 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical structure understanding in complex tables with VLLMs: a benchmark and experiments
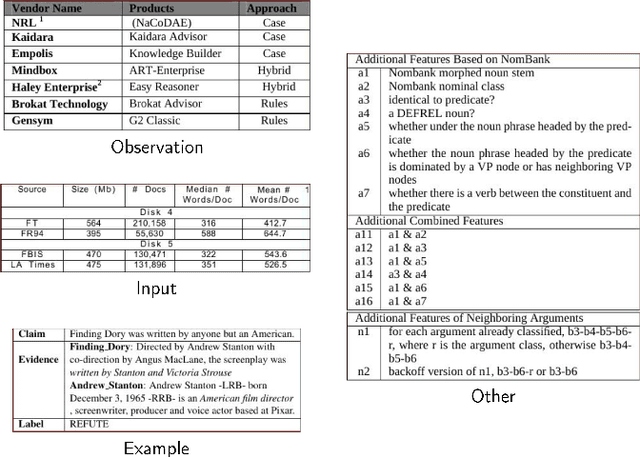
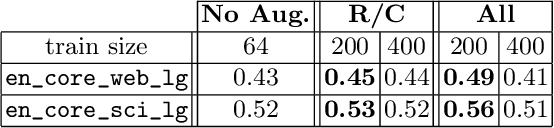
Nov 11, 2025This work investigates the ability of Vision Large Language Models (VLLMs) to understand and interpret the structure of tables in scientific articles. Specifically, we explore whether VLLMs can infer the hierarchical structure of tables without additional processing. As a basis for our experiments we use the PubTables-1M dataset, a large-scale corpus of scientific tables. From this dataset, we extract a subset of tables that we introduce as Complex Hierarchical Tables (CHiTab): a benchmark collection of complex tables containing hierarchical headings. We adopt a series of prompt engineering strategies to probe the models' comprehension capabilities, experimenting with various prompt formats and writing styles. Multiple state-of-the-art open-weights VLLMs are evaluated on the benchmark first using their off-the-shelf versions and then fine-tuning some models on our task. We also measure the performance of humans to solve the task on a small set of tables comparing with performance of the evaluated VLLMs. The experiments support our intuition that generic VLLMs, not explicitly designed for understanding the structure of tables, can perform this task. This study provides insights into the potential and limitations of VLLMs to process complex tables and offers guidance for future work on integrating structured data understanding into general-purpose VLLMs.
BoundingDocs: a Unified Dataset for Document Question Answering with Spatial Annotations
Jan 06, 2025



We present a unified dataset for document Question-Answering (QA), which is obtained combining several public datasets related to Document AI and visually rich document understanding (VRDU). Our main contribution is twofold: on the one hand we reformulate existing Document AI tasks, such as Information Extraction (IE), into a Question-Answering task, making it a suitable resource for training and evaluating Large Language Models; on the other hand, we release the OCR of all the documents and include the exact position of the answer to be found in the document image as a bounding box. Using this dataset, we explore the impact of different prompting techniques (that might include bounding box information) on the performance of open-weight models, identifying the most effective approaches for document comprehension.
CTE: A Dataset for Contextualized Table Extraction
Feb 13, 2023



Relevant information in documents is often summarized in tables, helping the reader to identify useful facts. Most benchmark datasets support either document layout analysis or table understanding, but lack in providing data to apply both tasks in a unified way. We define the task of Contextualized Table Extraction (CTE), which aims to extract and define the structure of tables considering the textual context of the document. The dataset comprises 75k fully annotated pages of scientific papers, including more than 35k tables. Data are gathered from PubMed Central, merging the information provided by annotations in the PubTables-1M and PubLayNet datasets. The dataset can support CTE and adds new classes to the original ones. The generated annotations can be used to develop end-to-end pipelines for various tasks, including document layout analysis, table detection, structure recognition, and functional analysis. We formally define CTE and evaluation metrics, showing which subtasks can be tackled, describing advantages, limitations, and future works of this collection of data. Annotations and code will be accessible a https://github.com/AILab-UniFI/cte-dataset.
Data augmentation on graphs for table type classification
Aug 23, 2022

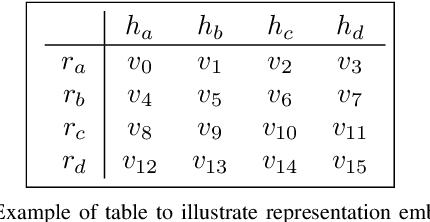
Tables are widely used in documents because of their compact and structured representation of information. In particular, in scientific papers, tables can sum up novel discoveries and summarize experimental results, making the research comparable and easily understandable by scholars. Since the layout of tables is highly variable, it would be useful to interpret their content and classify them into categories. This could be helpful to directly extract information from scientific papers, for instance comparing performance of some models given their paper result tables. In this work, we address the classification of tables using a Graph Neural Network, exploiting the table structure for the message passing algorithm in use. We evaluate our model on a subset of the Tab2Know dataset. Since it contains few examples manually annotated, we propose data augmentation techniques directly on the table graph structures. We achieve promising preliminary results, proposing a data augmentation method suitable for graph-based table representation.
Graph Neural Networks and Representation Embedding for Table Extraction in PDF Documents
Aug 23, 2022

