 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Negative Flips via Margin Preserving Training
Nov 15, 2025Minimizing inconsistencies across successive versions of an AI system is as crucial as reducing the overall error. In image classification, such inconsistencies manifest as negative flips, where an updated model misclassifies test samples that were previously classified correctly. This issue becomes increasingly pronounced as the number of training classes grows over time, since adding new categories reduces the margin of each class and may introduce conflicting patterns that undermine their learning process, thereby degrading performance on the original subset. To mitigate negative flips, we propose a novel approach that preserves the margins of the original model while learning an improved one. Our method encourages a larger relative margin between the previously learned and newly introduced classes by introducing an explicit margin-calibration term on the logits. However, overly constraining the logit margin for the new classes can significantly degrade their accuracy compared to a new independently trained model. To address this, we integrate a double-source focal distillation loss with the previous model and a new independently trained model, learning an appropriate decision margin from both old and new data, even under a logit margin calibration. Extensive experiments on image classification benchmarks demonstrate that our approach consistently reduces the negative flip rate with high overall accuracy.
Backward-Compatible Aligned Representations via an Orthogonal Transformation Layer
Aug 16, 2024
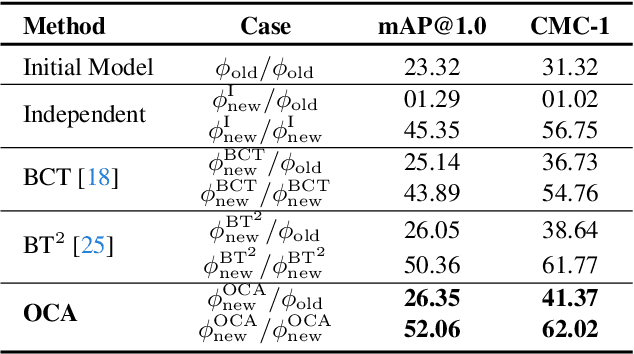

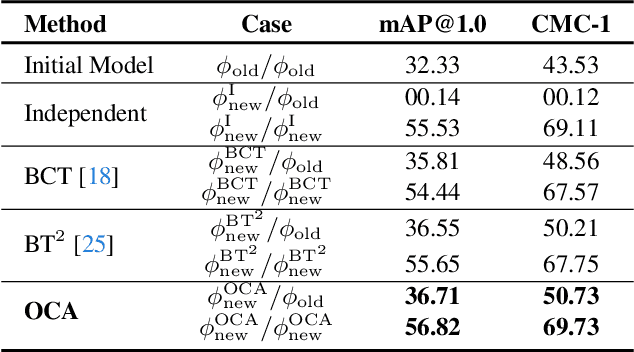
Visual retrieval systems face significant challenges when updating models with improved representations due to misalignment between the old and new representations. The costly and resource-intensive backfilling process involves recalculating feature vectors for images in the gallery set whenever a new model is introduced. To address this, prior research has explored backward-compatible training methods that enable direct comparisons between new and old representations without backfilling. Despite these advancements, achieving a balance between backward compatibility and the performance of independently trained models remains an open problem. In this paper, we address it by expanding the representation space with additional dimensions and learning an orthogonal transformation to achieve compatibility with old models and, at the same time, integrate new information. This transformation preserves the original feature space's geometry, ensuring that our model aligns with previous versions while also learning new data. Our Orthogonal Compatible Aligned (OCA) approach eliminates the need for re-indexing during model updates and ensures that features can be compared directly across different model updates without additional mapping functions. Experimental results on CIFAR-100 and ImageNet-1k demonstrate that our method not only maintains compatibility with previous models but also achieves state-of-the-art accuracy, outperforming several existing methods.
