 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBirbal: An efficient 7B instruct-model fine-tuned with curated datasets
Mar 04, 2024LLMOps incur significant costs due to hardware requirements, hindering their widespread accessibility. Additionally, a lack of transparency in model training methods and data contributes to the majority of models being non-reproducible. To tackle these challenges, the LLM Efficiency Challenge was introduced at NeurIPS Workshop, aiming to adapt foundation models on a diverse set of tasks via fine-tuning on a single GPU (RTX 4090 or A100 with 40GB) within a 24-hour timeframe. In this system description paper, we introduce Birbal, our Mistral-7B based winning model, fine-tuned on a single RTX 4090 for 16 hours. Birbal's success lies in curating high-quality instructions covering diverse tasks, resulting in a 35% performance improvement over second-best Qwen-14B based submission.
Nearest Neighbor Search over Vectorized Lexico-Syntactic Patterns for Relation Extraction from Financial Documents
Oct 26, 2023



Relation extraction (RE) has achieved remarkable progress with the help of pre-trained language models. However, existing RE models are usually incapable of handling two situations: implicit expressions and long-tail relation classes, caused by language complexity and data sparsity. Further, these approaches and models are largely inaccessible to users who don't have direct access to large language models (LLMs) and/or infrastructure for supervised training or fine-tuning. Rule-based systems also struggle with implicit expressions. Apart from this, Real world financial documents such as various 10-X reports (including 10-K, 10-Q, etc.) of publicly traded companies pose another challenge to rule-based systems in terms of longer and complex sentences. In this paper, we introduce a simple approach that consults training relations at test time through a nearest-neighbor search over dense vectors of lexico-syntactic patterns and provides a simple yet effective means to tackle the above issues. We evaluate our approach on REFinD and show that our method achieves state-of-the-art performance. We further show that it can provide a good start for human in the loop setup when a small number of annotations are available and it is also beneficial when domain experts can provide high quality patterns.
GPT-FinRE: In-context Learning for Financial Relation Extraction using Large Language Models
Jun 30, 2023
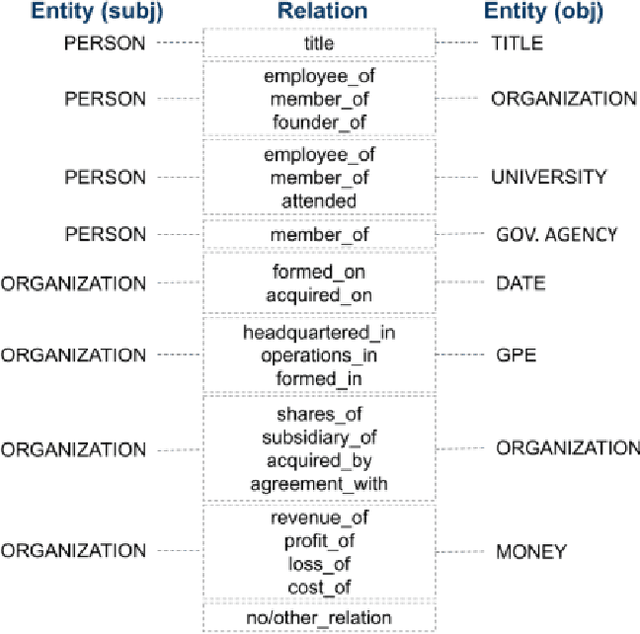
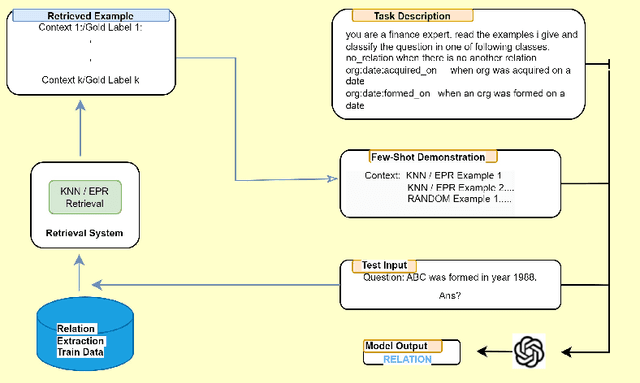
Relation extraction (RE) is a crucial task in natural language processing (NLP) that aims to identify and classify relationships between entities mentioned in text. In the financial domain, relation extraction plays a vital role in extracting valuable information from financial documents, such as news articles, earnings reports, and company filings. This paper describes our solution to relation extraction on one such dataset REFinD. The dataset was released along with shared task as a part of the Fourth Workshop on Knowledge Discovery from Unstructured Data in Financial Services, co-located with SIGIR 2023. In this paper, we employed OpenAI models under the framework of in-context learning (ICL). We utilized two retrieval strategies to find top K relevant in-context learning demonstrations / examples from training data for a given test example. The first retrieval mechanism, we employed, is a learning-free dense retriever and the other system is a learning-based retriever. We were able to achieve 4th rank on the leaderboard. Our best F1-score is 0.718.
