 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Binary Representation for Event-Based Action Recognition
Oct 18, 2020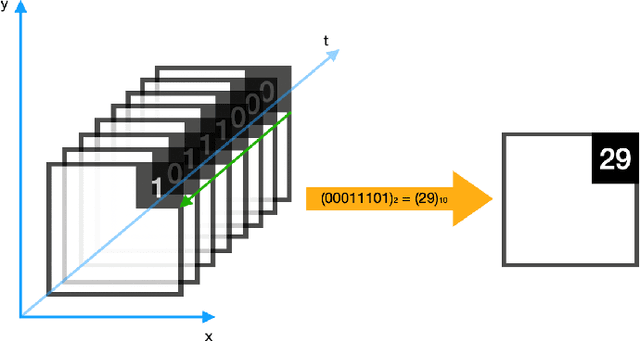


In this paper we present an event aggregation strategy to convert the output of an event camera into frames processable by traditional Computer Vision algorithms. The proposed method first generates sequences of intermediate binary representations, which are then losslessly transformed into a compact format by simply applying a binary-to-decimal conversion. This strategy allows us to encode temporal information directly into pixel values, which are then interpreted by deep learning models. We apply our strategy, called Temporal Binary Representation, to the task of Gesture Recognition, obtaining state of the art results on the popular DVS128 Gesture Dataset. To underline the effectiveness of the proposed method compared to existing ones, we also collect an extension of the dataset under more challenging conditions on which to perform experiments.