 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximally Compact and Separated Features with Regular Polytope Networks
Jan 15, 2023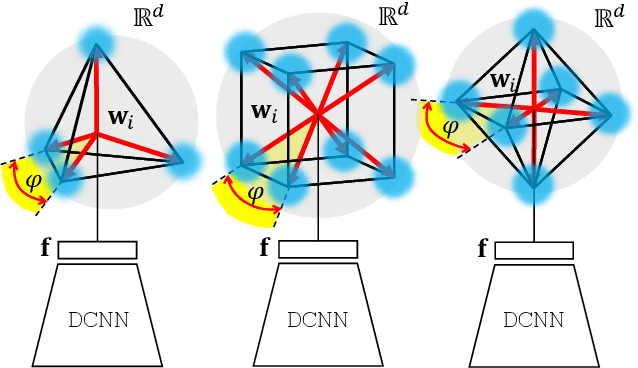
Convolutional Neural Networks (CNNs) trained with the Softmax loss are widely used classification models for several vision tasks. Typically, a learnable transformation (i.e. the classifier) is placed at the end of such models returning class scores that are further normalized into probabilities by Softmax. This learnable transformation has a fundamental role in determining the network internal feature representation. In this work we show how to extract from CNNs features with the properties of \emph{maximum} inter-class separability and \emph{maximum} intra-class compactness by setting the parameters of the classifier transformation as not trainable (i.e. fixed). We obtain features similar to what can be obtained with the well-known ``Center Loss'' \cite{wen2016discriminative} and other similar approaches but with several practical advantages including maximal exploitation of the available feature space representation, reduction in the number of network parameters, no need to use other auxiliary losses besides the Softmax. Our approach unifies and generalizes into a common approach two apparently different classes of methods regarding: discriminative features, pioneered by the Center Loss \cite{wen2016discriminative} and fixed classifiers, firstly evaluated in \cite{hoffer2018fix}. Preliminary qualitative experimental results provide some insight on the potentialities of our combined strategy.
CL2R: Compatible Lifelong Learning Representations
Nov 16, 2022



In this paper, we propose a method to partially mimic natural intelligence for the problem of lifelong learning representations that are compatible. We take the perspective of a learning agent that is interested in recognizing object instances in an open dynamic universe in a way in which any update to its internal feature representation does not render the features in the gallery unusable for visual search. We refer to this learning problem as Compatible Lifelong Learning Representations (CL2R) as it considers compatible representation learning within the lifelong learning paradigm. We identify stationarity as the property that the feature representation is required to hold to achieve compatibility and propose a novel training procedure that encourages local and global stationarity on the learned representation. Due to stationarity, the statistical properties of the learned features do not change over time, making them interoperable with previously learned features. Extensive experiments on standard benchmark datasets show that our CL2R training procedure outperforms alternative baselines and state-of-the-art methods. We also provide novel metrics to specifically evaluate compatible representation learning under catastrophic forgetting in various sequential learning tasks. Code at https://github.com/NiccoBiondi/CompatibleLifelongRepresentation.
Contrastive Supervised Distillation for Continual Representation Learning
May 11, 2022
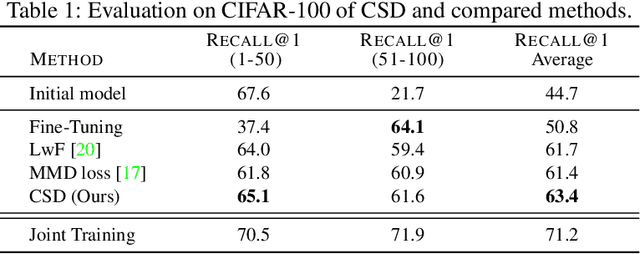
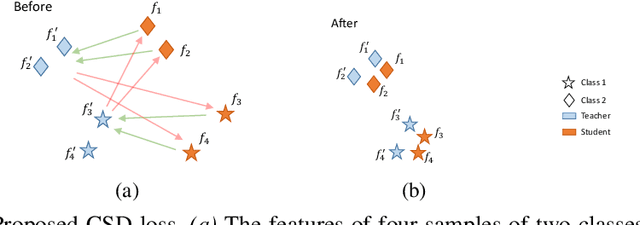

In this paper, we propose a novel training procedure for the continual representation learning problem in which a neural network model is sequentially learned to alleviate catastrophic forgetting in visual search tasks. Our method, called Contrastive Supervised Distillation (CSD), reduces feature forgetting while learning discriminative features. This is achieved by leveraging labels information in a distillation setting in which the student model is contrastively learned from the teacher model. Extensive experiments show that CSD performs favorably in mitigating catastrophic forgetting by outperforming current state-of-the-art methods. Our results also provide further evidence that feature forgetting evaluated in visual retrieval tasks is not as catastrophic as in classification tasks. Code at: https://github.com/NiccoBiondi/ContrastiveSupervisedDistillation.
