 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Tradeoffs between Invariance and Sensitivity to Adversarial Perturbations
Paper and Code
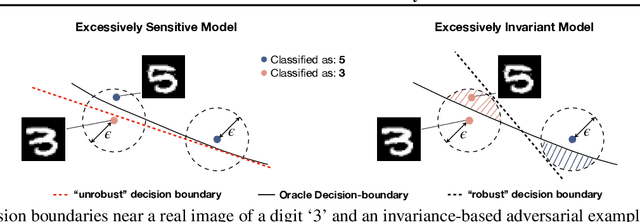

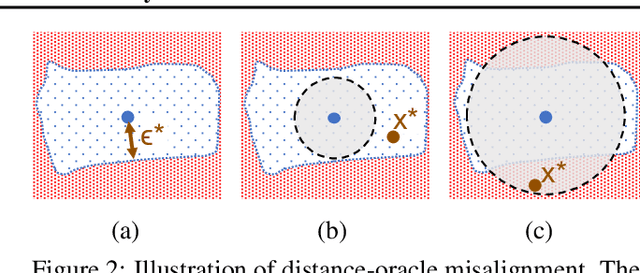
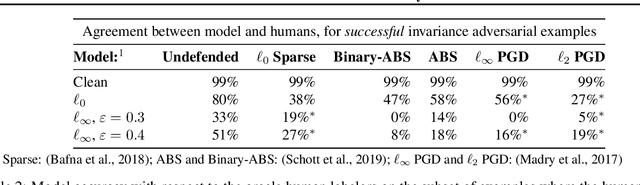
Adversarial examples are malicious inputs crafted to induce misclassification. Commonly studied sensitivity-based adversarial examples introduce semantically-small changes to an input that result in a different model prediction. This paper studies a complementary failure mode, invariance-based adversarial examples, that introduce minimal semantic changes that modify an input's true label yet preserve the model's prediction. We demonstrate fundamental tradeoffs between these two types of adversarial examples. We show that defenses against sensitivity-based attacks actively harm a model's accuracy on invariance-based attacks, and that new approaches are needed to resist both attack types. In particular, we break state-of-the-art adversarially-trained and certifiably-robust models by generating small perturbations that the models are (provably) robust to, yet that change an input's class according to human labelers. Finally, we formally show that the existence of excessively invariant classifiers arises from the presence of overly-robust predictive features in standard datasets.