 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork-based models for social recommender systems
Feb 10, 2020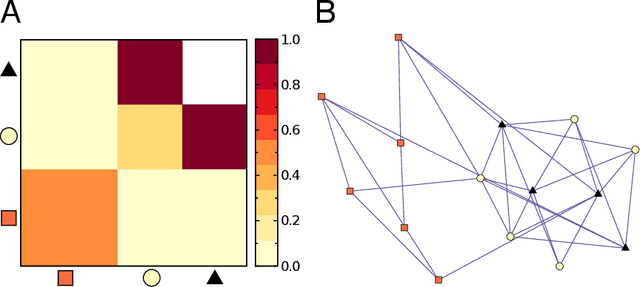
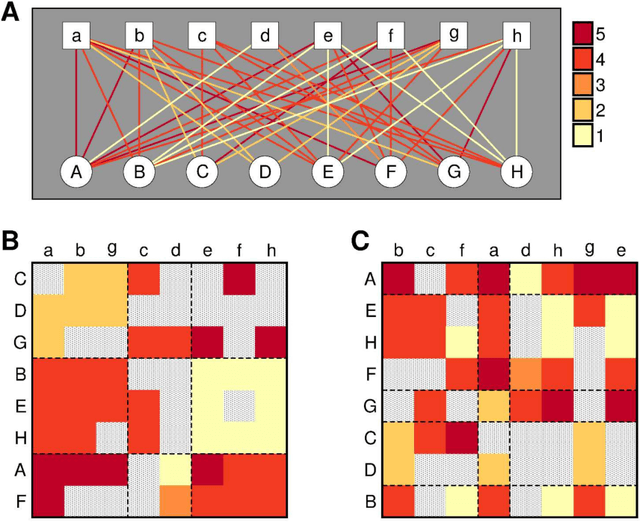
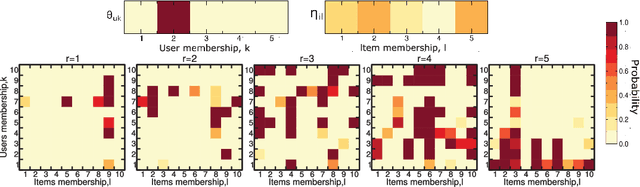
With the overwhelming online products available in recent years, there is an increasing need to filter and deliver relevant personalized advice for users. Recommender systems solve this problem by modeling and predicting individual preferences for a great variety of items such as movies, books or research articles. In this chapter, we explore rigorous network-based models that outperform leading approaches for recommendation. The network models we consider are based on the explicit assumption that there are groups of individuals and of items, and that the preferences of an individual for an item are determined only by their group memberships. The accurate prediction of individual user preferences over items can be accomplished by different methodologies, such as Monte Carlo sampling or Expectation-Maximization methods, the latter resulting in a scalable algorithm which is suitable for large datasets.
Tensorial and bipartite block models for link prediction in layered networks and temporal networks
Mar 05, 2018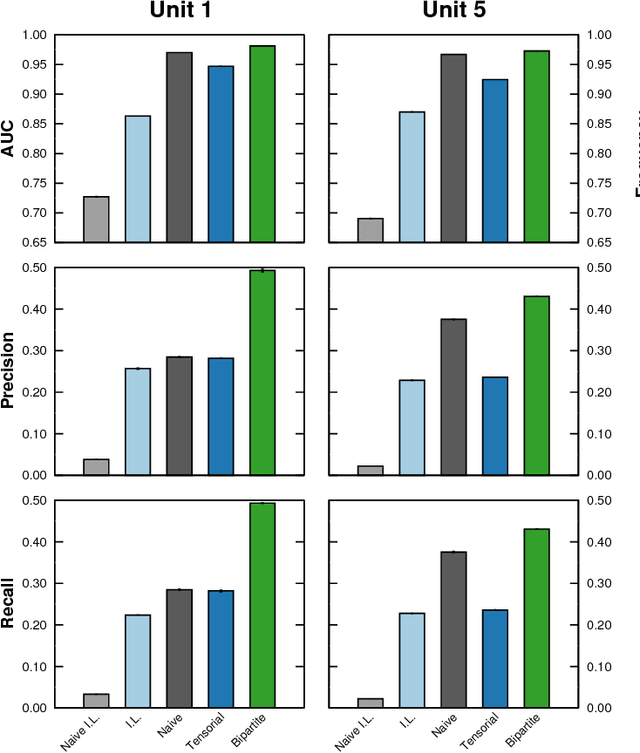
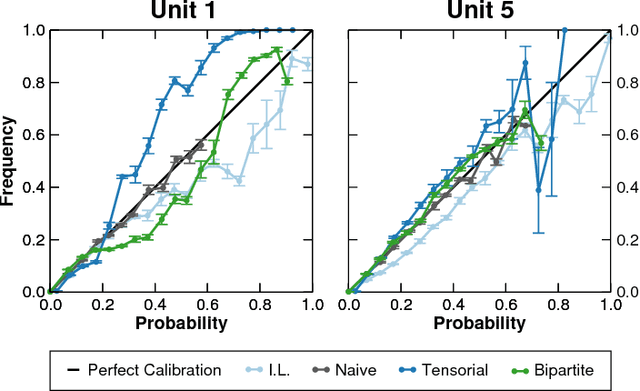