* Paper published as Oral at ICIAP21
CoReS: Compatible Representations via Stationarity
Nov 15, 2021



In this paper, we propose a novel method to learn internal feature representation models that are \textit{compatible} with previously learned ones. Compatible features enable for direct comparison of old and new learned features, allowing them to be used interchangeably over time. This eliminates the need for visual search systems to extract new features for all previously seen images in the gallery-set when sequentially upgrading the representation model. Extracting new features is typically quite expensive or infeasible in the case of very large gallery-sets and/or real time systems (i.e., face-recognition systems, social networks, life-long learning systems, robotics and surveillance systems). Our approach, called Compatible Representations via Stationarity (CoReS), achieves compatibility by encouraging stationarity to the learned representation model without relying on previously learned models. Stationarity allows features' statistical properties not to change under time shift so that the current learned features are inter-operable with the old ones. We evaluate single and sequential multi-model upgrading in growing large-scale training datasets and we show that our method improves the state-of-the-art in achieving compatible features by a large margin. In particular, upgrading ten times with training data taken from CASIA-WebFace and evaluating in Labeled Face in the Wild (LFW), we obtain a 49\% increase in measuring the average number of times compatibility is achieved, which is a 544\% relative improvement over previous state-of-the-art.
Regular Polytope Networks
Mar 29, 2021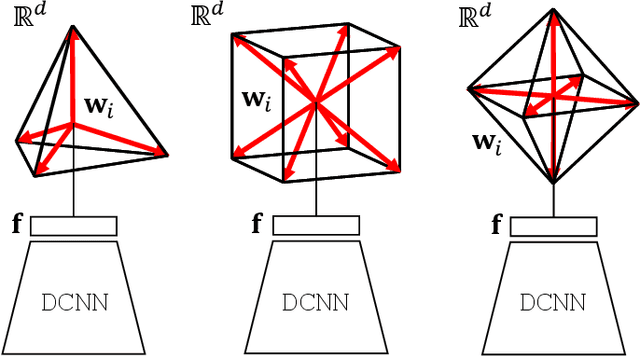
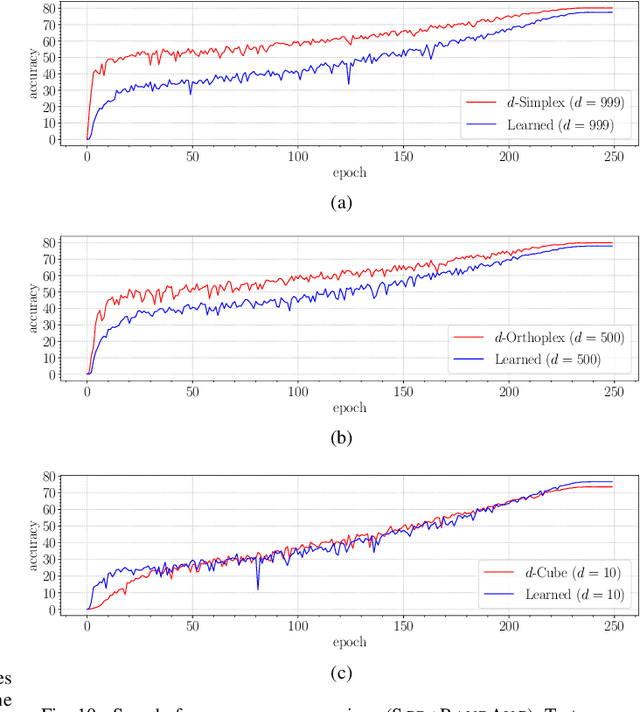
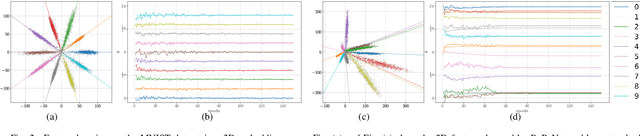
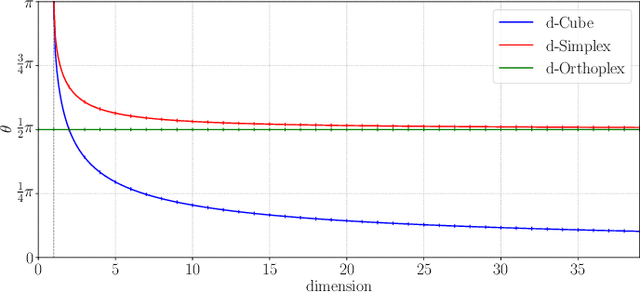
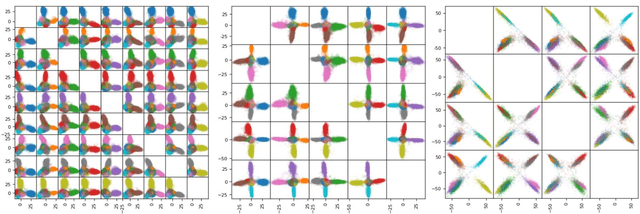
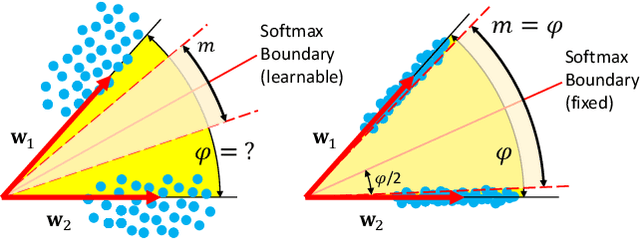
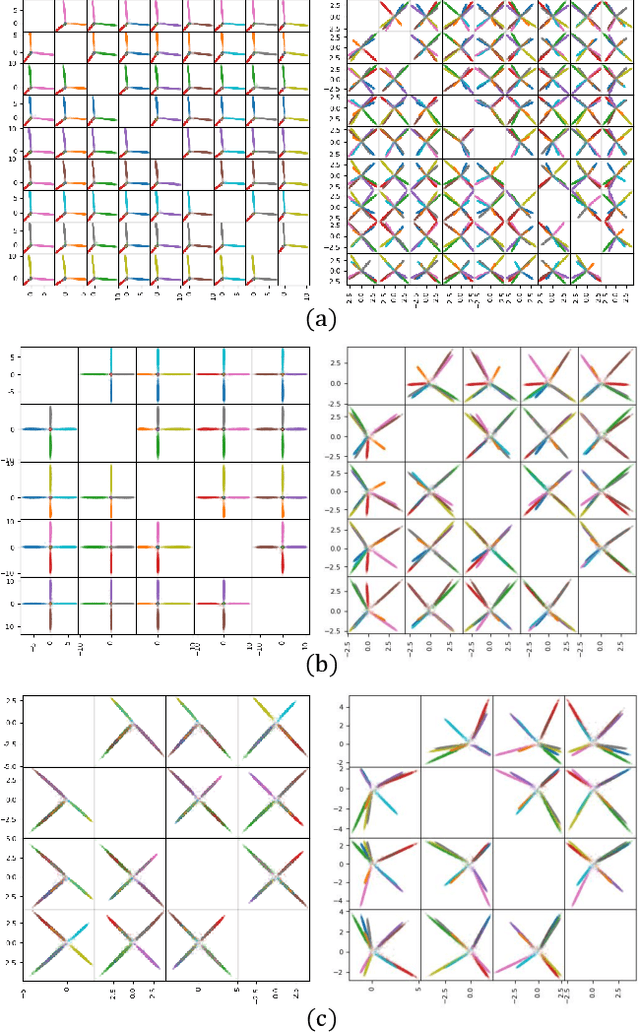
Neural networks are widely used as a model for classification in a large variety of tasks. Typically, a learnable transformation (i.e. the classifier) is placed at the end of such models returning a value for each class used for classification. This transformation plays an important role in determining how the generated features change during the learning process. In this work, we argue that this transformation not only can be fixed (i.e. set as non-trainable) with no loss of accuracy and with a reduction in memory usage, but it can also be used to learn stationary and maximally separated embeddings. We show that the stationarity of the embedding and its maximal separated representation can be theoretically justified by setting the weights of the fixed classifier to values taken from the coordinate vertices of the three regular polytopes available in $\mathbb{R}^d$, namely: the $d$-Simplex, the $d$-Cube and the $d$-Orthoplex. These regular polytopes have the maximal amount of symmetry that can be exploited to generate stationary features angularly centered around their corresponding fixed weights. Our approach improves and broadens the concept of a fixed classifier, recently proposed in \cite{hoffer2018fix}, to a larger class of fixed classifier models. Experimental results confirm the theoretical analysis, the generalization capability, the faster convergence and the improved performance of the proposed method. Code will be publicly available.
