 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental limits to learning closed-form mathematical models from data
Apr 06, 2022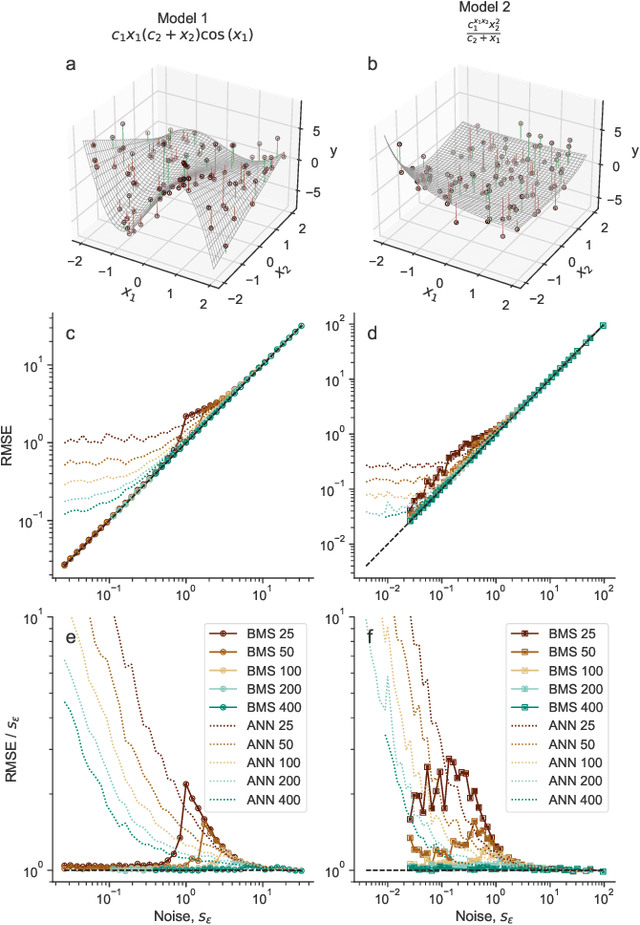
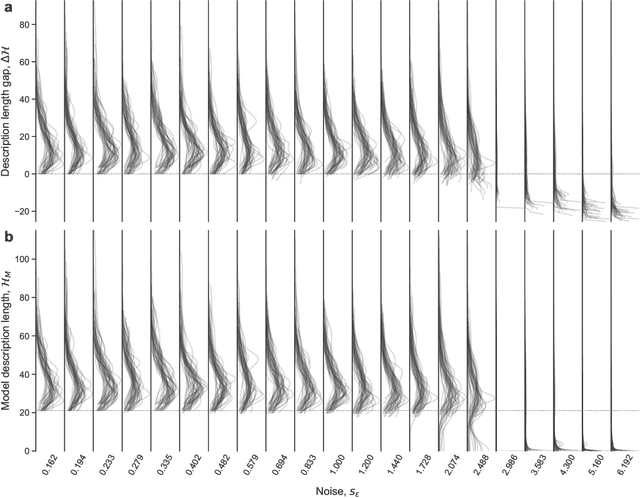
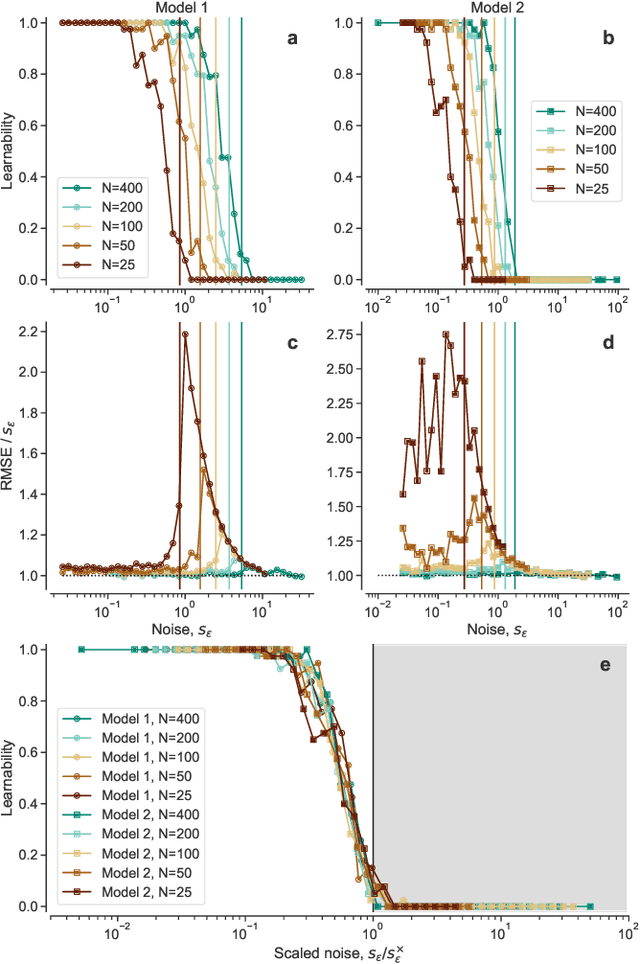
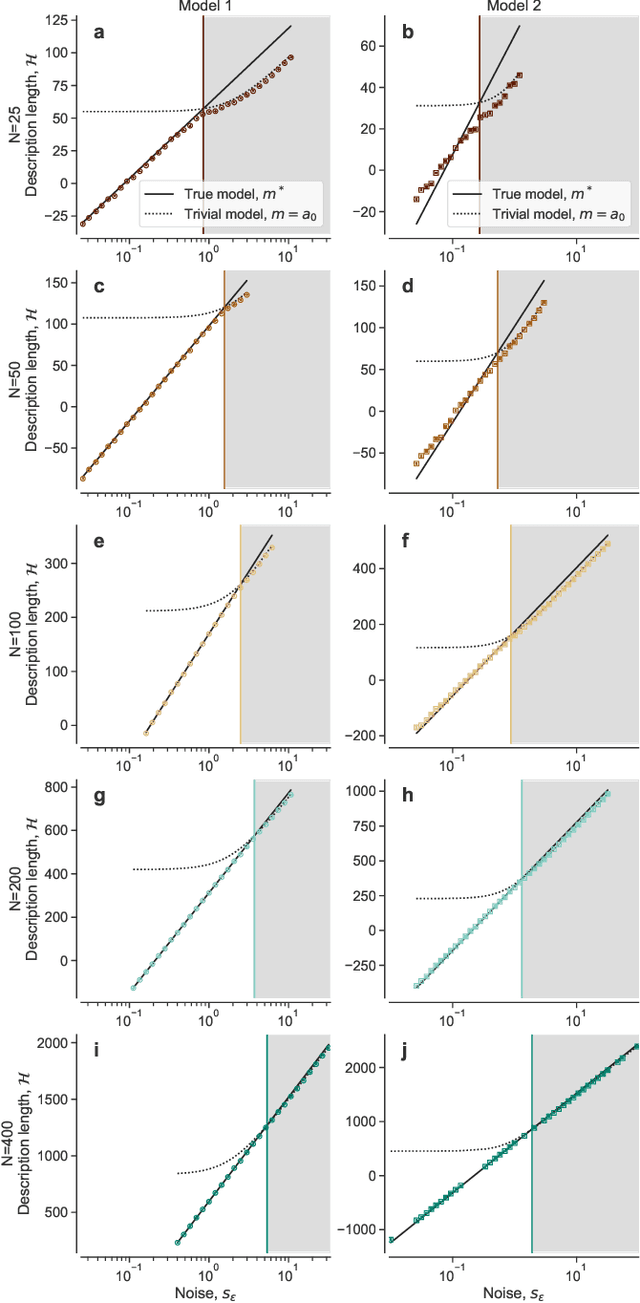
Given a finite and noisy dataset generated with a closed-form mathematical model, when is it possible to learn the true generating model from the data alone? This is the question we investigate here. We show that this model-learning problem displays a transition from a low-noise phase in which the true model can be learned, to a phase in which the observation noise is too high for the true model to be learned by any method. Both in the low-noise phase and in the high-noise phase, probabilistic model selection leads to optimal generalization to unseen data. This is in contrast to standard machine learning approaches, including artificial neural networks, which are limited, in the low-noise phase, by their ability to interpolate. In the transition region between the learnable and unlearnable phases, generalization is hard for all approaches including probabilistic model selection.
A Bayesian machine scientist to aid in the solution of challenging scientific problems
Apr 25, 2020Closed-form, interpretable mathematical models have been instrumental for advancing our understanding of the world; with the data revolution, we may now be in a position to uncover new such models for many systems from physics to the social sciences. However, to deal with increasing amounts of data, we need "machine scientists" that are able to extract these models automatically from data. Here, we introduce a Bayesian machine scientist, which establishes the plausibility of models using explicit approximations to the exact marginal posterior over models and establishes its prior expectations about models by learning from a large empirical corpus of mathematical expressions. It explores the space of models using Markov chain Monte Carlo. We show that this approach uncovers accurate models for synthetic and real data and provides out-of-sample predictions that are more accurate than those of existing approaches and of other nonparametric methods.