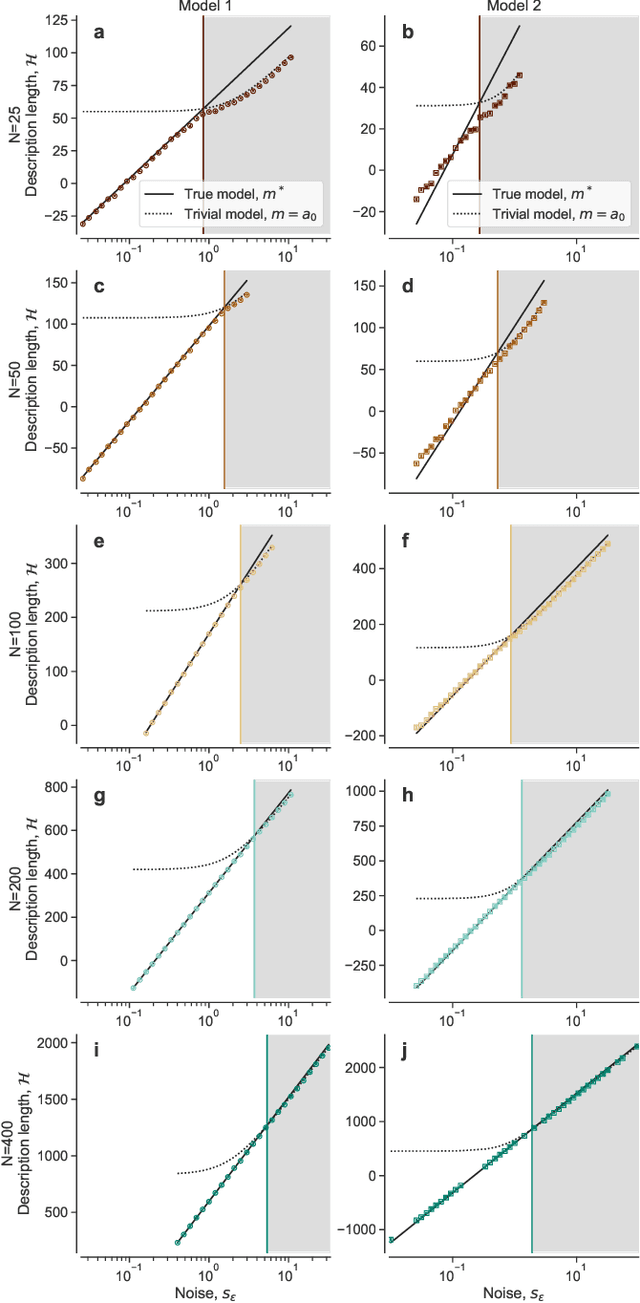
Given a finite and noisy dataset generated with a closed-form mathematical model, when is it possible to learn the true generating model from the data alone? This is the question we investigate here. We show that this model-learning problem displays a transition from a low-noise phase in which the true model can be learned, to a phase in which the observation noise is too high for the true model to be learned by any method. Both in the low-noise phase and in the high-noise phase, probabilistic model selection leads to optimal generalization to unseen data. This is in contrast to standard machine learning approaches, including artificial neural networks, which are limited, in the low-noise phase, by their ability to interpolate. In the transition region between the learnable and unlearnable phases, generalization is hard for all approaches including probabilistic model selection.