TaTa: A Multilingual Table-to-Text Dataset for African Languages
Oct 31, 2022



Existing data-to-text generation datasets are mostly limited to English. To address this lack of data, we create Table-to-Text in African languages (TaTa), the first large multilingual table-to-text dataset with a focus on African languages. We created TaTa by transcribing figures and accompanying text in bilingual reports by the Demographic and Health Surveys Program, followed by professional translation to make the dataset fully parallel. TaTa includes 8,700 examples in nine languages including four African languages (Hausa, Igbo, Swahili, and Yor\`ub\'a) and a zero-shot test language (Russian). We additionally release screenshots of the original figures for future research on multilingual multi-modal approaches. Through an in-depth human evaluation, we show that TaTa is challenging for current models and that less than half the outputs from an mT5-XXL-based model are understandable and attributable to the source data. We further demonstrate that existing metrics perform poorly for TaTa and introduce learned metrics that achieve a high correlation with human judgments. We release all data and annotations at https://github.com/google-research/url-nlp.
Improving Compositional Generalization with Self-Training for Data-to-Text Generation
Oct 16, 2021
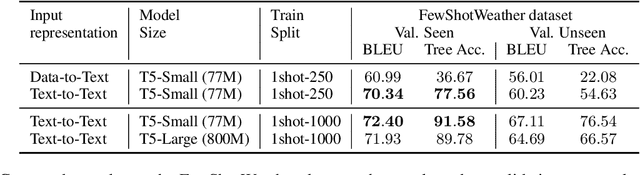


Data-to-text generation focuses on generating fluent natural language responses from structured semantic representations. Such representations are compositional, allowing for the combination of atomic meaning schemata in various ways to express the rich semantics in natural language. Recently, pretrained language models (LMs) have achieved impressive results on data-to-text tasks, though it remains unclear the extent to which these LMs generalize to new semantic representations. In this work, we systematically study the compositional generalization of current state-of-the-art generation models in data-to-text