 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Detection of Personal Employment Status on Twitter
Mar 17, 2022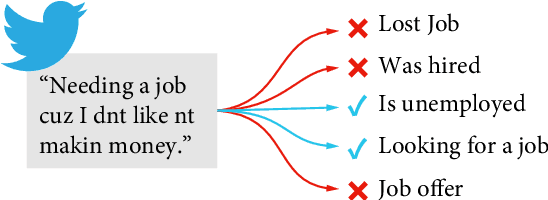
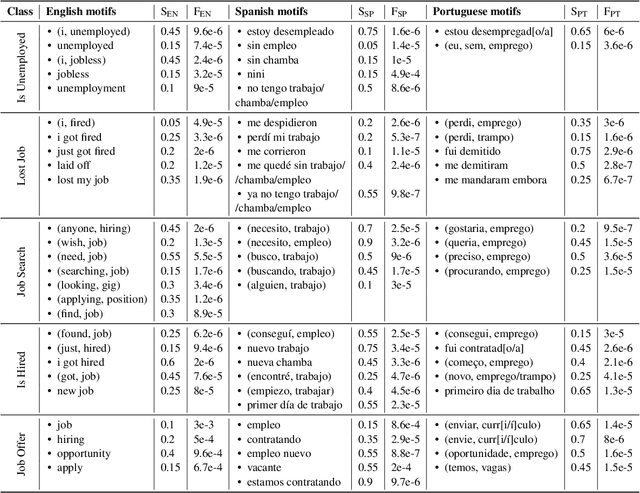


Detecting disclosures of individuals' employment status on social media can provide valuable information to match job seekers with suitable vacancies, offer social protection, or measure labor market flows. However, identifying such personal disclosures is a challenging task due to their rarity in a sea of social media content and the variety of linguistic forms used to describe them. Here, we examine three Active Learning (AL) strategies in real-world settings of extreme class imbalance, and identify five types of disclosures about individuals' employment status (e.g. job loss) in three languages using BERT-based classification models. Our findings show that, even under extreme imbalance settings, a small number of AL iterations is sufficient to obtain large and significant gains in precision, recall, and diversity of results compared to a supervised baseline with the same number of labels. We also find that no AL strategy consistently outperforms the rest. Qualitative analysis suggests that AL helps focus the attention mechanism of BERT on core terms and adjust the boundaries of semantic expansion, highlighting the importance of interpretable models to provide greater control and visibility into this dynamic learning process.
A Study of Compositional Generalization in Neural Models
Jul 08, 2020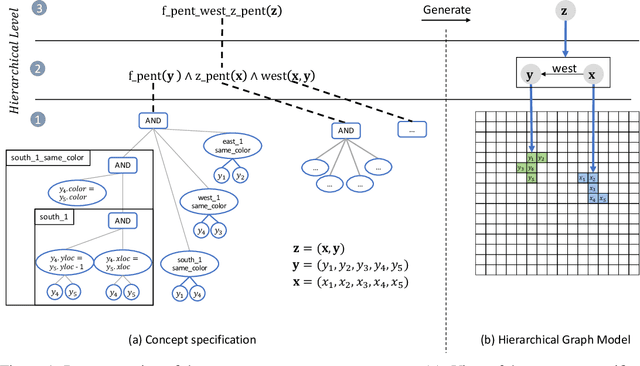
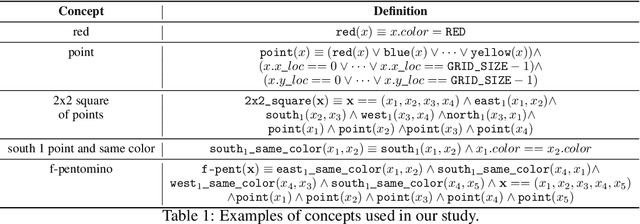
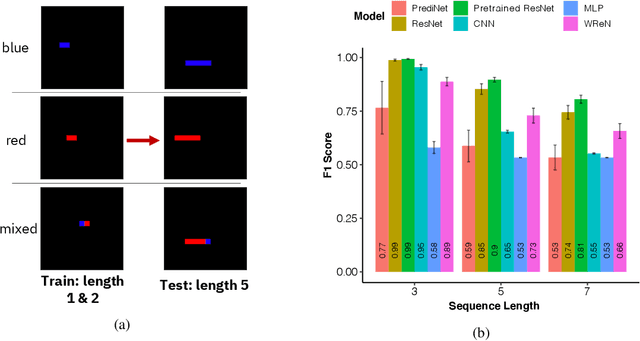
Compositional and relational learning is a hallmark of human intelligence, but one which presents challenges for neural models. One difficulty in the development of such models is the lack of benchmarks with clear compositional and relational task structure on which to systematically evaluate them. In this paper, we introduce an environment called ConceptWorld, which enables the generation of images from compositional and relational concepts, defined using a logical domain specific language. We use it to generate images for a variety of compositional structures: 2x2 squares, pentominoes, sequences, scenes involving these objects, and other more complex concepts. We perform experiments to test the ability of standard neural architectures to generalize on relations with compositional arguments as the compositional depth of those arguments increases and under substitution. We compare standard neural networks such as MLP, CNN and ResNet, as well as state-of-the-art relational networks including WReN and PrediNet in a multi-class image classification setting. For simple problems, all models generalize well to close concepts but struggle with longer compositional chains. For more complex tests involving substitutivity, all models struggle, even with short chains. In highlighting these difficulties and providing an environment for further experimentation, we hope to encourage the development of models which are able to generalize effectively in compositional, relational domains.