Node metadata can produce predictability transitions in network inference problems
Mar 26, 2021
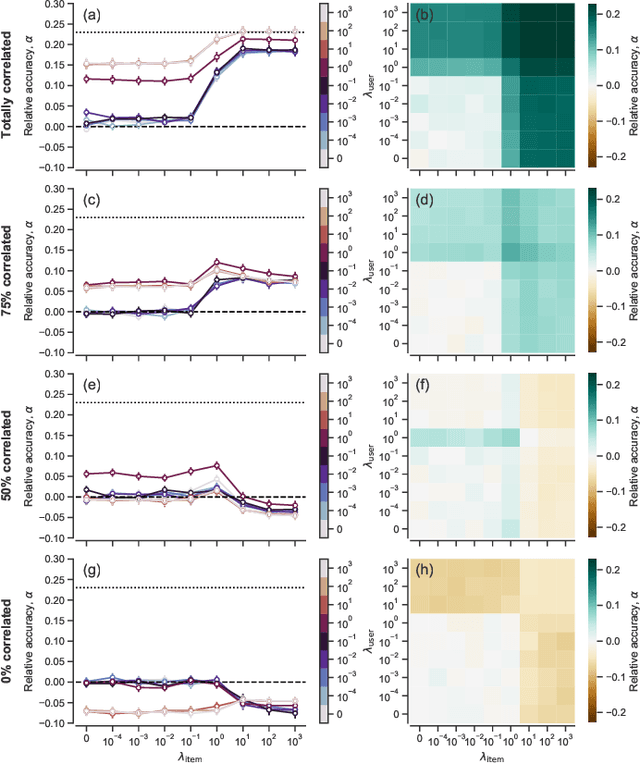
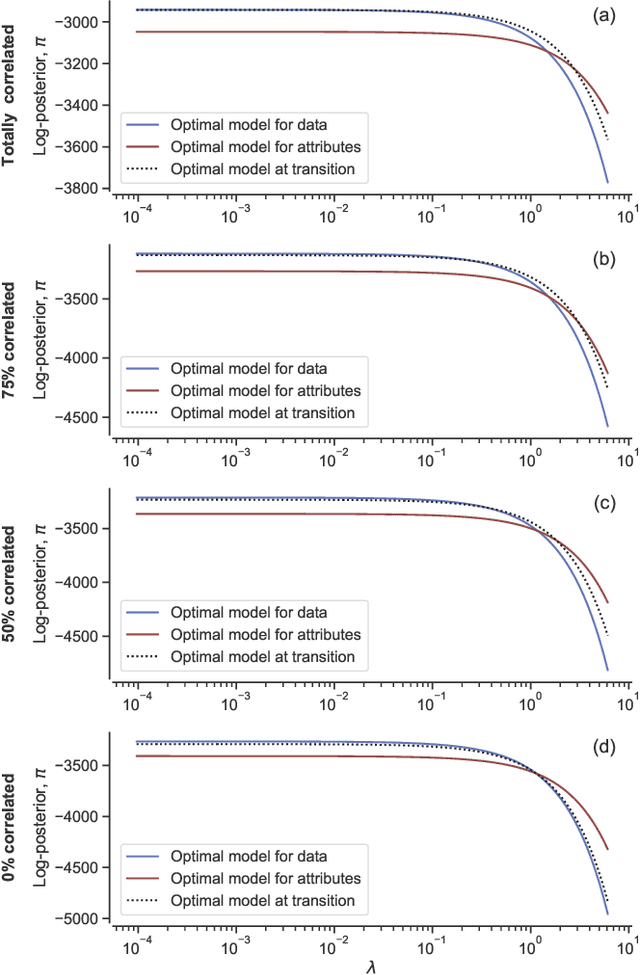
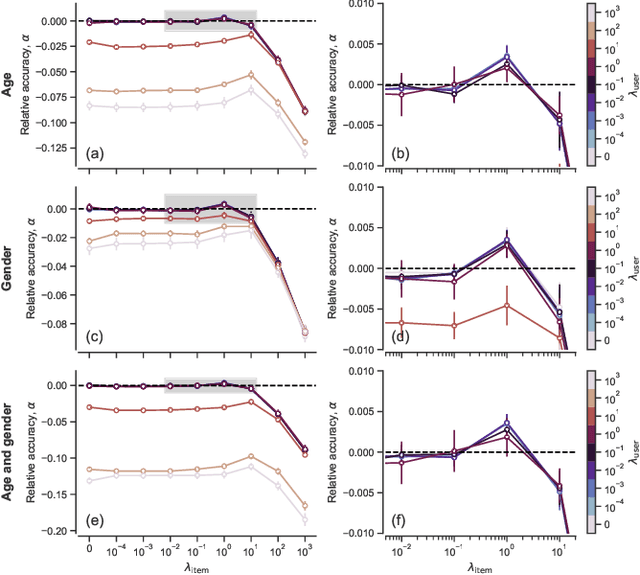
Network inference is the process of learning the properties of complex networks from data. Besides using information about known links in the network, node attributes and other forms of network metadata can help to solve network inference problems. Indeed, several approaches have been proposed to introduce metadata into probabilistic network models and to use them to make better inferences. However, we know little about the effect of such metadata in the inference process. Here, we investigate this issue. We find that, rather than affecting inference gradually, adding metadata causes abrupt transitions in the inference process and in our ability to make accurate predictions, from a situation in which metadata does not play any role to a situation in which metadata completely dominates the inference process. When network data and metadata are partly correlated, metadata optimally contributes to the inference process at the transition between data-dominated and metadata-dominated regimes.