Stationary Representations: Optimally Approximating Compatibility and Implications for Improved Model Replacements
May 04, 2024



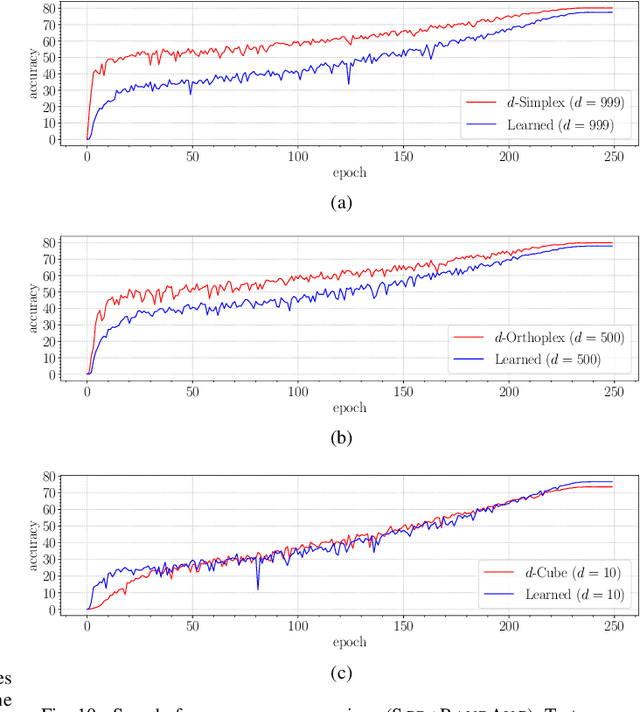
Learning compatible representations enables the interchangeable use of semantic features as models are updated over time. This is particularly relevant in search and retrieval systems where it is crucial to avoid reprocessing of the gallery images with the updated model. While recent research has shown promising empirical evidence, there is still a lack of comprehensive theoretical understanding about learning compatible representations. In this paper, we demonstrate that the stationary representations learned by the $d$-Simplex fixed classifier optimally approximate compatibility representation according to the two inequality constraints of its formal definition. This not only establishes a solid foundation for future works in this line of research but also presents implications that can be exploited in practical learning scenarios. An exemplary application is the now-standard practice of downloading and fine-tuning new pre-trained models. Specifically, we show the strengths and critical issues of stationary representations in the case in which a model undergoing sequential fine-tuning is asynchronously replaced by downloading a better-performing model pre-trained elsewhere. Such a representation enables seamless delivery of retrieval service (i.e., no reprocessing of gallery images) and offers improved performance without operational disruptions during model replacement. Code available at: https://github.com/miccunifi/iamcl2r.
Maximally Compact and Separated Features with Regular Polytope Networks
Jan 15, 2023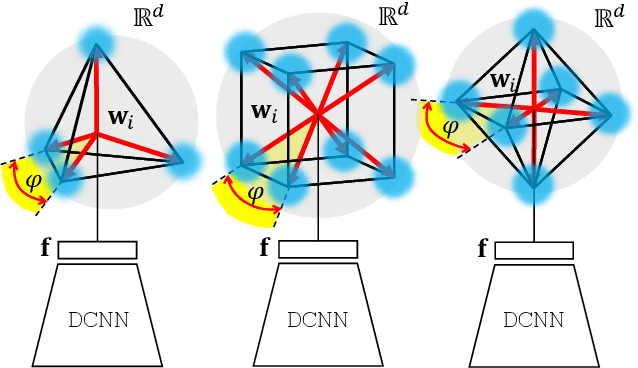
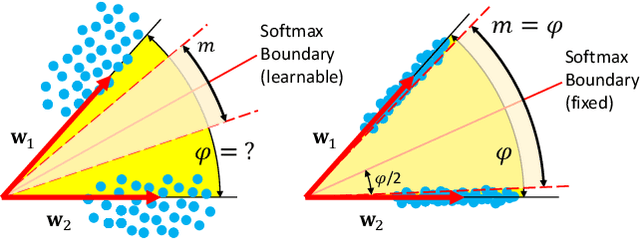
Convolutional Neural Networks (CNNs) trained with the Softmax loss are widely used classification models for several vision tasks. Typically, a learnable transformation (i.e. the classifier) is placed at the end of such models returning class scores that are further normalized into probabilities by Softmax. This learnable transformation has a fundamental role in determining the network internal feature representation. In this work we show how to extract from CNNs features with the properties of \emph{maximum} inter-class separability and \emph{maximum} intra-class compactness by setting the parameters of the classifier transformation as not trainable (i.e. fixed). We obtain features similar to what can be obtained with the well-known ``Center Loss'' \cite{wen2016discriminative} and other similar approaches but with several practical advantages including maximal exploitation of the available feature space representation, reduction in the number of network parameters, no need to use other auxiliary losses besides the Softmax. Our approach unifies and generalizes into a common approach two apparently different classes of methods regarding: discriminative features, pioneered by the Center Loss \cite{wen2016discriminative} and fixed classifiers, firstly evaluated in \cite{hoffer2018fix}. Preliminary qualitative experimental results provide some insight on the potentialities of our combined strategy.
