 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocEmul: a Toolkit to Generate Structured Historical Documents
Paper and Code
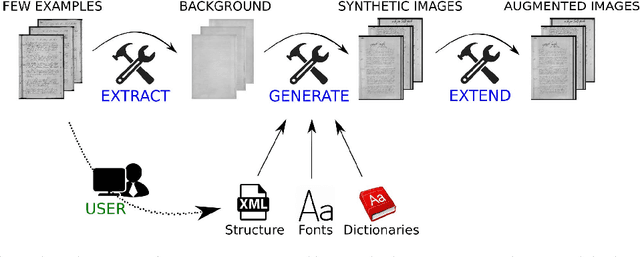



We propose a toolkit to generate structured synthetic documents emulating the actual document production process. Synthetic documents can be used to train systems to perform document analysis tasks. In our case we address the record counting task on handwritten structured collections containing a limited number of examples. Using the DocEmul toolkit we can generate a larger dataset to train a deep architecture to predict the number of records for each page. The toolkit is able to generate synthetic collections and also perform data augmentation to create a larger trainable dataset. It includes one method to extract the page background from real pages which can be used as a substrate where records can be written on the basis of variable structures and using cursive fonts. Moreover, it is possible to extend the synthetic collection by adding random noise, page rotations, and other visual variations. We performed some experiments on two different handwritten collections using the toolkit to generate synthetic data to train a Convolutional Neural Network able to count the number of records in the real collections.