 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation Free Object Discovery in Video
Sep 01, 2016
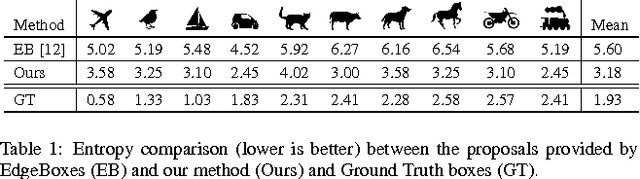


In this paper we present a simple yet effective approach to extend without supervision any object proposal from static images to videos. Unlike previous methods, these spatio-temporal proposals, to which we refer as tracks, are generated relying on little or no visual content by only exploiting bounding boxes spatial correlations through time. The tracks that we obtain are likely to represent objects and are a general-purpose tool to represent meaningful video content for a wide variety of tasks. For unannotated videos, tracks can be used to discover content without any supervision. As further contribution we also propose a novel and dataset-independent method to evaluate a generic object proposal based on the entropy of a classifier output response. We experiment on two competitive datasets, namely YouTube Objects and ILSVRC-2015 VID.