CL2R: Compatible Lifelong Learning Representations
Nov 16, 2022



In this paper, we propose a method to partially mimic natural intelligence for the problem of lifelong learning representations that are compatible. We take the perspective of a learning agent that is interested in recognizing object instances in an open dynamic universe in a way in which any update to its internal feature representation does not render the features in the gallery unusable for visual search. We refer to this learning problem as Compatible Lifelong Learning Representations (CL2R) as it considers compatible representation learning within the lifelong learning paradigm. We identify stationarity as the property that the feature representation is required to hold to achieve compatibility and propose a novel training procedure that encourages local and global stationarity on the learned representation. Due to stationarity, the statistical properties of the learned features do not change over time, making them interoperable with previously learned features. Extensive experiments on standard benchmark datasets show that our CL2R training procedure outperforms alternative baselines and state-of-the-art methods. We also provide novel metrics to specifically evaluate compatible representation learning under catastrophic forgetting in various sequential learning tasks. Code at https://github.com/NiccoBiondi/CompatibleLifelongRepresentation.
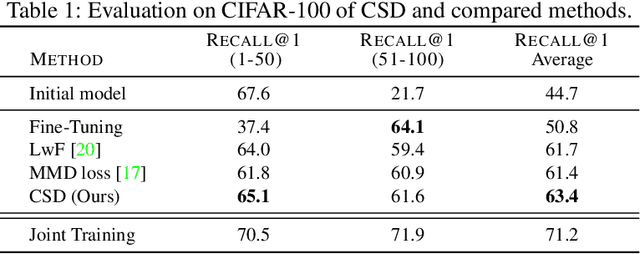
Contrastive Supervised Distillation for Continual Representation Learning
May 11, 2022
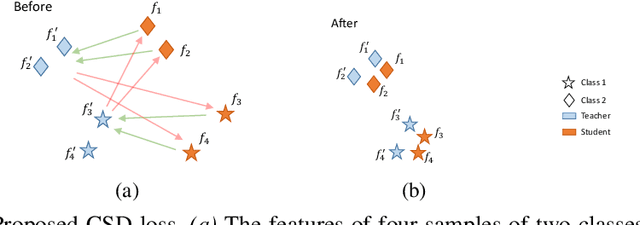

In this paper, we propose a novel training procedure for the continual representation learning problem in which a neural network model is sequentially learned to alleviate catastrophic forgetting in visual search tasks. Our method, called Contrastive Supervised Distillation (CSD), reduces feature forgetting while learning discriminative features. This is achieved by leveraging labels information in a distillation setting in which the student model is contrastively learned from the teacher model. Extensive experiments show that CSD performs favorably in mitigating catastrophic forgetting by outperforming current state-of-the-art methods. Our results also provide further evidence that feature forgetting evaluated in visual retrieval tasks is not as catastrophic as in classification tasks. Code at: https://github.com/NiccoBiondi/ContrastiveSupervisedDistillation.
* Paper published as Oral at ICIAP21
CoReS: Compatible Representations via Stationarity
Nov 15, 2021



In this paper, we propose a novel method to learn internal feature representation models that are \textit{compatible} with previously learned ones. Compatible features enable for direct comparison of old and new learned features, allowing them to be used interchangeably over time. This eliminates the need for visual search systems to extract new features for all previously seen images in the gallery-set when sequentially upgrading the representation model. Extracting new features is typically quite expensive or infeasible in the case of very large gallery-sets and/or real time systems (i.e., face-recognition systems, social networks, life-long learning systems, robotics and surveillance systems). Our approach, called Compatible Representations via Stationarity (CoReS), achieves compatibility by encouraging stationarity to the learned representation model without relying on previously learned models. Stationarity allows features' statistical properties not to change under time shift so that the current learned features are inter-operable with the old ones. We evaluate single and sequential multi-model upgrading in growing large-scale training datasets and we show that our method improves the state-of-the-art in achieving compatible features by a large margin. In particular, upgrading ten times with training data taken from CASIA-WebFace and evaluating in Labeled Face in the Wild (LFW), we obtain a 49\% increase in measuring the average number of times compatibility is achieved, which is a 544\% relative improvement over previous state-of-the-art.
