 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Adversarial Imitation Learning Using Causal Invariance
Paper and Code
Aug 17, 2023

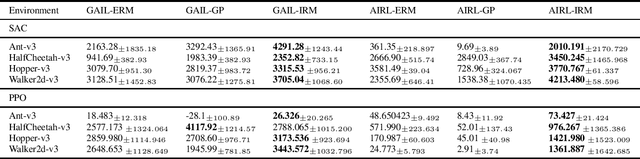
Imitation learning methods are used to infer a policy in a Markov decision process from a dataset of expert demonstrations by minimizing a divergence measure between the empirical state occupancy measures of the expert and the policy. The guiding signal to the policy is provided by the discriminator used as part of an versarial optimization procedure. We observe that this model is prone to absorbing spurious correlations present in the expert data. To alleviate this issue, we propose to use causal invariance as a regularization principle for adversarial training of these models. The regularization objective is applicable in a straightforward manner to existing adversarial imitation frameworks. We demonstrate the efficacy of the regularized formulation in an illustrative two-dimensional setting as well as a number of high-dimensional robot locomotion benchmark tasks.