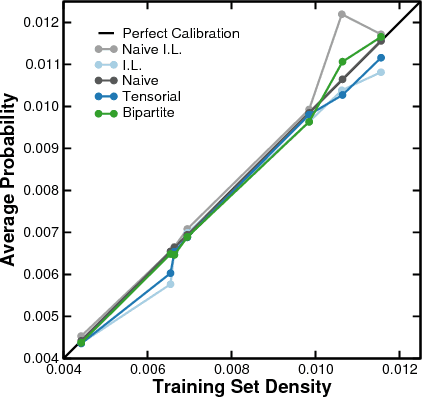
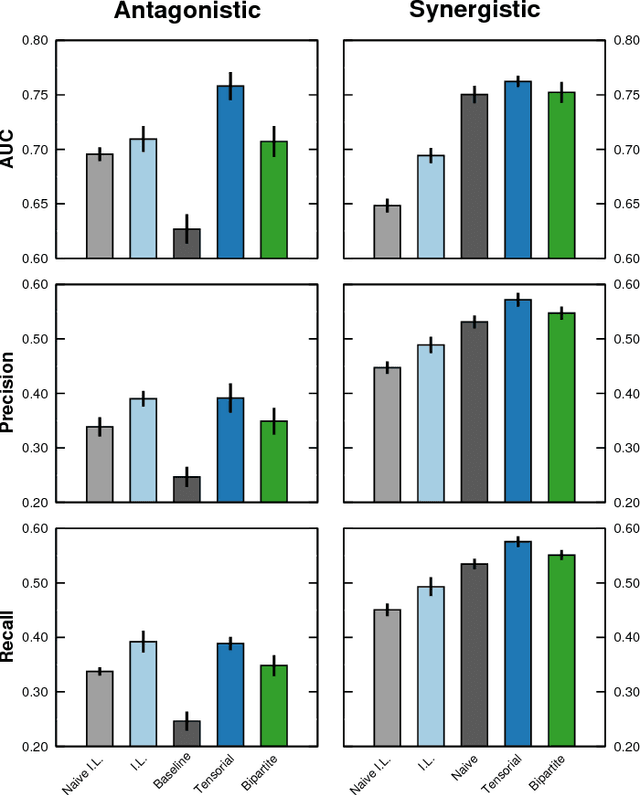
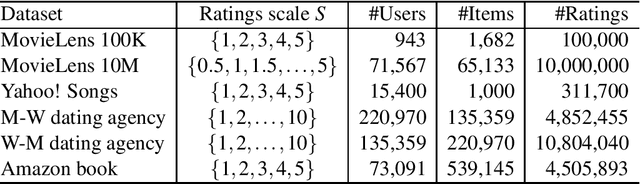
Many real-world complex systems are well represented as multilayer networks; predicting interactions in those systems is one of the most pressing problems in predictive network science. To address this challenge, we introduce two stochastic block models for multilayer and temporal networks; one of them uses nodes as its fundamental unit, whereas the other focuses on links. We also develop scalable algorithms for inferring the parameters of these models. Because our models describe all layers simultaneously, our approach takes full advantage of the information contained in the whole network when making predictions about any particular layer. We illustrate the potential of our approach by analyzing two empirical datasets---a temporal network of email communications, and a network of drug interactions for treating different cancer types. We find that modeling all layers simultaneously does result, in general, in more accurate link prediction. However, the most predictive model depends on the dataset under consideration; whereas the node-based model is more appropriate for predicting drug interactions, the link-based model is more appropriate for predicting email communication.