tasks. By simulating structural shifts in the compositional Weather dataset, we show that T5 models fail to generalize to unseen structures. Next, we show that template-based input representations greatly improve the model performance and model scale does not trivially solve the lack of generalization. To further improve the model's performance, we propose an approach based on self-training using finetuned BLEURT for pseudo-response selection. Extensive experiments on the few-shot Weather and multi-domain SGD datasets demonstrate strong gains of our method.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021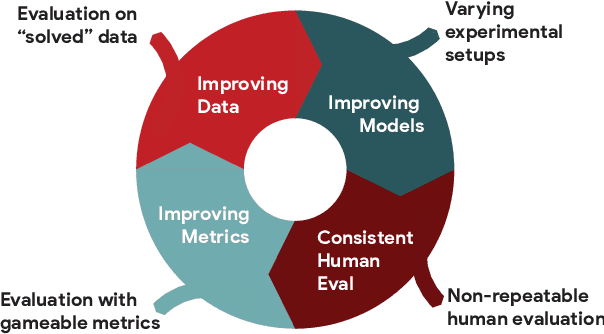
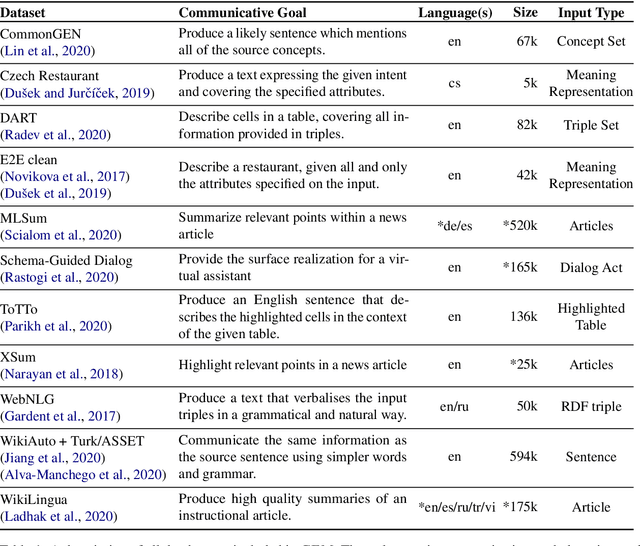
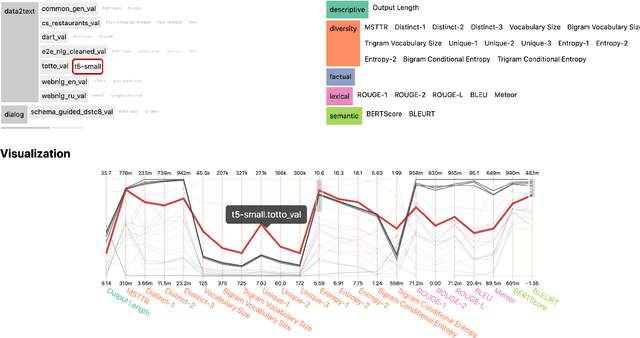
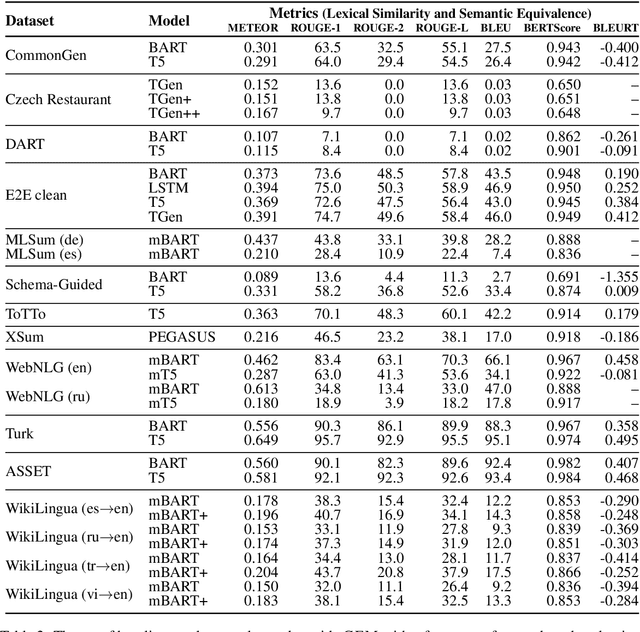
We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Handling Divergent Reference Texts when Evaluating Table-to-Text Generation
Jun 03, 2019


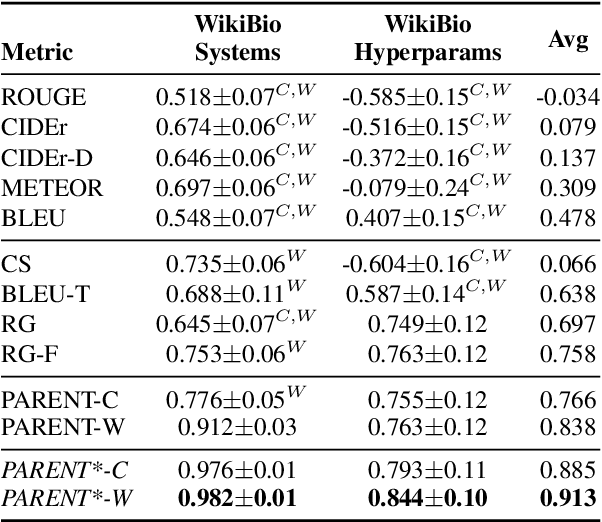
Automatically constructed datasets for generating text from semi-structured data (tables), such as WikiBio, often contain reference texts that diverge from the information in the corresponding semi-structured data. We show that metrics which rely solely on the reference texts, such as BLEU and ROUGE, show poor correlation with human judgments when those references diverge. We propose a new metric, PARENT, which aligns n-grams from the reference and generated texts to the semi-structured data before computing their precision and recall. Through a large scale human evaluation study of table-to-text models for WikiBio, we show that PARENT correlates with human judgments better than existing text generation metrics. We also adapt and evaluate the information extraction based evaluation proposed by Wiseman et al (2017), and show that PARENT has comparable correlation to it, while being easier to use. We show that PARENT is also applicable when the reference texts are elicited from humans using the data from the WebNLG challenge.
