 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA collaborative constrained graph diffusion model for the generation of realistic synthetic molecules
May 22, 2025



Developing new molecular compounds is crucial to address pressing challenges, from health to environmental sustainability. However, exploring the molecular space to discover new molecules is difficult due to the vastness of the space. Here we introduce CoCoGraph, a collaborative and constrained graph diffusion model capable of generating molecules that are guaranteed to be chemically valid. Thanks to the constraints built into the model and to the collaborative mechanism, CoCoGraph outperforms state-of-the-art approaches on standard benchmarks while requiring up to an order of magnitude fewer parameters. Analysis of 36 chemical properties also demonstrates that CoCoGraph generates molecules with distributions more closely matching real molecules than current models. Leveraging the model's efficiency, we created a database of 8.2M million synthetically generated molecules and conducted a Turing-like test with organic chemistry experts to further assess the plausibility of the generated molecules, and potential biases and limitations of CoCoGraph.
Human mobility is well described by closed-form gravity-like models learned automatically from data
Dec 18, 2023Modeling of human mobility is critical to address questions in urban planning and transportation, as well as global challenges in sustainability, public health, and economic development. However, our understanding and ability to model mobility flows within and between urban areas are still incomplete. At one end of the modeling spectrum we have simple so-called gravity models, which are easy to interpret and provide modestly accurate predictions of mobility flows. At the other end, we have complex machine learning and deep learning models, with tens of features and thousands of parameters, which predict mobility more accurately than gravity models at the cost of not being interpretable and not providing insight on human behavior. Here, we show that simple machine-learned, closed-form models of mobility are able to predict mobility flows more accurately, overall, than either gravity or complex machine and deep learning models. At the same time, these models are simple and gravity-like, and can be interpreted in terms similar to standard gravity models. Furthermore, these models work for different datasets and at different scales, suggesting that they may capture the fundamental universal features of human mobility.
Consistencies and inconsistencies between model selection and link prediction in networks
Jun 28, 2018

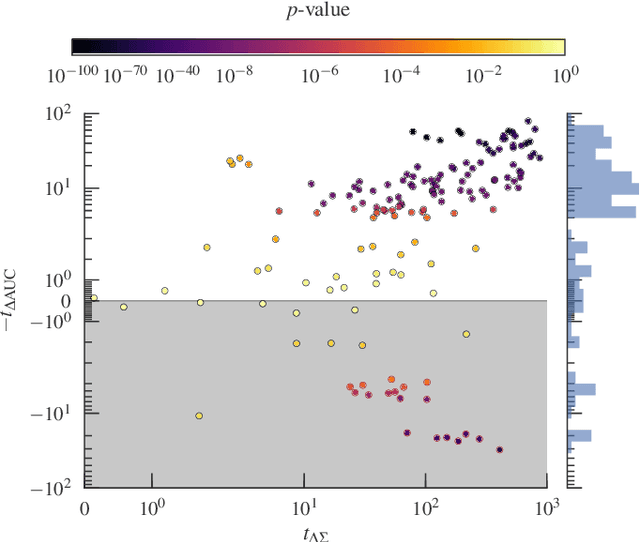
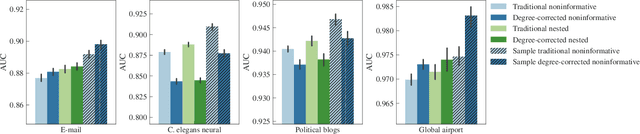
A principled approach to understand network structures is to formulate generative models. Given a collection of models, however, an outstanding key task is to determine which one provides a more accurate description of the network at hand, discounting statistical fluctuations. This problem can be approached using two principled criteria that at first may seem equivalent: selecting the most plausible model in terms of its posterior probability; or selecting the model with the highest predictive performance in terms of identifying missing links. Here we show that while these two approaches yield consistent results in most of cases, there are also notable instances where they do not, that is, where the most plausible model is not the most predictive. We show that in the latter case the improvement of predictive performance can in fact lead to overfitting both in artificial and empirical settings. Furthermore, we show that, in general, the predictive performance is higher when we average over collections of models that are individually less plausible, than when we consider only the single most plausible model.
* 12 pages, 6 figures, 1 table