* arXiv admin note: substantial text overlap with arXiv:1902.10441
Class-incremental Learning with Pre-allocated Fixed Classifiers
Oct 16, 2020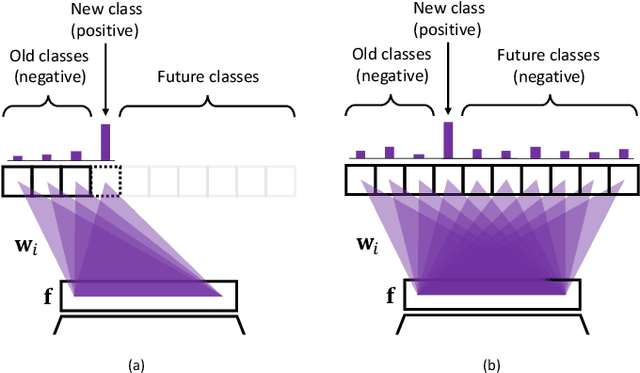
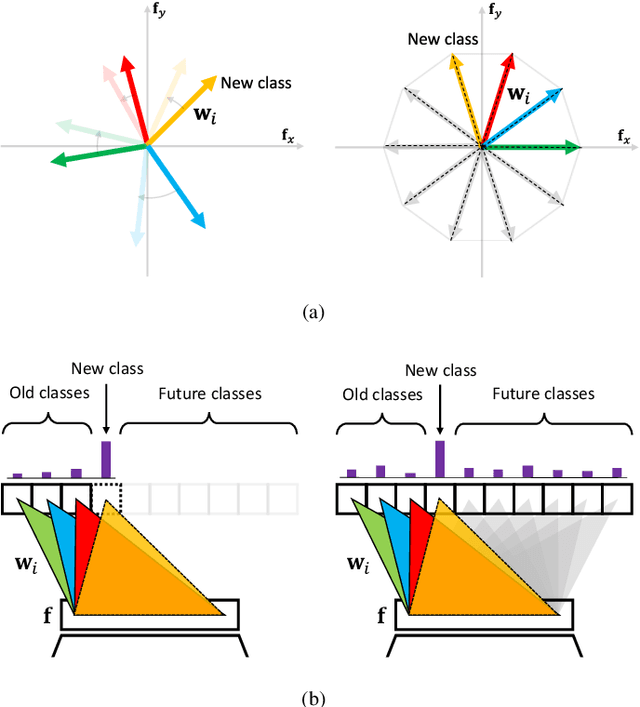
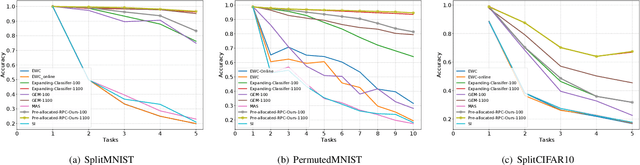
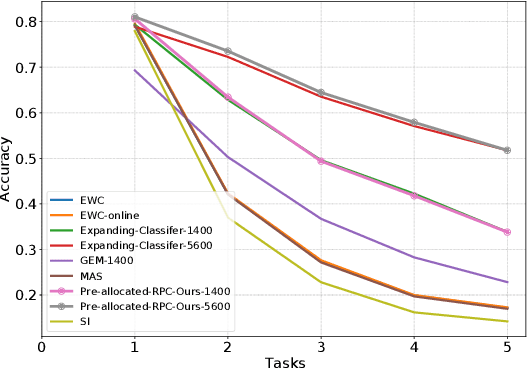
In class-incremental learning, a learning agent faces a stream of data with the goal of learning new classes while not forgetting previous ones. Neural networks are known to suffer under this setting, as they forget previously acquired knowledge. To address this problem, effective methods exploit past data stored in an episodic memory while expanding the final classifier nodes to accommodate the new classes. In this work, we substitute the expanding classifier with a novel fixed classifier in which a number of pre-allocated output nodes are subject to the classification loss right from the beginning of the learning phase. Contrarily to the standard expanding classifier, this allows: (a) the output nodes of future unseen classes to firstly see negative samples since the beginning of learning together with the positive samples that incrementally arrive; (b) to learn features that do not change their geometric configuration as novel classes are incorporated in the learning model. Experiments with public datasets show that the proposed approach is as effective as the expanding classifier while exhibiting novel intriguing properties of the internal feature representation that are otherwise not-existent. Our ablation study on pre-allocating a large number of classes further validates the approach.
