 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximally Compact and Separated Features with Regular Polytope Networks
Jan 15, 2023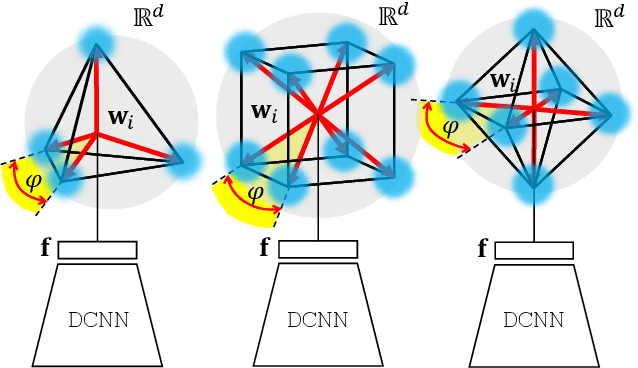
Convolutional Neural Networks (CNNs) trained with the Softmax loss are widely used classification models for several vision tasks. Typically, a learnable transformation (i.e. the classifier) is placed at the end of such models returning class scores that are further normalized into probabilities by Softmax. This learnable transformation has a fundamental role in determining the network internal feature representation. In this work we show how to extract from CNNs features with the properties of \emph{maximum} inter-class separability and \emph{maximum} intra-class compactness by setting the parameters of the classifier transformation as not trainable (i.e. fixed). We obtain features similar to what can be obtained with the well-known ``Center Loss'' \cite{wen2016discriminative} and other similar approaches but with several practical advantages including maximal exploitation of the available feature space representation, reduction in the number of network parameters, no need to use other auxiliary losses besides the Softmax. Our approach unifies and generalizes into a common approach two apparently different classes of methods regarding: discriminative features, pioneered by the Center Loss \cite{wen2016discriminative} and fixed classifiers, firstly evaluated in \cite{hoffer2018fix}. Preliminary qualitative experimental results provide some insight on the potentialities of our combined strategy.
Fashion Recommendation Based on Style and Social Events
Aug 01, 2022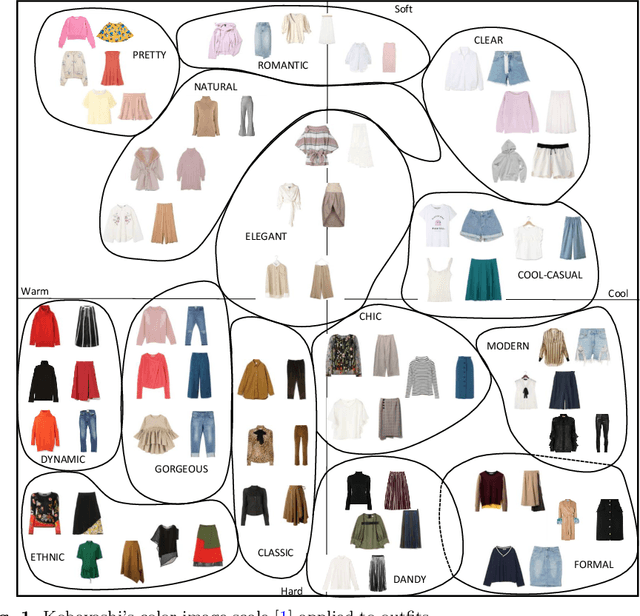
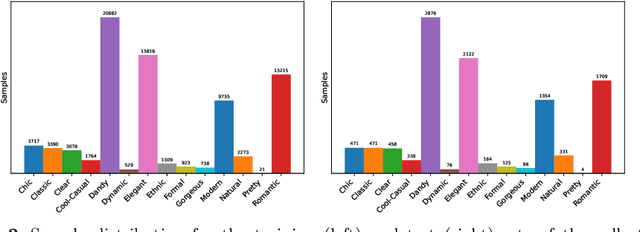


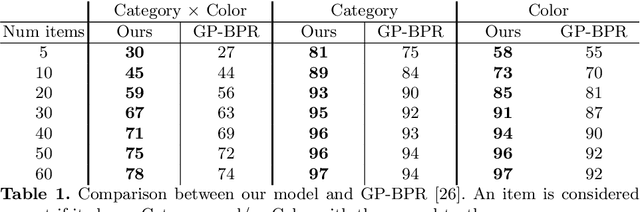
Fashion recommendation is often declined as the task of finding complementary items given a query garment or retrieving outfits that are suitable for a given user. In this work we address the problem by adding an additional semantic layer based on the style of the proposed dressing. We model style according to two important aspects: the mood and the emotion concealed behind color combination patterns and the appropriateness of the retrieved garments for a given type of social event. To address the former we rely on Shigenobu Kobayashi's color image scale, which associated emotional patterns and moods to color triples. The latter instead is analyzed by extracting garments from images of social events. Overall, we integrate in a state of the art garment recommendation framework a style classifier and an event classifier in order to condition recommendation on a given query.
