 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Enable Uncertainty Estimation in Proximal Policy Optimization
Paper and Code
Oct 07, 2022
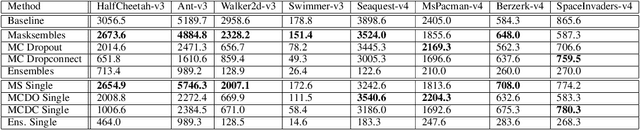
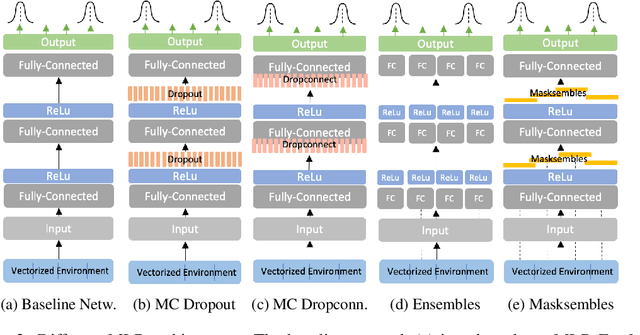
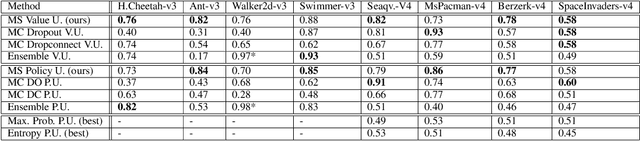
While deep reinforcement learning (RL) agents have showcased strong results across many domains, a major concern is their inherent opaqueness and the safety of such systems in real-world use cases. To overcome these issues, we need agents that can quantify their uncertainty and detect out-of-distribution (OOD) states. Existing uncertainty estimation techniques, like Monte-Carlo Dropout or Deep Ensembles, have not seen widespread adoption in on-policy deep RL. We posit that this is due to two reasons: concepts like uncertainty and OOD states are not well defined compared to supervised learning, especially for on-policy RL methods. Secondly, available implementations and comparative studies for uncertainty estimation methods in RL have been limited. To overcome the first gap, we propose definitions of uncertainty and OOD for Actor-Critic RL algorithms, namely, proximal policy optimization (PPO), and present possible applicable measures. In particular, we discuss the concepts of value and policy uncertainty. The second point is addressed by implementing different uncertainty estimation methods and comparing them across a number of environments. The OOD detection performance is evaluated via a custom evaluation benchmark of in-distribution (ID) and OOD states for various RL environments. We identify a trade-off between reward and OOD detection performance. To overcome this, we formulate a Pareto optimization problem in which we simultaneously optimize for reward and OOD detection performance. We show experimentally that the recently proposed method of Masksembles strikes a favourable balance among the survey methods, enabling high-quality uncertainty estimation and OOD detection while matching the performance of original RL agents.