 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComPO: Community Preferences for Language Model Personalization
Paper and Code
Oct 21, 2024

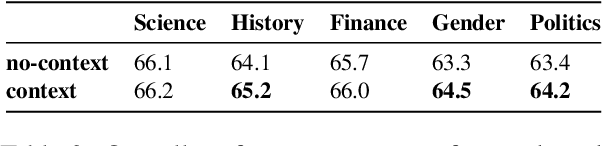

Conventional algorithms for training language models (LMs) with human feedback rely on preferences that are assumed to account for an "average" user, disregarding subjectivity and finer-grained variations. Recent studies have raised concerns that aggregating such diverse and often contradictory human feedback to finetune models results in generic models that generate outputs not preferred by many user groups, as they tend to average out styles and norms. To address this issue, we draw inspiration from recommendation systems and propose ComPO, a method to personalize preference optimization in LMs by contextualizing the probability distribution of model outputs with the preference provider. Focusing on group-level preferences rather than individuals, we collect and release ComPRed, a question answering dataset with community-level preferences from Reddit. This dataset facilitates studying diversity in preferences without incurring privacy concerns associated with individual feedback. Our experiments reveal that conditioning language models on a community identifier (i.e., subreddit name) during preference tuning substantially enhances model performance. Conversely, replacing this context with random subreddit identifiers significantly diminishes performance, highlighting the effectiveness of our approach in tailoring responses to communities' preferences.