Regular Polytope Networks
Mar 29, 2021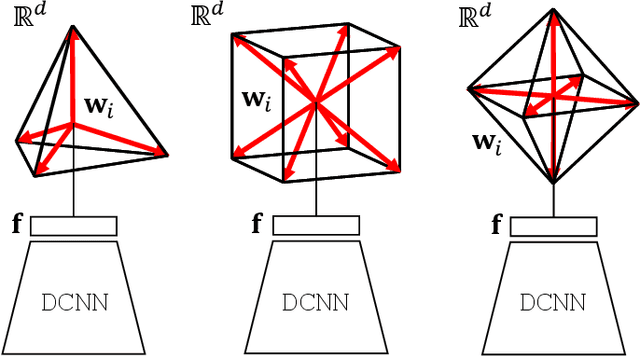
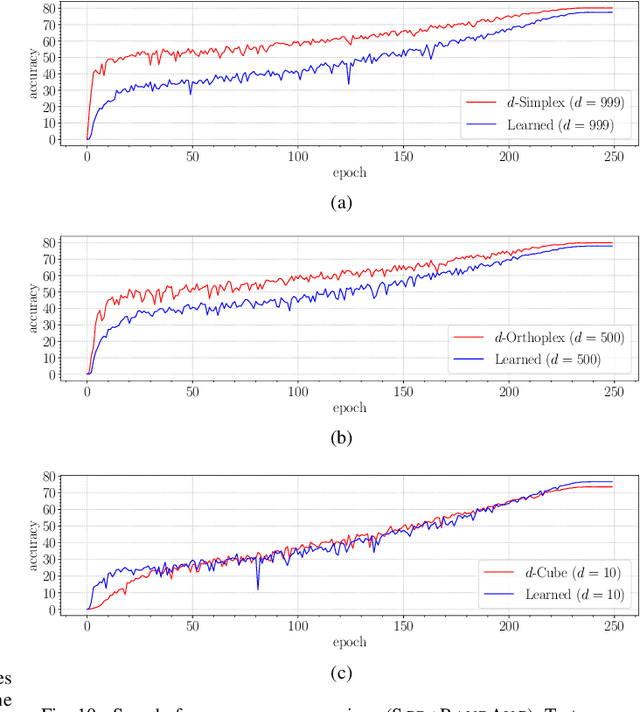
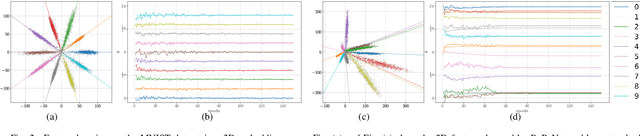
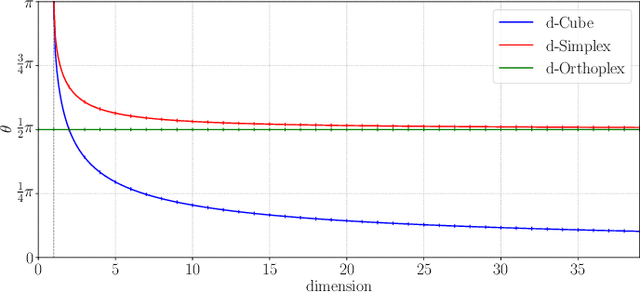
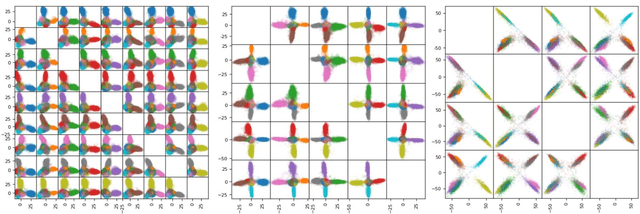
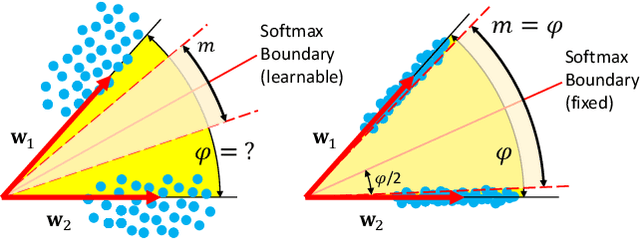
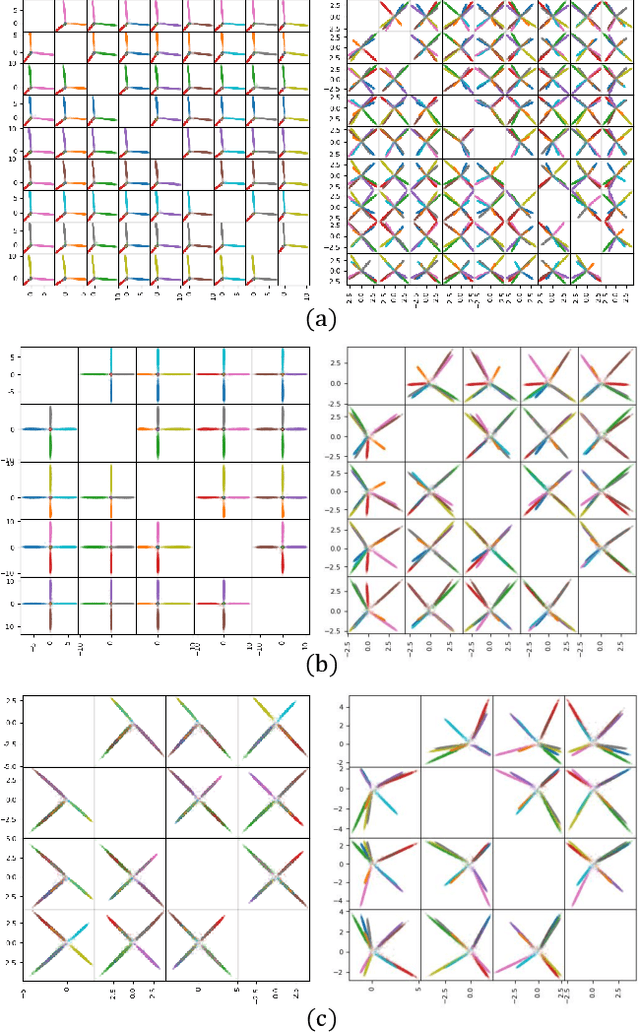
Neural networks are widely used as a model for classification in a large variety of tasks. Typically, a learnable transformation (i.e. the classifier) is placed at the end of such models returning a value for each class used for classification. This transformation plays an important role in determining how the generated features change during the learning process. In this work, we argue that this transformation not only can be fixed (i.e. set as non-trainable) with no loss of accuracy and with a reduction in memory usage, but it can also be used to learn stationary and maximally separated embeddings. We show that the stationarity of the embedding and its maximal separated representation can be theoretically justified by setting the weights of the fixed classifier to values taken from the coordinate vertices of the three regular polytopes available in $\mathbb{R}^d$, namely: the $d$-Simplex, the $d$-Cube and the $d$-Orthoplex. These regular polytopes have the maximal amount of symmetry that can be exploited to generate stationary features angularly centered around their corresponding fixed weights. Our approach improves and broadens the concept of a fixed classifier, recently proposed in \cite{hoffer2018fix}, to a larger class of fixed classifier models. Experimental results confirm the theoretical analysis, the generalization capability, the faster convergence and the improved performance of the proposed method. Code will be publicly available.
