 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Compositional Generalization with Self-Training for Data-to-Text Generation
Oct 16, 2021
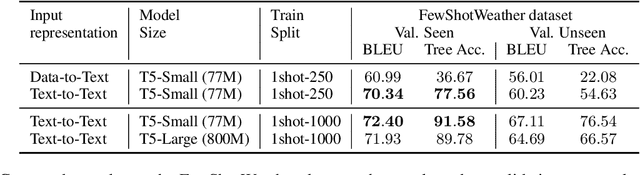


Data-to-text generation focuses on generating fluent natural language responses from structured semantic representations. Such representations are compositional, allowing for the combination of atomic meaning schemata in various ways to express the rich semantics in natural language. Recently, pretrained language models (LMs) have achieved impressive results on data-to-text tasks, though it remains unclear the extent to which these LMs generalize to new semantic representations. In this work, we systematically study the compositional generalization of current state-of-the-art generation models in data-to-text tasks. By simulating structural shifts in the compositional Weather dataset, we show that T5 models fail to generalize to unseen structures. Next, we show that template-based input representations greatly improve the model performance and model scale does not trivially solve the lack of generalization. To further improve the model's performance, we propose an approach based on self-training using finetuned BLEURT for pseudo-response selection. Extensive experiments on the few-shot Weather and multi-domain SGD datasets demonstrate strong gains of our method.