A Bayesian machine scientist to aid in the solution of challenging scientific problems
Apr 25, 2020Closed-form, interpretable mathematical models have been instrumental for advancing our understanding of the world; with the data revolution, we may now be in a position to uncover new such models for many systems from physics to the social sciences. However, to deal with increasing amounts of data, we need "machine scientists" that are able to extract these models automatically from data. Here, we introduce a Bayesian machine scientist, which establishes the plausibility of models using explicit approximations to the exact marginal posterior over models and establishes its prior expectations about models by learning from a large empirical corpus of mathematical expressions. It explores the space of models using Markov chain Monte Carlo. We show that this approach uncovers accurate models for synthetic and real data and provides out-of-sample predictions that are more accurate than those of existing approaches and of other nonparametric methods.
Network-based models for social recommender systems
Feb 10, 2020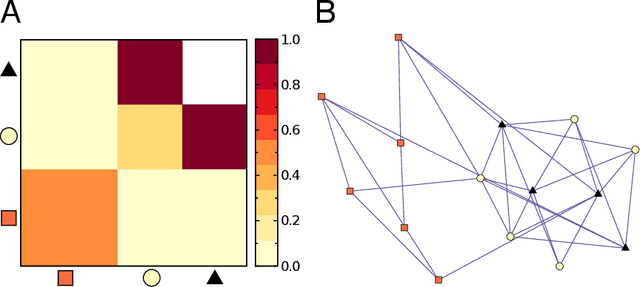
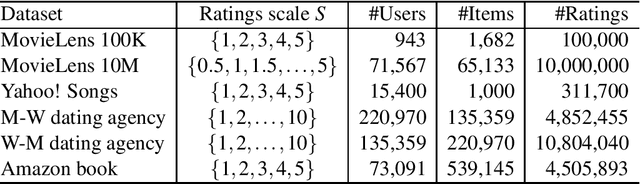
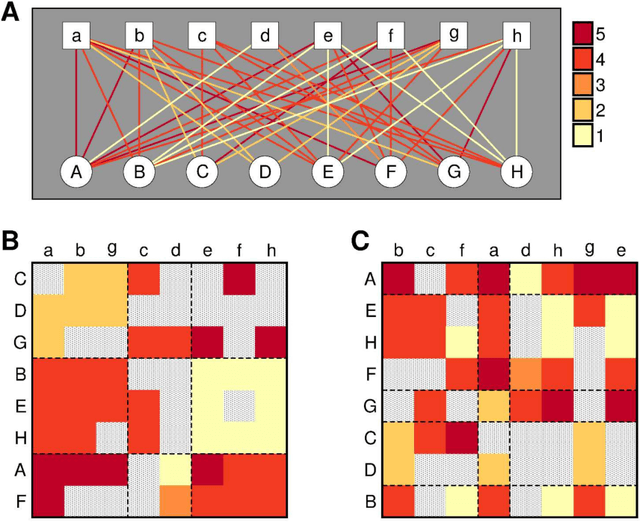
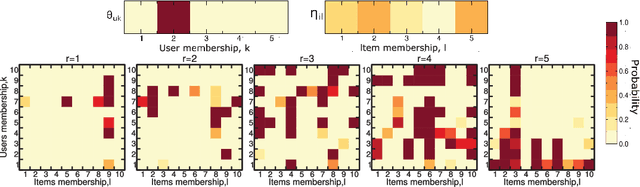
With the overwhelming online products available in recent years, there is an increasing need to filter and deliver relevant personalized advice for users. Recommender systems solve this problem by modeling and predicting individual preferences for a great variety of items such as movies, books or research articles. In this chapter, we explore rigorous network-based models that outperform leading approaches for recommendation. The network models we consider are based on the explicit assumption that there are groups of individuals and of items, and that the preferences of an individual for an item are determined only by their group memberships. The accurate prediction of individual user preferences over items can be accomplished by different methodologies, such as Monte Carlo sampling or Expectation-Maximization methods, the latter resulting in a scalable algorithm which is suitable for large datasets.