Improving Span-based Question Answering Systems with Coarsely Labeled Data
Nov 05, 2018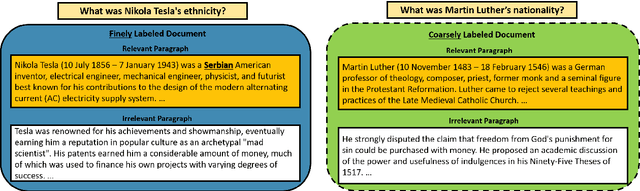
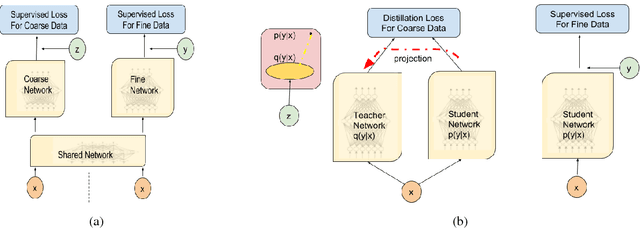
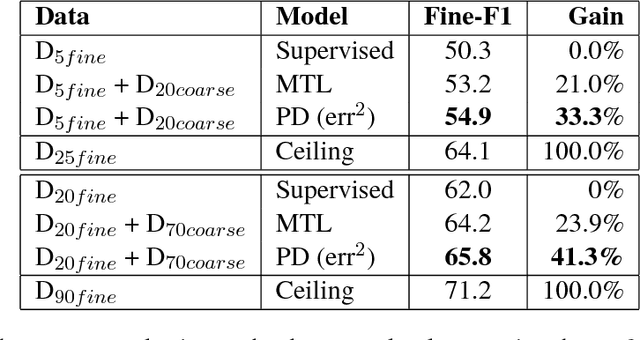
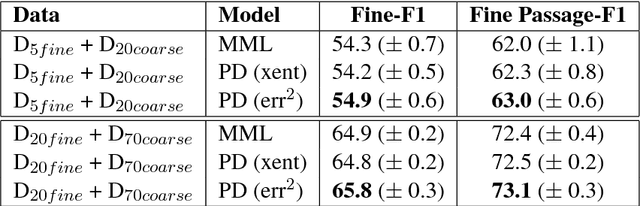
We study approaches to improve fine-grained short answer Question Answering models by integrating coarse-grained data annotated for paragraph-level relevance and show that coarsely annotated data can bring significant performance gains. Experiments demonstrate that the standard multi-task learning approach of sharing representations is not the most effective way to leverage coarse-grained annotations. Instead, we can explicitly model the latent fine-grained short answer variables and optimize the marginal log-likelihood directly or use a newly proposed \emph{posterior distillation} learning objective. Since these latent-variable methods have explicit access to the relationship between the fine and coarse tasks, they result in significantly larger improvements from coarse supervision.
Learning Recurrent Span Representations for Extractive Question Answering
Mar 17, 2017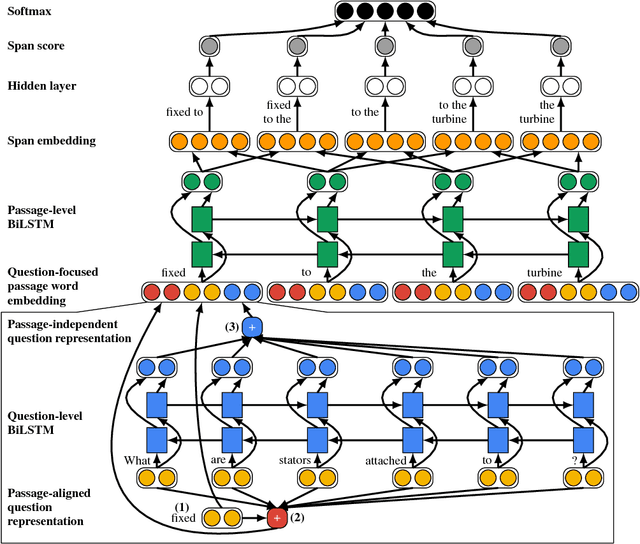
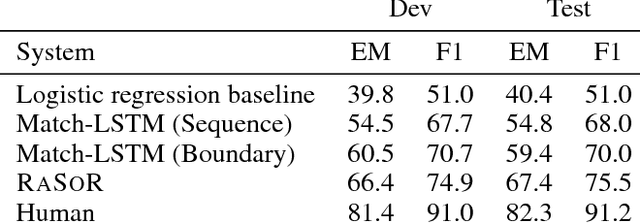

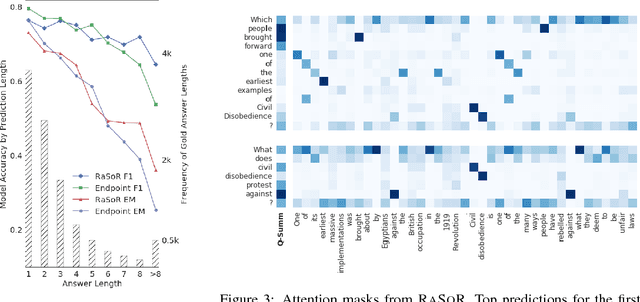
The reading comprehension task, that asks questions about a given evidence document, is a central problem in natural language understanding. Recent formulations of this task have typically focused on answer selection from a set of candidates pre-defined manually or through the use of an external NLP pipeline. However, Rajpurkar et al. (2016) recently released the SQuAD dataset in which the answers can be arbitrary strings from the supplied text. In this paper, we focus on this answer extraction task, presenting a novel model architecture that efficiently builds fixed length representations of all spans in the evidence document with a recurrent network. We show that scoring explicit span representations significantly improves performance over other approaches that factor the prediction into separate predictions about words or start and end markers. Our approach improves upon the best published results of Wang & Jiang (2016) by 5% and decreases the error of Rajpurkar et al.'s baseline by > 50%.