* arXiv admin note: substantial text overlap with arXiv:1902.10441
Garment Recommendation with Memory Augmented Neural Networks
Dec 11, 2020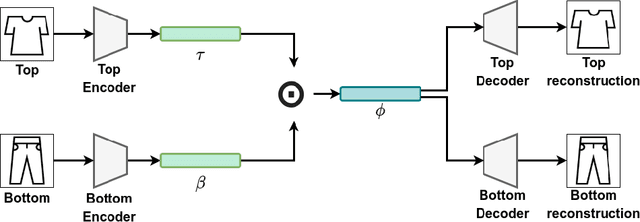
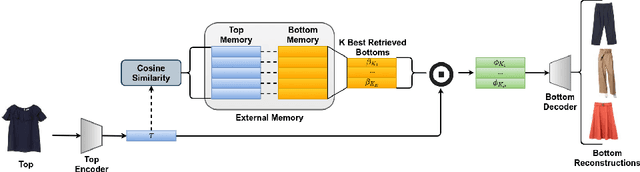

Fashion plays a pivotal role in society. Combining garments appropriately is essential for people to communicate their personality and style. Also different events require outfits to be thoroughly chosen to comply with underlying social clothing rules. Therefore, combining garments appropriately might not be trivial. The fashion industry has turned this into a massive source of income, relying on complex recommendation systems to retrieve and suggest appropriate clothing items for customers. To perform better recommendations, personalized suggestions can be performed, taking into account user preferences or purchase histories. In this paper, we propose a garment recommendation system to pair different clothing items, namely tops and bottoms, exploiting a Memory Augmented Neural Network (MANN). By training a memory writing controller, we are able to store a non-redundant subset of samples, which is then used to retrieve a ranked list of suitable bottoms to complement a given top. In particular, we aim at retrieving a variety of modalities in which a certain garment can be combined. To refine our recommendations, we then include user preferences via Matrix Factorization. We experiment on IQON3000, a dataset collected from an online fashion community, reporting state of the art results.