Fix Your Features: Stationary and Maximally Discriminative Embeddings using Regular Polytope (Fixed Classifier) Networks
Mar 01, 2019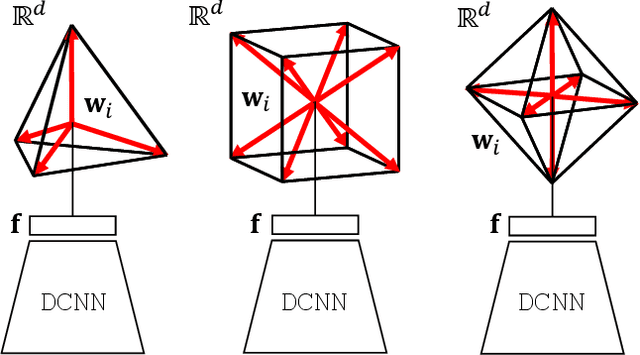

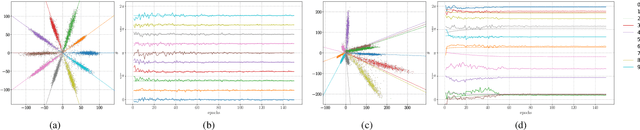
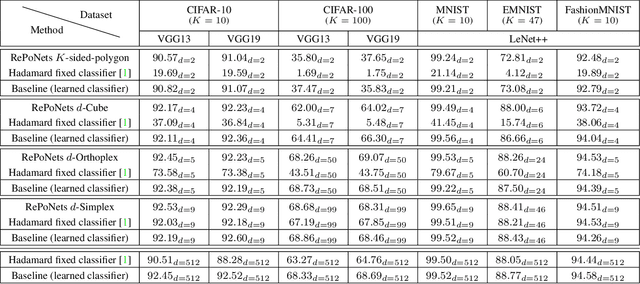
Neural networks are widely used as a model for classification in a large variety of tasks. Typically, a learnable transformation (i.e. the classifier) is placed at the end of such models returning a value for each class used for classification. This transformation plays an important role in determining how the generated features change during the learning process. In this work we argue that this transformation not only can be fixed (i.e. set as non trainable) with no loss of accuracy, but it can also be used to learn stationary and maximally discriminative embeddings. We show that the stationarity of the embedding and its maximal discriminative representation can be theoretically justified by setting the weights of the fixed classifier to values taken from the coordinate vertices of three regular polytopes available in $\mathbb{R}^d$, namely: the $d$-Simplex, the $d$-Cube and the $d$-Orthoplex. These regular polytopes have the maximal amount of symmetry that can be exploited to generate stationary features angularly centered around their corresponding fixed weights. Our approach improves and broadens the concept of a fixed classifier, recently proposed in \cite{hoffer2018fix}, to a larger class of fixed classifier models. Experimental results confirm both the theoretical analysis and the generalization capability of the proposed method.
