 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkin Deep: Investigating Subjectivity in Skin Tone Annotations for Computer Vision Benchmark Datasets
May 15, 2023

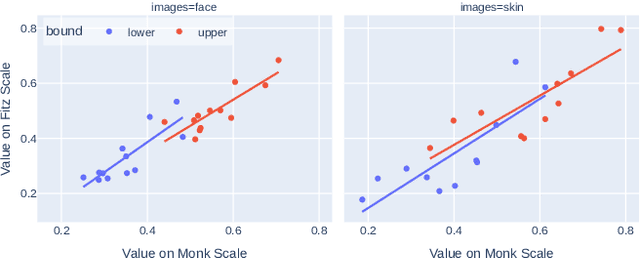
To investigate the well-observed racial disparities in computer vision systems that analyze images of humans, researchers have turned to skin tone as more objective annotation than race metadata for fairness performance evaluations. However, the current state of skin tone annotation procedures is highly varied. For instance, researchers use a range of untested scales and skin tone categories, have unclear annotation procedures, and provide inadequate analyses of uncertainty. In addition, little attention is paid to the positionality of the humans involved in the annotation process--both designers and annotators alike--and the historical and sociological context of skin tone in the United States. Our work is the first to investigate the skin tone annotation process as a sociotechnical project. We surveyed recent skin tone annotation procedures and conducted annotation experiments to examine how subjective understandings of skin tone are embedded in skin tone annotation procedures. Our systematic literature review revealed the uninterrogated association between skin tone and race and the limited effort to analyze annotator uncertainty in current procedures for skin tone annotation in computer vision evaluation. Our experiments demonstrated that design decisions in the annotation procedure such as the order in which the skin tone scale is presented or additional context in the image (i.e., presence of a face) significantly affected the resulting inter-annotator agreement and individual uncertainty of skin tone annotations. We call for greater reflexivity in the design, analysis, and documentation of procedures for evaluation using skin tone.
Evaluating Novel Mask-RCNN Architectures for Ear Mask Segmentation
Nov 05, 2022The human ear is generally universal, collectible, distinct, and permanent. Ear-based biometric recognition is a niche and recent approach that is being explored. For any ear-based biometric algorithm to perform well, ear detection and segmentation need to be accurately performed. While significant work has been done in existing literature for bounding boxes, a lack of approaches output a segmentation mask for ears. This paper trains and compares three newer models to the state-of-the-art MaskRCNN (ResNet 101 +FPN) model across four different datasets. The Average Precision (AP) scores reported show that the newer models outperform the state-of-the-art but no one model performs the best over multiple datasets.