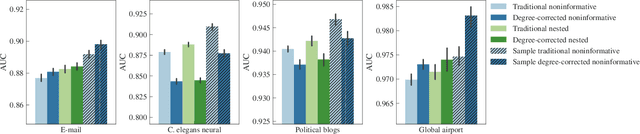
Consistencies and inconsistencies between model selection and link prediction in networks
Jun 28, 2018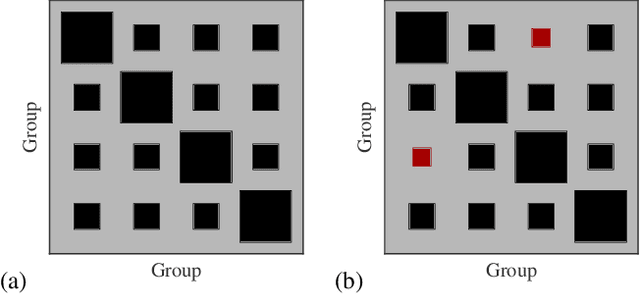

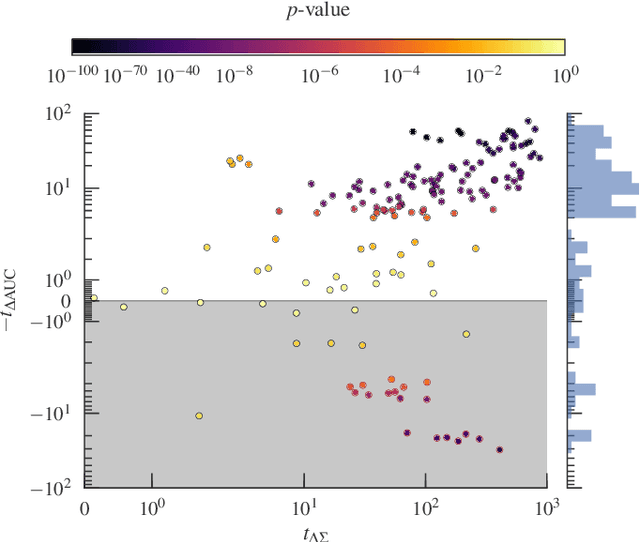
A principled approach to understand network structures is to formulate generative models. Given a collection of models, however, an outstanding key task is to determine which one provides a more accurate description of the network at hand, discounting statistical fluctuations. This problem can be approached using two principled criteria that at first may seem equivalent: selecting the most plausible model in terms of its posterior probability; or selecting the model with the highest predictive performance in terms of identifying missing links. Here we show that while these two approaches yield consistent results in most of cases, there are also notable instances where they do not, that is, where the most plausible model is not the most predictive. We show that in the latter case the improvement of predictive performance can in fact lead to overfitting both in artificial and empirical settings. Furthermore, we show that, in general, the predictive performance is higher when we average over collections of models that are individually less plausible, than when we consider only the single most plausible model.