Communication Topologies Between Learning Agents in Deep Reinforcement Learning
Feb 16, 2019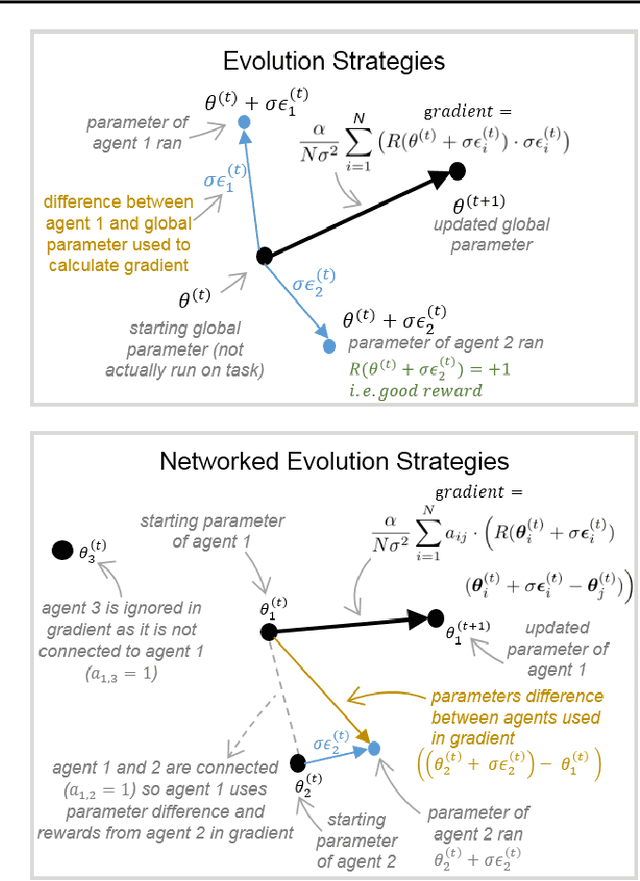

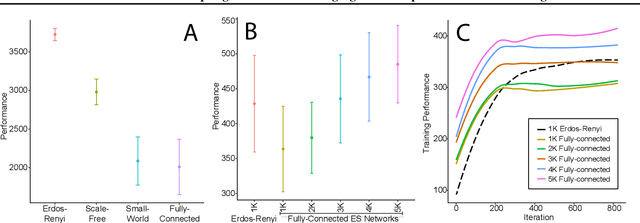
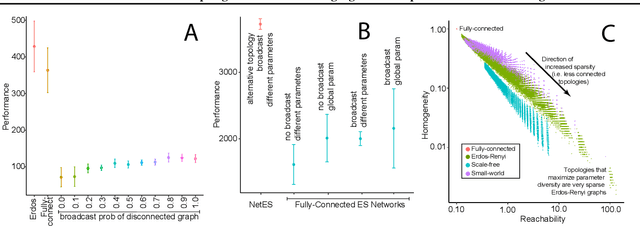
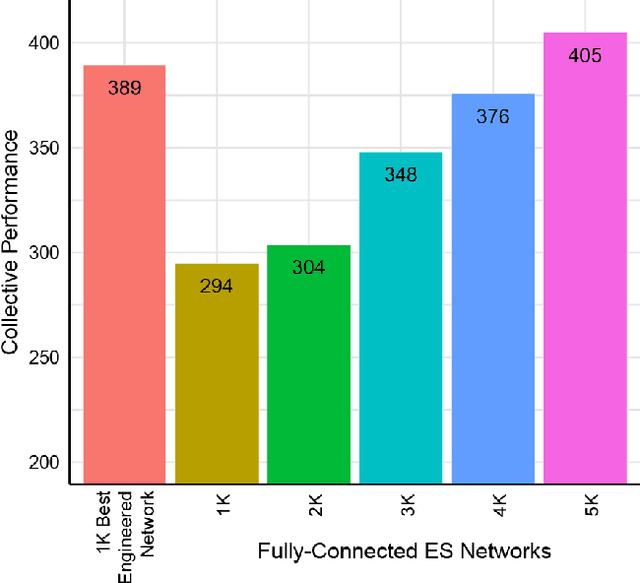
A common technique to improve speed and robustness of learning in deep reinforcement learning (DRL) and many other machine learning algorithms is to run multiple learning agents in parallel. A neglected component in the development of these algorithms has been how best to arrange the learning agents involved to better facilitate distributed search. Here we draw upon results from the networked optimization and collective intelligence literatures suggesting that arranging learning agents in less than fully connected topologies (the implicit way agents are commonly arranged in) can improve learning. We explore the relative performance of four popular families of graphs and observe that one such family (Erdos-Renyi random graphs) empirically outperforms the standard fully-connected communication topology across several DRL benchmark tasks. We observe that 1000 learning agents arranged in an Erdos-Renyi graph can perform as well as 3000 agents arranged in the standard fully-connected topology, showing the large learning improvement possible when carefully designing the topology over which agents communicate. We complement these empirical results with a preliminary theoretical investigation of why less than fully connected topologies can perform better. Overall, our work suggests that distributed machine learning algorithms could be made more efficient if the communication topology between learning agents was optimized.