Class-incremental Learning with Pre-allocated Fixed Classifiers
Oct 16, 2020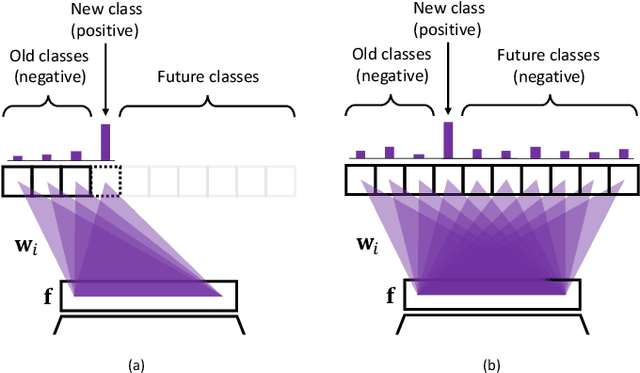
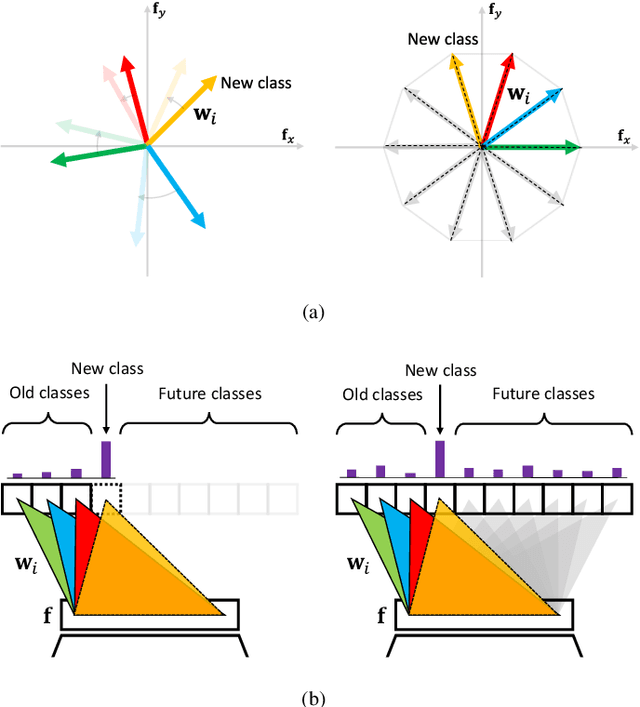
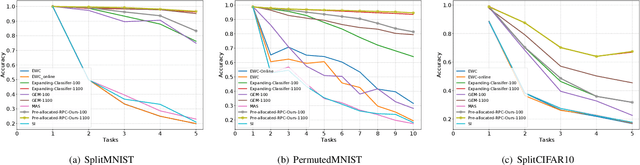
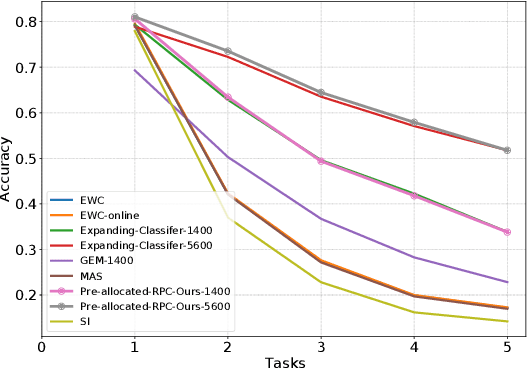
In class-incremental learning, a learning agent faces a stream of data with the goal of learning new classes while not forgetting previous ones. Neural networks are known to suffer under this setting, as they forget previously acquired knowledge. To address this problem, effective methods exploit past data stored in an episodic memory while expanding the final classifier nodes to accommodate the new classes. In this work, we substitute the expanding classifier with a novel fixed classifier in which a number of pre-allocated output nodes are subject to the classification loss right from the beginning of the learning phase. Contrarily to the standard expanding classifier, this allows: (a) the output nodes of future unseen classes to firstly see negative samples since the beginning of learning together with the positive samples that incrementally arrive; (b) to learn features that do not change their geometric configuration as novel classes are incorporated in the learning model. Experiments with public datasets show that the proposed approach is as effective as the expanding classifier while exhibiting novel intriguing properties of the internal feature representation that are otherwise not-existent. Our ablation study on pre-allocating a large number of classes further validates the approach.