* 12 pages, 6 figures, 1 table
Tensorial and bipartite block models for link prediction in layered networks and temporal networks
Mar 05, 2018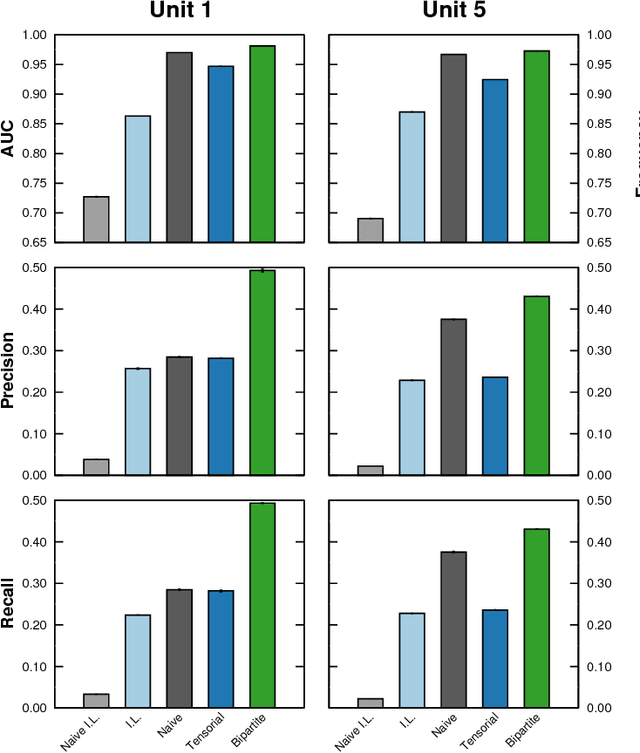
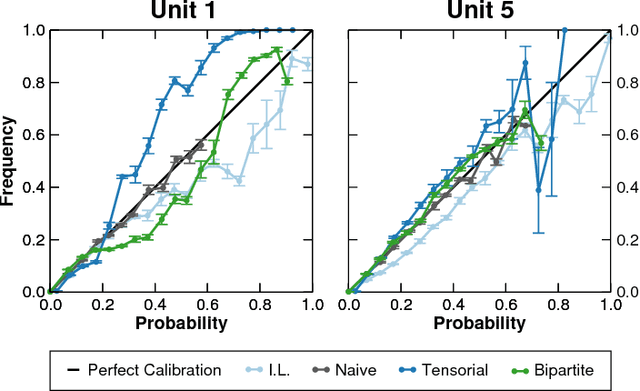
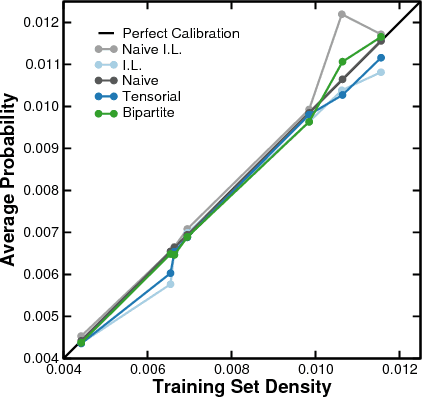
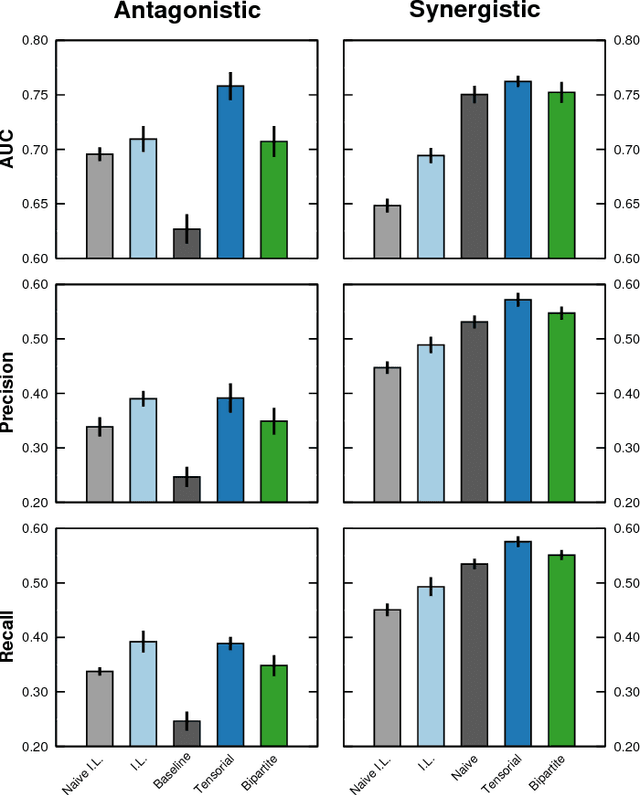
Many real-world complex systems are well represented as multilayer networks; predicting interactions in those systems is one of the most pressing problems in predictive network science. To address this challenge, we introduce two stochastic block models for multilayer and temporal networks; one of them uses nodes as its fundamental unit, whereas the other focuses on links. We also develop scalable algorithms for inferring the parameters of these models. Because our models describe all layers simultaneously, our approach takes full advantage of the information contained in the whole network when making predictions about any particular layer. We illustrate the potential of our approach by analyzing two empirical datasets---a temporal network of email communications, and a network of drug interactions for treating different cancer types. We find that modeling all layers simultaneously does result, in general, in more accurate link prediction. However, the most predictive model depends on the dataset under consideration; whereas the node-based model is more appropriate for predicting drug interactions, the link-based model is more appropriate for predicting email communication.