How to Organize your Deep Reinforcement Learning Agents: The Importance of Communication Topology
Nov 30, 2018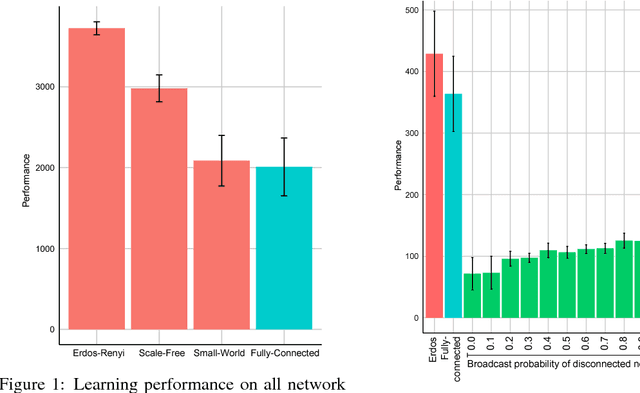

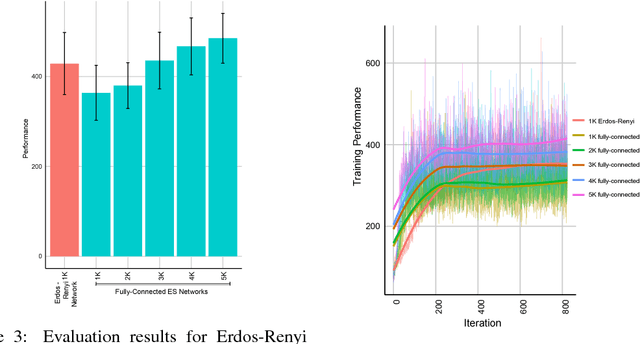
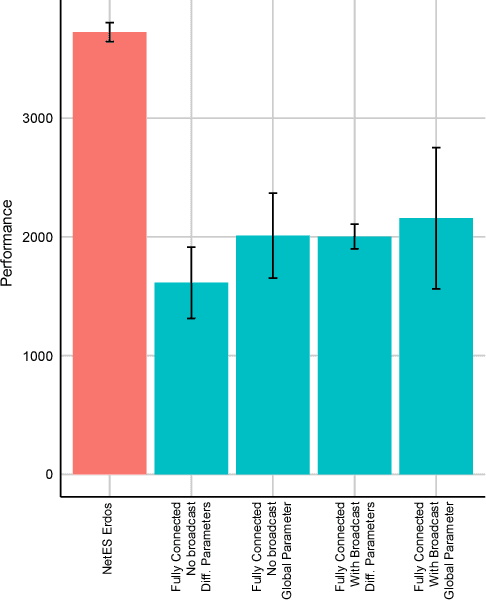
In this empirical paper, we investigate how learning agents can be arranged in more efficient communication topologies for improved learning. This is an important problem because a common technique to improve speed and robustness of learning in deep reinforcement learning and many other machine learning algorithms is to run multiple learning agents in parallel. The standard communication architecture typically involves all agents intermittently communicating with each other (fully connected topology) or with a centralized server (star topology). Unfortunately, optimizing the topology of communication over the space of all possible graphs is a hard problem, so we borrow results from the networked optimization and collective intelligence literatures which suggest that certain families of network topologies can lead to strong improvements over fully-connected networks. We start by introducing alternative network topologies to DRL benchmark tasks under the Evolution Strategies paradigm which we call Network Evolution Strategies. We explore the relative performance of the four main graph families and observe that one such family (Erdos-Renyi random graphs) empirically outperforms all other families, including the de facto fully-connected communication topologies. Additionally, the use of alternative network topologies has a multiplicative performance effect: we observe that when 1000 learning agents are arranged in a carefully designed communication topology, they can compete with 3000 agents arranged in the de facto fully-connected topology. Overall, our work suggests that distributed machine learning algorithms would learn more efficiently if the communication topology between learning agents was optimized.
Improved Learning in Evolution Strategies via Sparser Inter-Agent Network Topologies
Nov 30, 2017

We draw upon a previously largely untapped literature on human collective intelligence as a source of inspiration for improving deep learning. Implicit in many algorithms that attempt to solve Deep Reinforcement Learning (DRL) tasks is the network of processors along which parameter values are shared. So far, existing approaches have implicitly utilized fully-connected networks, in which all processors are connected. However, the scientific literature on human collective intelligence suggests that complete networks may not always be the most effective information network structures for distributed search through complex spaces. Here we show that alternative topologies can improve deep neural network training: we find that sparser networks learn higher rewards faster, leading to learning improvements at lower communication costs.