Nonparametric Latent Tree Graphical Models: Inference, Estimation, and Structure Learning
Jan 16, 2014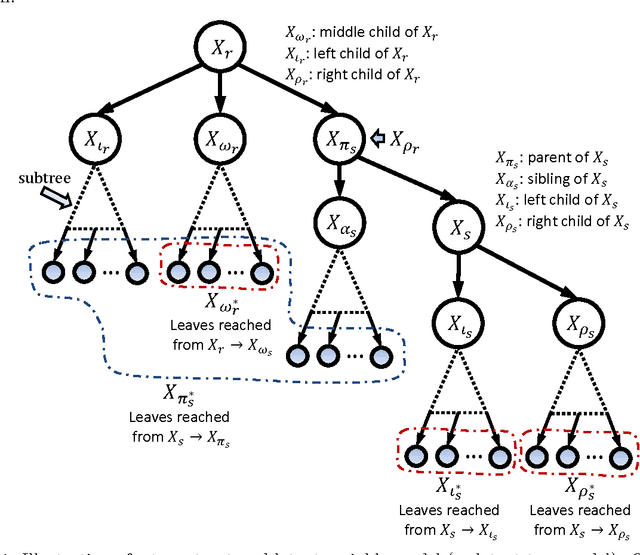
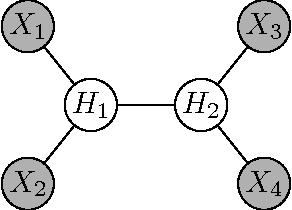
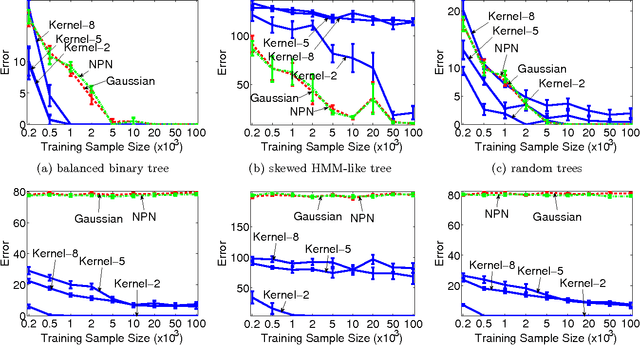
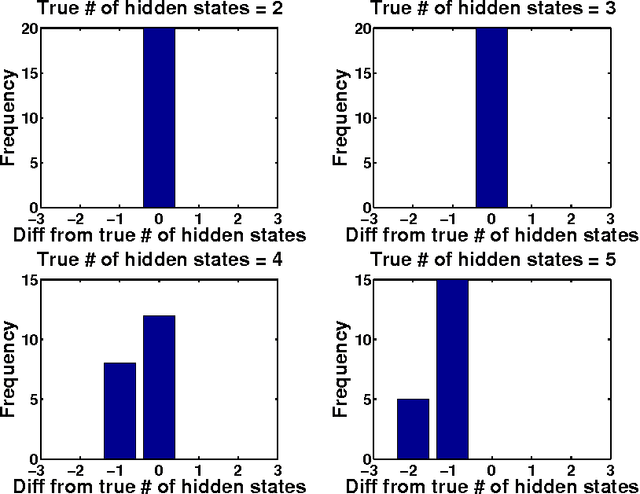
Tree structured graphical models are powerful at expressing long range or hierarchical dependency among many variables, and have been widely applied in different areas of computer science and statistics. However, existing methods for parameter estimation, inference, and structure learning mainly rely on the Gaussian or discrete assumptions, which are restrictive under many applications. In this paper, we propose new nonparametric methods based on reproducing kernel Hilbert space embeddings of distributions that can recover the latent tree structures, estimate the parameters, and perform inference for high dimensional continuous and non-Gaussian variables. The usefulness of the proposed methods are illustrated by thorough numerical results.