Fine-Grained Adversarial Semi-supervised Learning
Oct 12, 2021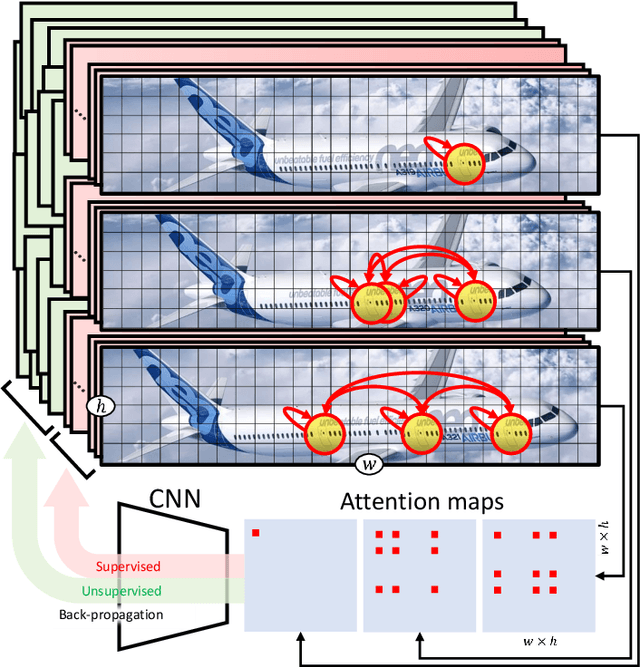

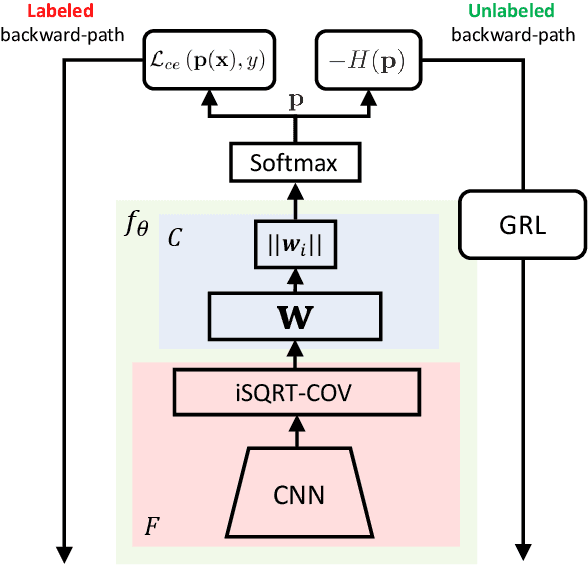
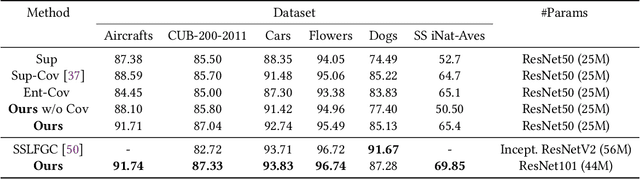
In this paper we exploit Semi-Supervised Learning (SSL) to increase the amount of training data to improve the performance of Fine-Grained Visual Categorization (FGVC). This problem has not been investigated in the past in spite of prohibitive annotation costs that FGVC requires. Our approach leverages unlabeled data with an adversarial optimization strategy in which the internal features representation is obtained with a second-order pooling model. This combination allows to back-propagate the information of the parts, represented by second-order pooling, onto unlabeled data in an adversarial training setting. We demonstrate the effectiveness of the combined use by conducting experiments on six state-of-the-art fine-grained datasets, which include Aircrafts, Stanford Cars, CUB-200-2011, Oxford Flowers, Stanford Dogs, and the recent Semi-Supervised iNaturalist-Aves. Experimental results clearly show that our proposed method has better performance than the only previous approach that examined this problem; it also obtained higher classification accuracy with respect to the supervised learning methods with which we compared.
