 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARReL: Bottleneck Attention for Adversarial Robustness in Vision-Based Reinforcement Learning
Paper and Code
Aug 22, 2022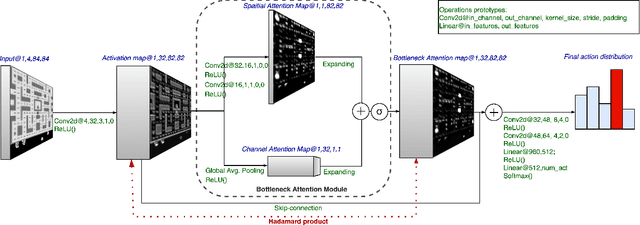



Robustness to adversarial perturbations has been explored in many areas of computer vision. This robustness is particularly relevant in vision-based reinforcement learning, as the actions of autonomous agents might be safety-critic or impactful in the real world. We investigate the susceptibility of vision-based reinforcement learning agents to gradient-based adversarial attacks and evaluate a potential defense. We observe that Bottleneck Attention Modules (BAM) included in CNN architectures can act as potential tools to increase robustness against adversarial attacks. We show how learned attention maps can be used to recover activations of a convolutional layer by restricting the spatial activations to salient regions. Across a number of RL environments, BAM-enhanced architectures show increased robustness during inference. Finally, we discuss potential future research directions.