 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComics Datasets Framework: Mix of Comics datasets for detection benchmarking
Paper and Code
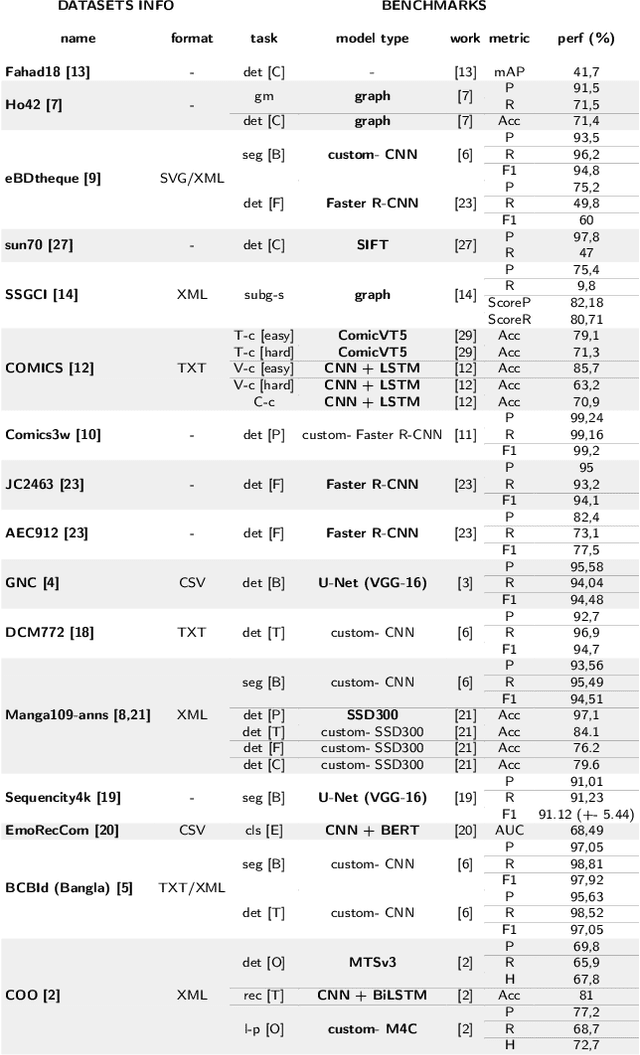
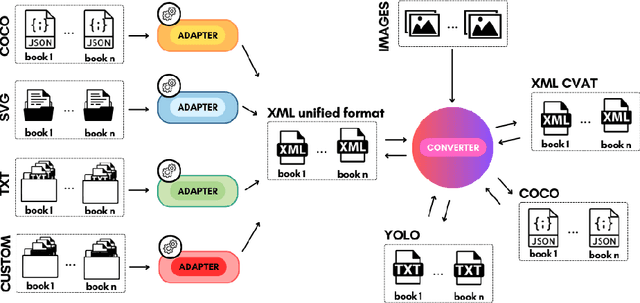
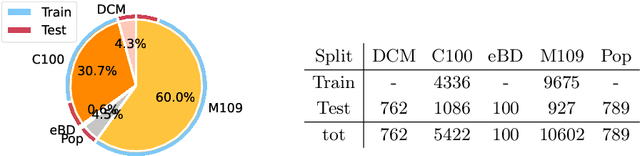
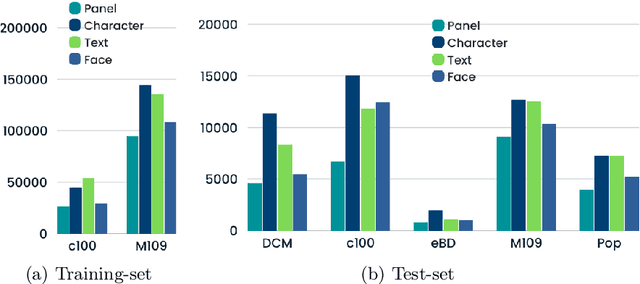
Comics, as a medium, uniquely combine text and images in styles often distinct from real-world visuals. For the past three decades, computational research on comics has evolved from basic object detection to more sophisticated tasks. However, the field faces persistent challenges such as small datasets, inconsistent annotations, inaccessible model weights, and results that cannot be directly compared due to varying train/test splits and metrics. To address these issues, we aim to standardize annotations across datasets, introduce a variety of comic styles into the datasets, and establish benchmark results with clear, replicable settings. Our proposed Comics Datasets Framework standardizes dataset annotations into a common format and addresses the overrepresentation of manga by introducing Comics100, a curated collection of 100 books from the Digital Comics Museum, annotated for detection in our uniform format. We have benchmarked a variety of detection architectures using the Comics Datasets Framework. All related code, model weights, and detailed evaluation processes are available at https://github.com/emanuelevivoli/cdf, ensuring transparency and facilitating replication. This initiative is a significant advancement towards improving object detection in comics, laying the groundwork for more complex computational tasks dependent on precise object recognition.