 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Document Visual Question Answering: A Pilot Study
Paper and Code
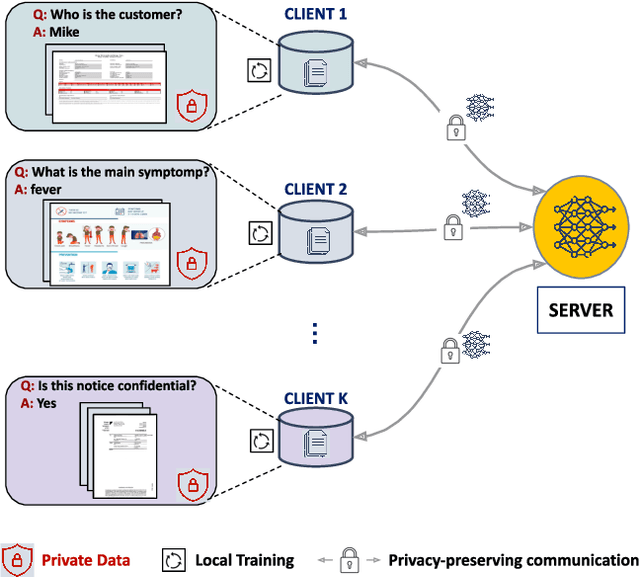


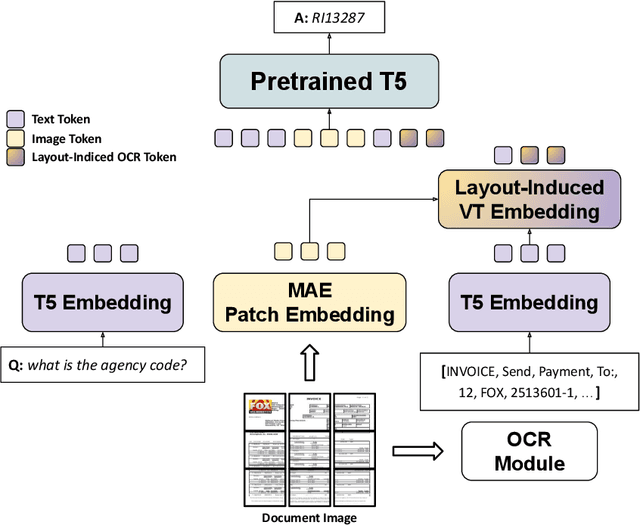
An important handicap of document analysis research is that documents tend to be copyrighted or contain private information, which prohibits their open publication and the creation of centralised, large-scale document datasets. Instead, documents are scattered in private data silos, making extensive training over heterogeneous data a tedious task. In this work, we explore the use of a federated learning (FL) scheme as a way to train a shared model on decentralised private document data. We focus on the problem of Document VQA, a task particularly suited to this approach, as the type of reasoning capabilities required from the model can be quite different in diverse domains. Enabling training over heterogeneous document datasets can thus substantially enrich DocVQA models. We assemble existing DocVQA datasets from diverse domains to reflect the data heterogeneity in real-world applications. We explore the self-pretraining technique in this multi-modal setting, where the same data is used for both pretraining and finetuning, making it relevant for privacy preservation. We further propose combining self-pretraining with a Federated DocVQA training method using centralized adaptive optimization that outperforms the FedAvg baseline. With extensive experiments, we also present a multi-faceted analysis on training DocVQA models with FL, which provides insights for future research on this task. We show that our pretraining strategies can effectively learn and scale up under federated training with diverse DocVQA datasets and tuning hyperparameters is essential for practical document tasks under federation.