 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudgeMeNot: Personalizing Large Language Models to Emulate Judicial Reasoning in Hebrew
Apr 20, 2026Despite significant advances in large language models, personalizing them for individual decision-makers remains an open problem. Here, we introduce a synthetic-organic supervision pipeline that transforms raw judicial decisions into instruction-tuning data, enabling parameter-efficient fine-tuning of personalized models for individual judges in low-resource settings. We compare our approach to state-of-the-art personalization techniques across three different tasks and settings. The results show that Causal Language Modeling followed by synthetically generated instruction-tuning significantly outperforms all other baselines, providing significant improvements across lexical, stylistic, and semantic similarity. Notably, our model-generated outputs are indistinguishable from the reasoning of human judges, highlighting the viability of efficient personalization, even in low-resource settings.
CUPCase: Clinically Uncommon Patient Cases and Diagnoses Dataset
Mar 08, 2025



Medical benchmark datasets significantly contribute to developing Large Language Models (LLMs) for medical knowledge extraction, diagnosis, summarization, and other uses. Yet, current benchmarks are mainly derived from exam questions given to medical students or cases described in the medical literature, lacking the complexity of real-world patient cases that deviate from classic textbook abstractions. These include rare diseases, uncommon presentations of common diseases, and unexpected treatment responses. Here, we construct Clinically Uncommon Patient Cases and Diagnosis Dataset (CUPCase) based on 3,562 real-world case reports from BMC, including diagnoses in open-ended textual format and as multiple-choice options with distractors. Using this dataset, we evaluate the ability of state-of-the-art LLMs, including both general-purpose and Clinical LLMs, to identify and correctly diagnose a patient case, and test models' performance when only partial information about cases is available. Our findings show that general-purpose GPT-4o attains the best performance in both the multiple-choice task (average accuracy of 87.9%) and the open-ended task (BERTScore F1 of 0.764), outperforming several LLMs with a focus on the medical domain such as Meditron-70B and MedLM-Large. Moreover, GPT-4o was able to maintain 87% and 88% of its performance with only the first 20% of tokens of the case presentation in multiple-choice and free text, respectively, highlighting the potential of LLMs to aid in early diagnosis in real-world cases. CUPCase expands our ability to evaluate LLMs for clinical decision support in an open and reproducible manner.
The Branch Not Taken: Predicting Branching in Online Conversations
Apr 21, 2024



Multi-participant discussions tend to unfold in a tree structure rather than a chain structure. Branching may occur for multiple reasons -- from the asynchronous nature of online platforms to a conscious decision by an interlocutor to disengage with part of the conversation. Predicting branching and understanding the reasons for creating new branches is important for many downstream tasks such as summarization and thread disentanglement and may help develop online spaces that encourage users to engage in online discussions in more meaningful ways. In this work, we define the novel task of branch prediction and propose GLOBS (Global Branching Score) -- a deep neural network model for predicting branching. GLOBS is evaluated on three large discussion forums from Reddit, achieving significant improvements over an array of competitive baselines and demonstrating better transferability. We affirm that structural, temporal, and linguistic features contribute to GLOBS success and find that branching is associated with a greater number of conversation participants and tends to occur in earlier levels of the conversation tree. We publicly release GLOBS and our implementation of all baseline models to allow reproducibility and promote further research on this important task.
Multilingual Detection of Personal Employment Status on Twitter
Mar 17, 2022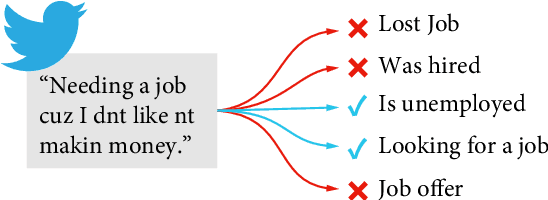
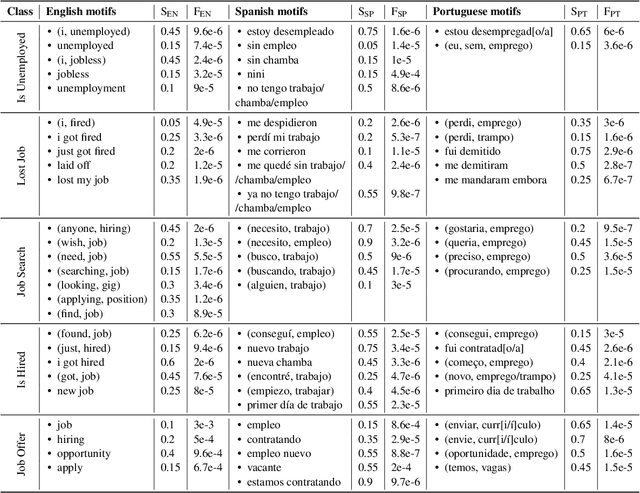


Detecting disclosures of individuals' employment status on social media can provide valuable information to match job seekers with suitable vacancies, offer social protection, or measure labor market flows. However, identifying such personal disclosures is a challenging task due to their rarity in a sea of social media content and the variety of linguistic forms used to describe them. Here, we examine three Active Learning (AL) strategies in real-world settings of extreme class imbalance, and identify five types of disclosures about individuals' employment status (e.g. job loss) in three languages using BERT-based classification models. Our findings show that, even under extreme imbalance settings, a small number of AL iterations is sufficient to obtain large and significant gains in precision, recall, and diversity of results compared to a supervised baseline with the same number of labels. We also find that no AL strategy consistently outperforms the rest. Qualitative analysis suggests that AL helps focus the attention mechanism of BERT on core terms and adjust the boundaries of semantic expansion, highlighting the importance of interpretable models to provide greater control and visibility into this dynamic learning process.