Regular Polytope Networks
Mar 29, 2021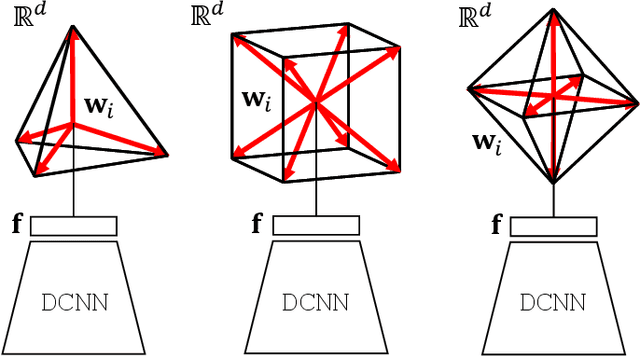
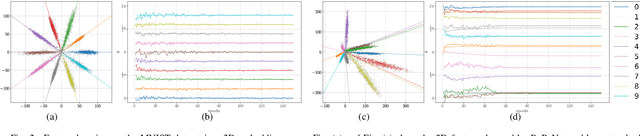
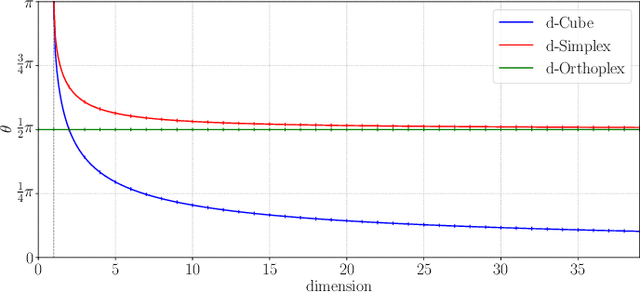
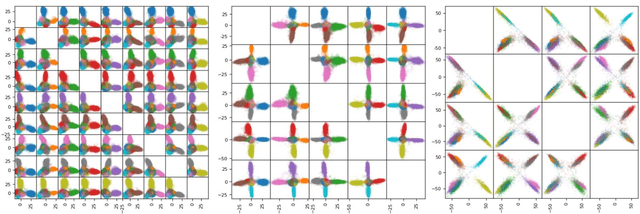
Neural networks are widely used as a model for classification in a large variety of tasks. Typically, a learnable transformation (i.e. the classifier) is placed at the end of such models returning a value for each class used for classification. This transformation plays an important role in determining how the generated features change during the learning process. In this work, we argue that this transformation not only can be fixed (i.e. set as non-trainable) with no loss of accuracy and with a reduction in memory usage, but it can also be used to learn stationary and maximally separated embeddings. We show that the stationarity of the embedding and its maximal separated representation can be theoretically justified by setting the weights of the fixed classifier to values taken from the coordinate vertices of the three regular polytopes available in $\mathbb{R}^d$, namely: the $d$-Simplex, the $d$-Cube and the $d$-Orthoplex. These regular polytopes have the maximal amount of symmetry that can be exploited to generate stationary features angularly centered around their corresponding fixed weights. Our approach improves and broadens the concept of a fixed classifier, recently proposed in \cite{hoffer2018fix}, to a larger class of fixed classifier models. Experimental results confirm the theoretical analysis, the generalization capability, the faster convergence and the improved performance of the proposed method. Code will be publicly available.
* arXiv admin note: substantial text overlap with arXiv:1902.10441
Temporal Binary Representation for Event-Based Action Recognition
Oct 18, 2020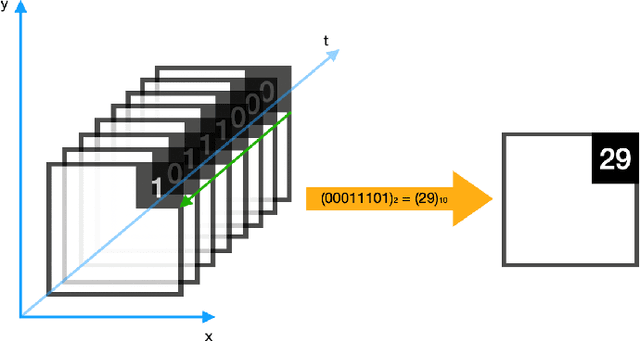


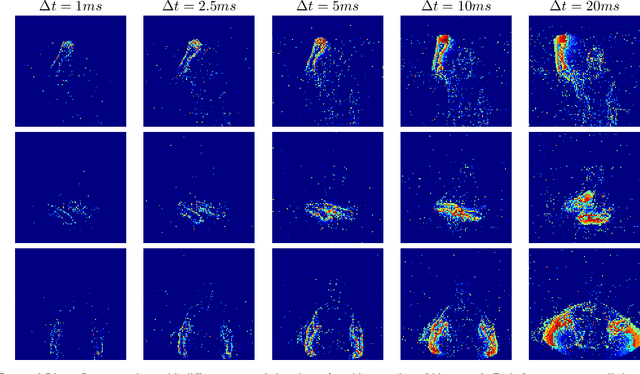
In this paper we present an event aggregation strategy to convert the output of an event camera into frames processable by traditional Computer Vision algorithms. The proposed method first generates sequences of intermediate binary representations, which are then losslessly transformed into a compact format by simply applying a binary-to-decimal conversion. This strategy allows us to encode temporal information directly into pixel values, which are then interpreted by deep learning models. We apply our strategy, called Temporal Binary Representation, to the task of Gesture Recognition, obtaining state of the art results on the popular DVS128 Gesture Dataset. To underline the effectiveness of the proposed method compared to existing ones, we also collect an extension of the dataset under more challenging conditions on which to perform experiments.