Tables are widely used in several types of documents since they can bring important information in a structured way. In scientific papers, tables can sum up novel discoveries and summarize experimental results, making the research comparable and easily understandable by scholars. Several methods perform table analysis working on document images, losing useful information during the conversion from the PDF files since OCR tools can be prone to recognition errors, in particular for text inside tables. The main contribution of this work is to tackle the problem of table extraction, exploiting Graph Neural Networks. Node features are enriched with suitably designed representation embeddings. These representations help to better distinguish not only tables from the other parts of the paper, but also table cells from table headers. We experimentally evaluated the proposed approach on a new dataset obtained by merging the information provided in the PubLayNet and PubTables-1M datasets.
Doc2Graph: a Task Agnostic Document Understanding Framework based on Graph Neural Networks
Aug 23, 2022


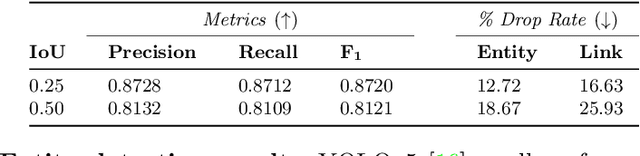
Geometric Deep Learning has recently attracted significant interest in a wide range of machine learning fields, including document analysis. The application of Graph Neural Networks (GNNs) has become crucial in various document-related tasks since they can unravel important structural patterns, fundamental in key information extraction processes. Previous works in the literature propose task-driven models and do not take into account the full power of graphs. We propose Doc2Graph, a task-agnostic document understanding framework based on a GNN model, to solve different tasks given different types of documents. We evaluated our approach on two challenging datasets for key information extraction in form understanding, invoice layout analysis and table detection. Our code is freely accessible on https://github.com/andreagemelli/doc2graph.
Vehicle classification based on convolutional networks applied to FM-CW radar signals
Oct 31, 2017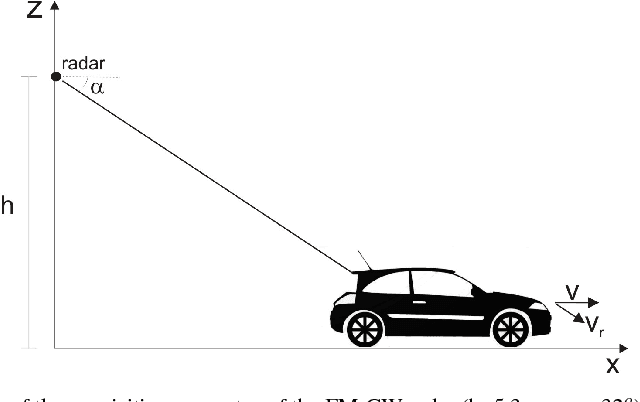
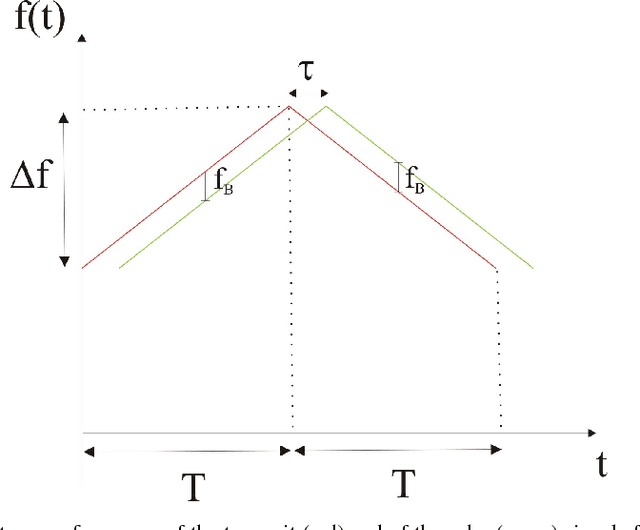
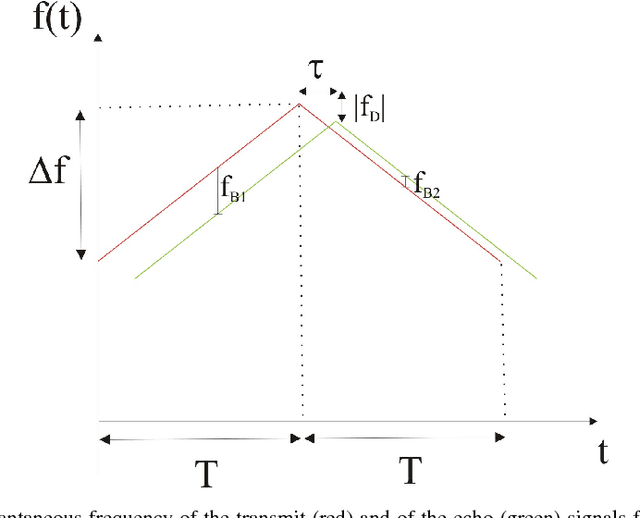
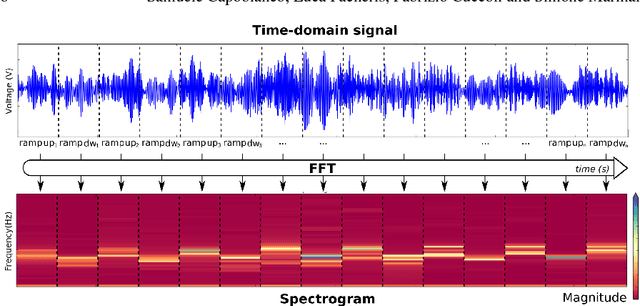
This paper investigates the processing of Frequency Modulated-Continuos Wave (FM-CW) radar signals for vehicle classification. In the last years deep learning has gained interest in several scientific fields and signal processing is not one exception. In this work we address the recognition of the vehicle category using a Convolutional Neural Network (CNN) applied to range Doppler signature. The developed system first transforms the 1-dimensional signal into a 3-dimensional signal that is subsequently used as input to the CNN. When using the trained model to predict the vehicle category we obtain good performance.
* in Proceedings of 1st European Conference on Traffic Mining Applied to Police Activities (TRAP 2017)
DocEmul: a Toolkit to Generate Structured Historical Documents
Oct 10, 2017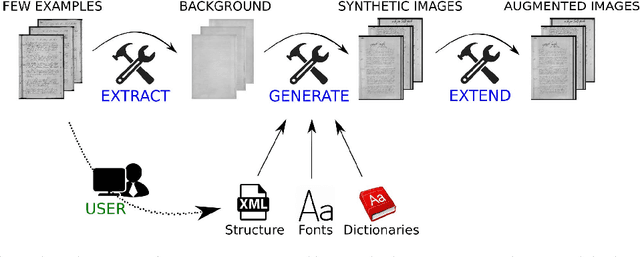