Accurate and scalable social recommendation using mixed-membership stochastic block models
Apr 06, 2016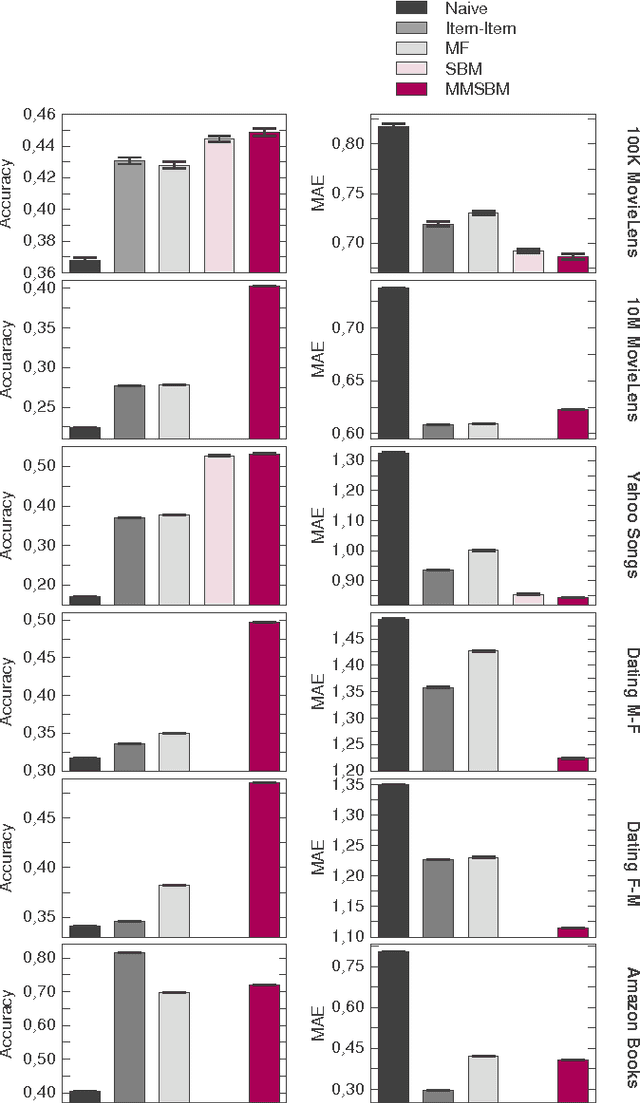
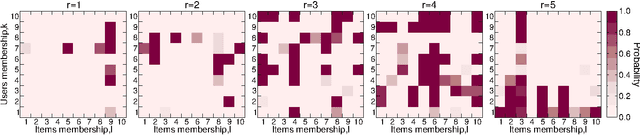
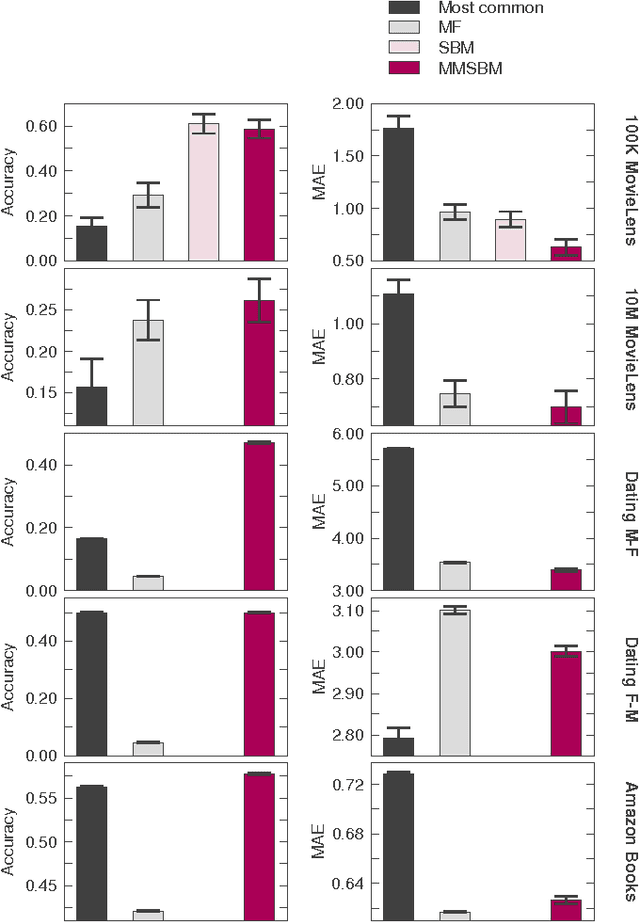
With ever-increasing amounts of online information available, modeling and predicting individual preferences-for books or articles, for example-is becoming more and more important. Good predictions enable us to improve advice to users, and obtain a better understanding of the socio-psychological processes that determine those preferences. We have developed a collaborative filtering model, with an associated scalable algorithm, that makes accurate predictions of individuals' preferences. Our approach is based on the explicit assumption that there are groups of individuals and of items, and that the preferences of an individual for an item are determined only by their group memberships. Importantly, we allow each individual and each item to belong simultaneously to mixtures of different groups and, unlike many popular approaches, such as matrix factorization, we do not assume implicitly or explicitly that individuals in each group prefer items in a single group of items. The resulting overlapping groups and the predicted preferences can be inferred with a expectation-maximization algorithm whose running time scales linearly (per iteration). Our approach enables us to predict individual preferences in large datasets, and is considerably more accurate than the current algorithms for such large datasets.
* 9 pages, 4 figures