Fix Your Features: Stationary and Maximally Discriminative Embeddings using Regular Polytope (Fixed Classifier) Networks
Mar 01, 2019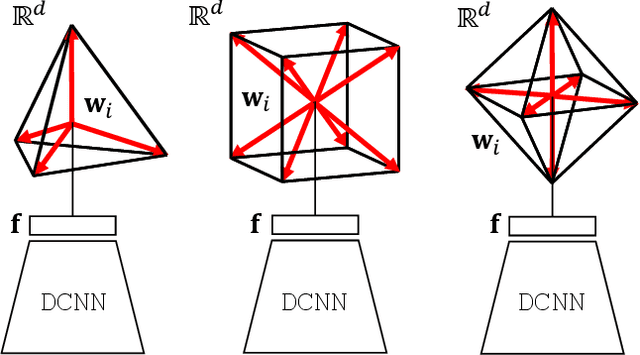

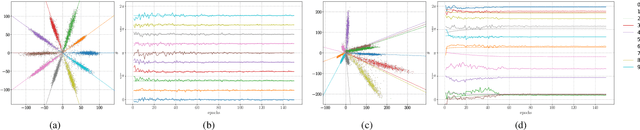
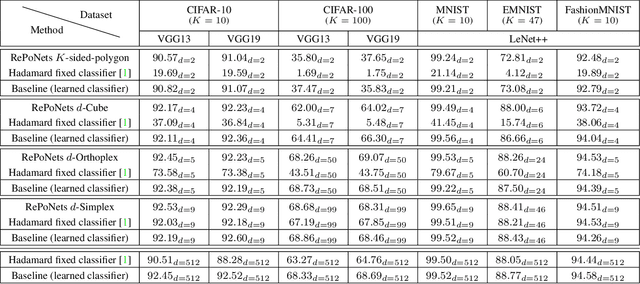
Neural networks are widely used as a model for classification in a large variety of tasks. Typically, a learnable transformation (i.e. the classifier) is placed at the end of such models returning a value for each class used for classification. This transformation plays an important role in determining how the generated features change during the learning process. In this work we argue that this transformation not only can be fixed (i.e. set as non trainable) with no loss of accuracy, but it can also be used to learn stationary and maximally discriminative embeddings. We show that the stationarity of the embedding and its maximal discriminative representation can be theoretically justified by setting the weights of the fixed classifier to values taken from the coordinate vertices of three regular polytopes available in $\mathbb{R}^d$, namely: the $d$-Simplex, the $d$-Cube and the $d$-Orthoplex. These regular polytopes have the maximal amount of symmetry that can be exploited to generate stationary features angularly centered around their corresponding fixed weights. Our approach improves and broadens the concept of a fixed classifier, recently proposed in \cite{hoffer2018fix}, to a larger class of fixed classifier models. Experimental results confirm both the theoretical analysis and the generalization capability of the proposed method.
Segmentation Free Object Discovery in Video
Sep 01, 2016
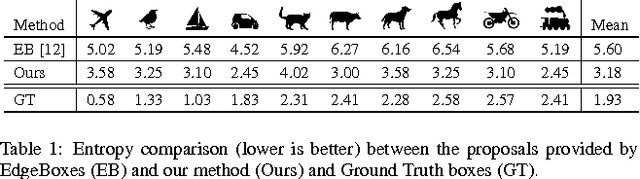


In this paper we present a simple yet effective approach to extend without supervision any object proposal from static images to videos. Unlike previous methods, these spatio-temporal proposals, to which we refer as tracks, are generated relying on little or no visual content by only exploiting bounding boxes spatial correlations through time. The tracks that we obtain are likely to represent objects and are a general-purpose tool to represent meaningful video content for a wide variety of tasks. For unannotated videos, tracks can be used to discover content without any supervision. As further contribution we also propose a novel and dataset-independent method to evaluate a generic object proposal based on the entropy of a classifier output response. We experiment on two competitive datasets, namely YouTube Objects and ILSVRC-2015 VID.