Memory Based Online Learning of Deep Representations from Video Streams
Nov 17, 2017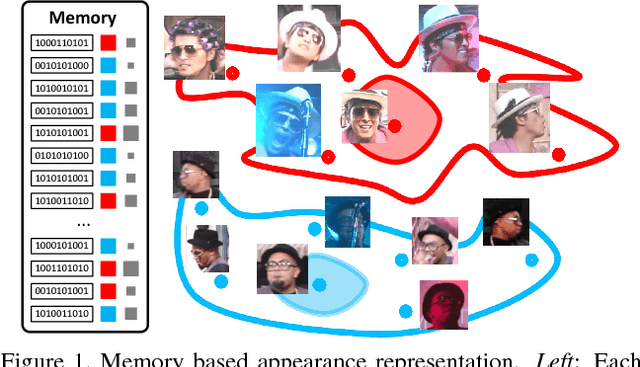
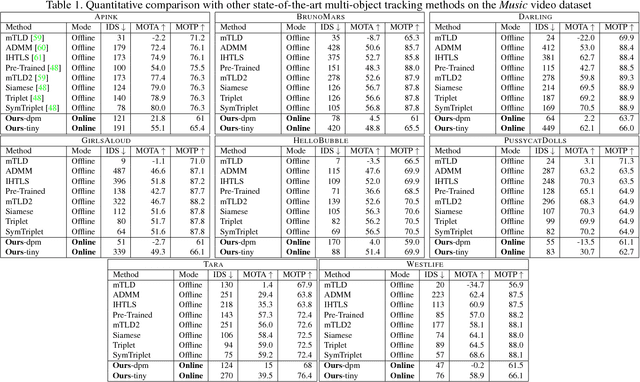
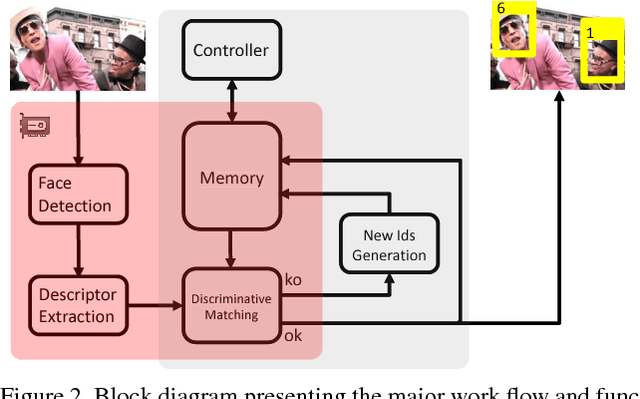
We present a novel online unsupervised method for face identity learning from video streams. The method exploits deep face descriptors together with a memory based learning mechanism that takes advantage of the temporal coherence of visual data. Specifically, we introduce a discriminative feature matching solution based on Reverse Nearest Neighbour and a feature forgetting strategy that detect redundant features and discard them appropriately while time progresses. It is shown that the proposed learning procedure is asymptotically stable and can be effectively used in relevant applications like multiple face identification and tracking from unconstrained video streams. Experimental results show that the proposed method achieves comparable results in the task of multiple face tracking and better performance in face identification with offline approaches exploiting future information. Code will be publicly available.