 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Mixup Regularization
Paper and Code
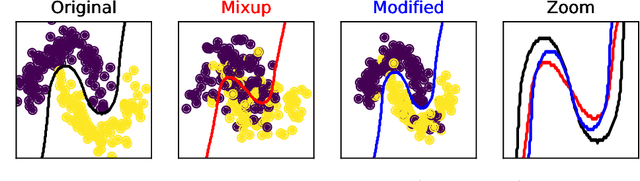

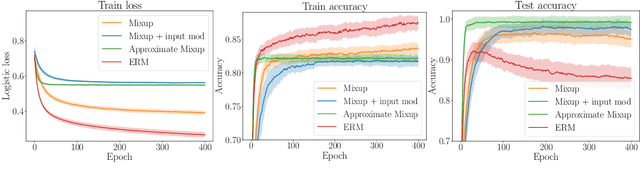
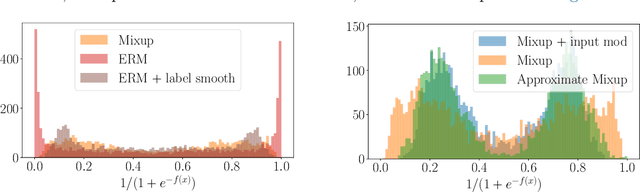
Mixup is a data augmentation technique that creates new examples as convex combinations of training points and labels. This simple technique has empirically shown to improve the accuracy of many state-of-the-art models in different settings and applications, but the reasons behind this empirical success remain poorly understood. In this paper we take a substantial step in explaining the theoretical foundations of Mixup, by clarifying its regularization effects. We show that Mixup can be interpreted as standard empirical risk minimization estimator subject to a combination of data transformation and random perturbation of the transformed data. We further show that these transformations and perturbations induce multiple known regularization schemes, including label smoothing and reduction of the Lipschitz constant of the estimator, and that these schemes interact synergistically with each other, resulting in a self calibrated and effective regularization effect that prevents overfitting and overconfident predictions. We illustrate our theoretical analysis by experiments that empirically support our conclusions.