We propose a toolkit to generate structured synthetic documents emulating the actual document production process. Synthetic documents can be used to train systems to perform document analysis tasks. In our case we address the record counting task on handwritten structured collections containing a limited number of examples. Using the DocEmul toolkit we can generate a larger dataset to train a deep architecture to predict the number of records for each page. The toolkit is able to generate synthetic collections and also perform data augmentation to create a larger trainable dataset. It includes one method to extract the page background from real pages which can be used as a substrate where records can be written on the basis of variable structures and using cursive fonts. Moreover, it is possible to extend the synthetic collection by adding random noise, page rotations, and other visual variations. We performed some experiments on two different handwritten collections using the toolkit to generate synthetic data to train a Convolutional Neural Network able to count the number of records in the real collections.
Record Counting in Historical Handwritten Documents with Convolutional Neural Networks
Oct 25, 2016
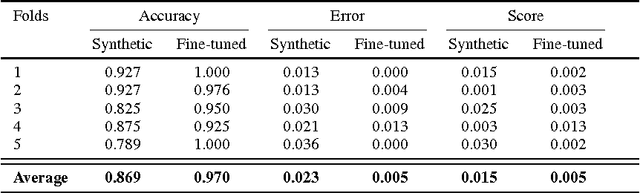
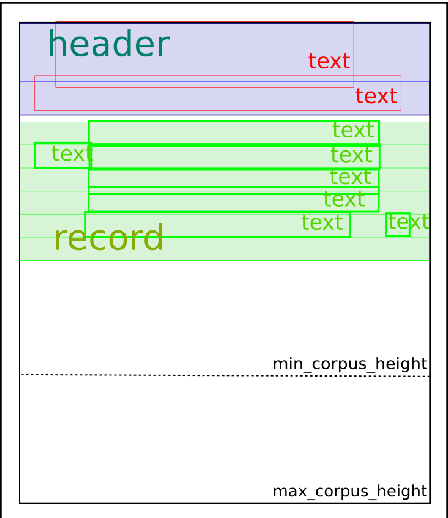

In this paper, we investigate the use of Convolutional Neural Networks for counting the number of records in historical handwritten documents. With this work we demonstrate that training the networks only with synthetic images allows us to perform a near perfect evaluation of the number of records printed on historical documents. The experiments have been performed on a benchmark dataset composed by marriage records and outperform previous results on this dataset.