Accurate and scalable social recommendation using mixed-membership stochastic block models
Apr 06, 2016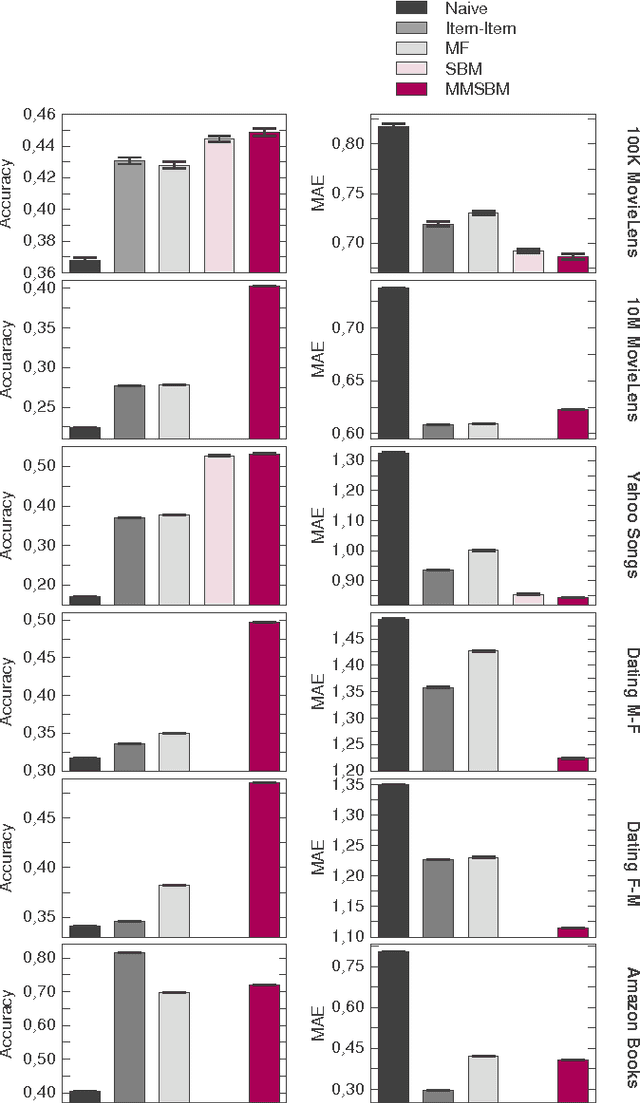
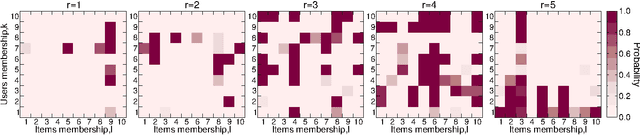
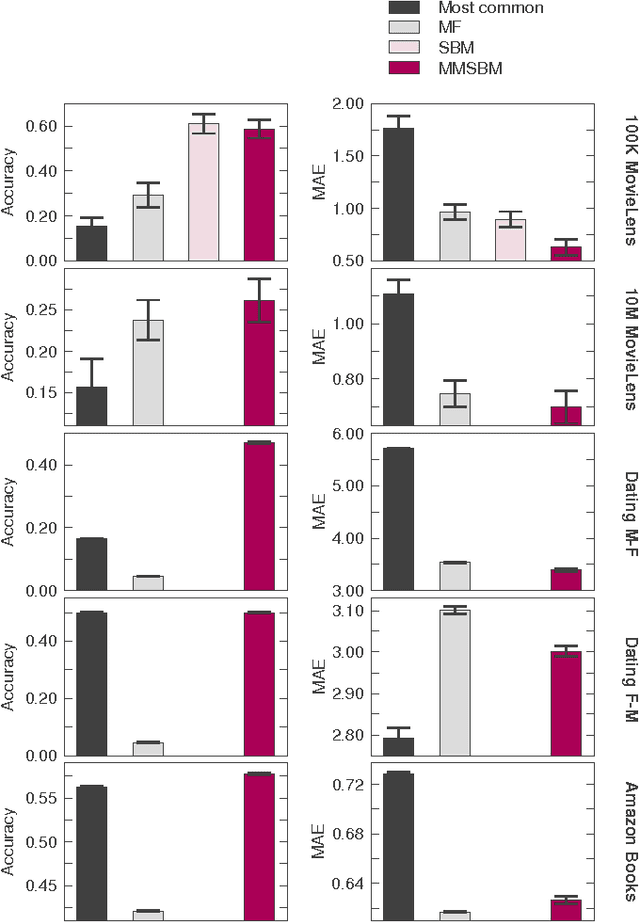
With ever-increasing amounts of online information available, modeling and predicting individual preferences-for books or articles, for example-is becoming more and more important. Good predictions enable us to improve advice to users, and obtain a better understanding of the socio-psychological processes that determine those preferences. We have developed a collaborative filtering model, with an associated scalable algorithm, that makes accurate predictions of individuals' preferences. Our approach is based on the explicit assumption that there are groups of individuals and of items, and that the preferences of an individual for an item are determined only by their group memberships. Importantly, we allow each individual and each item to belong simultaneously to mixtures of different groups and, unlike many popular approaches, such as matrix factorization, we do not assume implicitly or explicitly that individuals in each group prefer items in a single group of items. The resulting overlapping groups and the predicted preferences can be inferred with a expectation-maximization algorithm whose running time scales linearly (per iteration). Our approach enables us to predict individual preferences in large datasets, and is considerably more accurate than the current algorithms for such large datasets.
* 9 pages, 4 figures
Justice blocks and predictability of US Supreme Court votes
Oct 17, 2012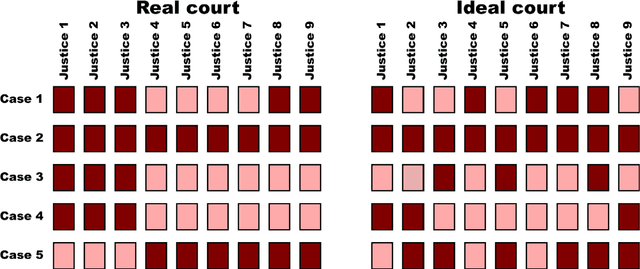
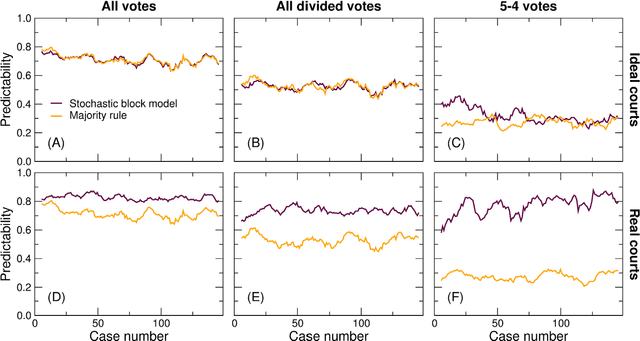
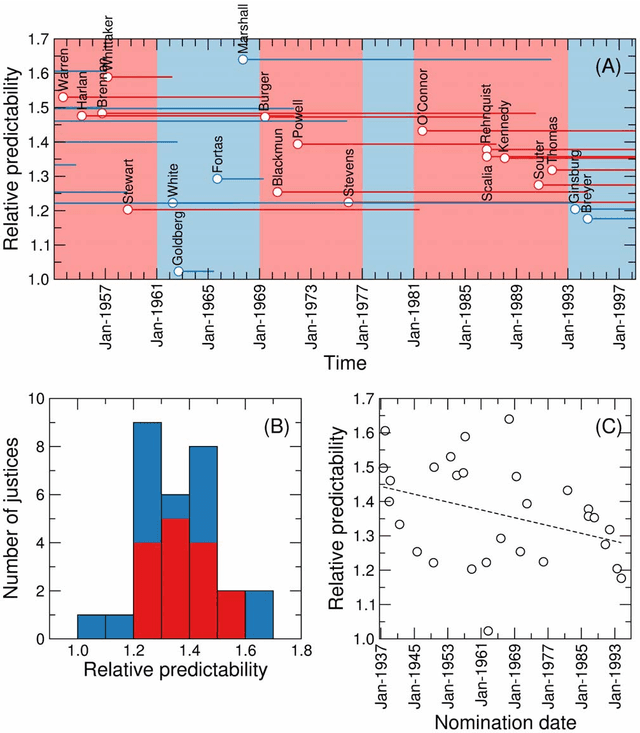
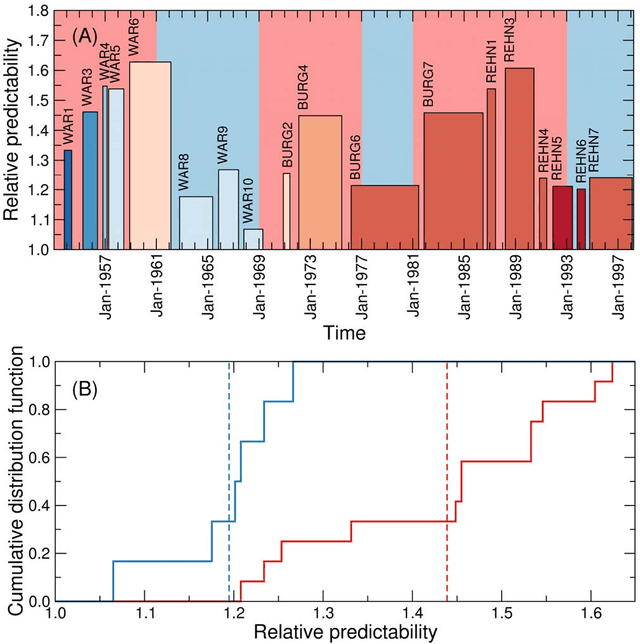
Successful attempts to predict judges' votes shed light into how legal decisions are made and, ultimately, into the behavior and evolution of the judiciary. Here, we investigate to what extent it is possible to make predictions of a justice's vote based on the other justices' votes in the same case. For our predictions, we use models and methods that have been developed to uncover hidden associations between actors in complex social networks. We show that these methods are more accurate at predicting justice's votes than forecasts made by legal experts and by algorithms that take into consideration the content of the cases. We argue that, within our framework, high predictability is a quantitative proxy for stable justice (and case) blocks, which probably reflect stable a priori attitudes toward the law. We find that U. S. Supreme Court justice votes are more predictable than one would expect from an ideal court composed of perfectly independent justices. Deviations from ideal behavior are most apparent in divided 5-4 decisions, where justice blocks seem to be most stable. Moreover, we find evidence that justice predictability decreased during the 50-year period spanning from the Warren Court to the Rehnquist Court, and that aggregate court predictability has been significantly lower during Democratic presidencies. More broadly, our results show that it is possible to use methods developed for the analysis of complex social networks to quantitatively investigate historical questions related to political decision-making.